








内容为粤教版必修一《数据与计算》,仅供学习使用。
第一章 数据与信息
1、数据是现实世界客观事物的符号记录,是信息的载体,是计算机加工的对象。信息技术涵盖了获取、表示、传输、存储和加工信息在内的各种技术。
2 、在计算机科学中,数据是对所有输入计算机并被计算机识别、存储和处理的 符号的总称,是联系现实世界和计算机世界的途径。
3 、数据的特征: 二进制、语义性、分散性、多样性与感知性
二进制与十进制互相转换 :
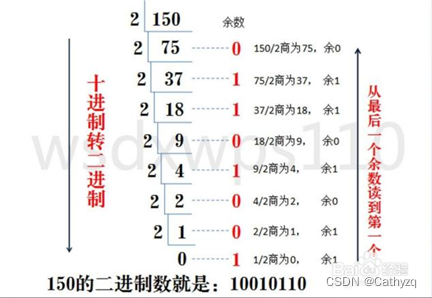
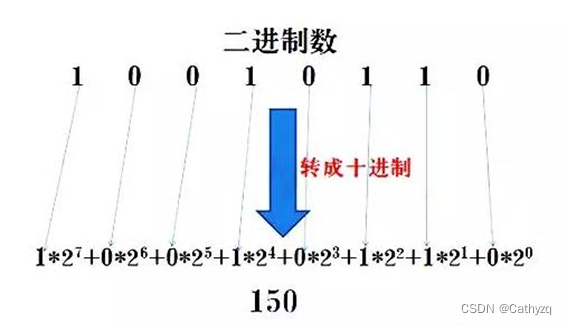
八进制、十六进制与十进制转换方法与二进制转换十进制类同 。
八进制与二进制转换,以三位二进制位数为单位转换,不足的位数补0:
100,101 = 45 23 = 010,011
十六进制与二进制转换,以四位二进制位数为单位转换,不足的位数补0:(10,11,12,13,14,15对应A,B,C,D,E,F)
1001,1100 = 9C 8D = 0100,1101
4 、模拟信号是指用连续变化的物理量所表达的信息。其信号的幅度、频率或相位随时间作连续变化,是传到能量的一种形式,在时间和大小上是连续的,如声音信号、图形信号等。
5 、数字信号是离散时间信号的数字化表示。其信号的自变量、因变量都是离散的。
6 、在计算机中,数字信号的大小常用有限位的二进制数表示。
7 、数字信号的优点: 抵抗电路本身干扰和环境干扰的能力强,利于存储、加密与纠错,从而具有较强的保密性和可靠性。
8 、在现代技术的信号处理中,数据基本上是通过编码将模拟信号转换为数字信号进行存储和传输,文字、图像、声音等类型的数据都可经过编码进行存储和传输。
9、文字(字符) 编码是效率相对较低的编码方式,有单字节码和双字节码两种。
ASCII 码、莫尔斯码属于单字节码,国标码(GBK)、统一码(Unicode ) 属于双字节码。
10、ASCII 码是美国信息交换标准代码,用 8 位二进制码为所有的英文字母(大 小写 52 个)、阿拉伯数字( 10 个) 和常用的不可见控制符(33 个) 以及标点符 号、运算符号等(33 个) 建立了转换码,将符号转换为“0”和“1”构成的编码。英 文字母 A 和 a 的编码分别为 01000001 (十进制数 65)和 01100001 (十进制数 97)。
ASCII码的大小规则: 数字< 大写字母 < 小写字母
数字 0 的编码为00110000(十进制48)
字母 A 为01000001 (十进制数65)
字母 a 的编码为01100001 (十进制数97)同个字母的大写字母比小写字母要小32。
例如:
- ASCII 码使用指定的8位(或7位)二进制数组合来表示128种可能的字符(8位的ASCII编码,首位都是0)。
- 英文字母A的ASII码为01000001,转化为十进制(序号)后是多少?65=26+20
- 7位二进制可表示(0000000-1111111)128种编码。(128=27)
编码容量 = 2 编码的二进制位数
11、汉字编码使用的是简体中文的 GB2312 码 、GBK码和繁体中文的 BIG5 码(大五码)。
12 、图像编码是指在满足一定保真度的条件下,对图像数据进行变换、编码和压 缩,以较少比特数表示图像或图像中所包含的信息的技术。
13、位图,最小单位为光栅点(或称像素),因而位图也叫作点阵图(或像素图)。
14 、在计算机二进制数系统中,每个 0 或 1 就是一个位(bit ,数据存储的最小单位),8 个位就称为一个字节(Byte),即1 B= 8 b 。
存储容量(文件大小)单位。bit—B—KB—MB—GB—TB;1B(字节)=8位
1KB=1024B 1MB=1024KB 1GB=1024MB 1TB=1024GB
15 、位图文件所占用的空间可按以下公式计算:
文件的大小=文件头+信息头+颜色表项+ (图像分辨率*图像量化位数/8)
(1)文件头: 包含文件的类型、大小和位图起始位置等信息,共 14 个字节(B)。
(2)位图信息头: 用于说明位图的尺寸等信息, 占 40 个字节(B)。
(3)颜色表项: 用于说明位图中的颜色,有若干个表项,每一个表项定义一种 颜色。当图像量化位数为 1 、4 、8 时,分别有 2 、16 、256 种颜色,每个颜色表 项占 4 个字节; 当图像量化位数为 24 时,没有颜色表项。
(4)图像分辨率= 图像 x 方向的像素数*图像 y 方向的像素数。
(5)图像量化位数: 黑白图像,每一个像素有 2 种可选颜色(黑、白),称为 1 位图像。16 色图像,每一个像素有 16 种可选颜色,称为 4 位图像(24=16);
256 色图像称为 8 位图像(28=256);24 位图像的可选颜色更丰富,为 224 种。
16 、声音编码: 对声音进行数据编码,必须经过数据的采样、量化和编码。声音的质量取决于采样频率和量化位数。采样频率越高,量化的分辨率越高,所得声音的保真程度也越好,但数据量会越大。常见的声音格式有:MP3、WAV、MID、WMA等。
17 、根据奈奎斯特采样定理,如果以一定时间间隔对某个信号f(t)进行采样, 并且采样频率高于该信号最高频率的两倍,则采样值包含了原信号的全部信息。 对于音频信号,常用的采样频率有三种: 44.1kHz、22.05kHz 和 11.025kHz。
18、量化是把样值信号的无限多个可能的取值,近似地用有限个数的数值来表示。声音的量化位数越多,可表示的声音等级(个数)越多。
19 、编码是将量化后的采样值用二进制数码表示,并转换为由二进制编码 0 和 1 组成的数字信号。
20 、声音存储空间遵循如下公式:
声音存储空间=采样频率*量化位数*声道数*时间/8(其中立体声声道数为 2)
例题: 采样频率为 44. 1kHz、量化位数为 16 位的立体声,1 秒声音所需字节 数为: 44.1*1000*16*2*1/8=176400 (B)。
21、信息是经过加工处理的、具有意义的数据。信息是对客观世界中各种事物的 运动状态和变化的反映,是客观事物之间相互联系和相互作用的表征。
22 、信息的特征: 普遍性、传递性、共享性、依附性和可处理性、时效性、真伪 性、价值相对性。
第 2 章 知识与数字化学习
1 、数字化学习工具: Python 、思维导图、网络画板。
2 、认识自然、探究规律的方法: 做实验→获取观察数据→分析处理数据→推理 建立数学模型→实验验证模型→形成知识→应用知识解决问题。
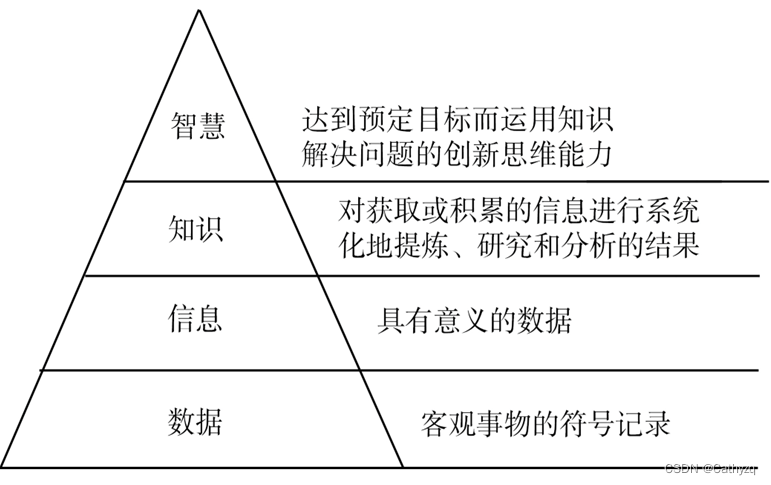
3、知识:知识是人们运用大脑对获取或积累的信息进行系统化的提炼、研究和分析的结果,能够精确的反应事物的本质。
数据是现实世界客观事物的符号记录;信息是经过加工处理的、具有意义的数据;知识是人们运用大脑对获取或积累的信息进行系统化的提炼、研究和分析的结果,能够精确的反应事物的本质;智慧是为了达到预定目标而运用知识解决问题的创新思维能力。
数据、信息、知识、智慧是逐渐递进的关系,前者是后者的基础和前提,后者是前者的抽象和升华。
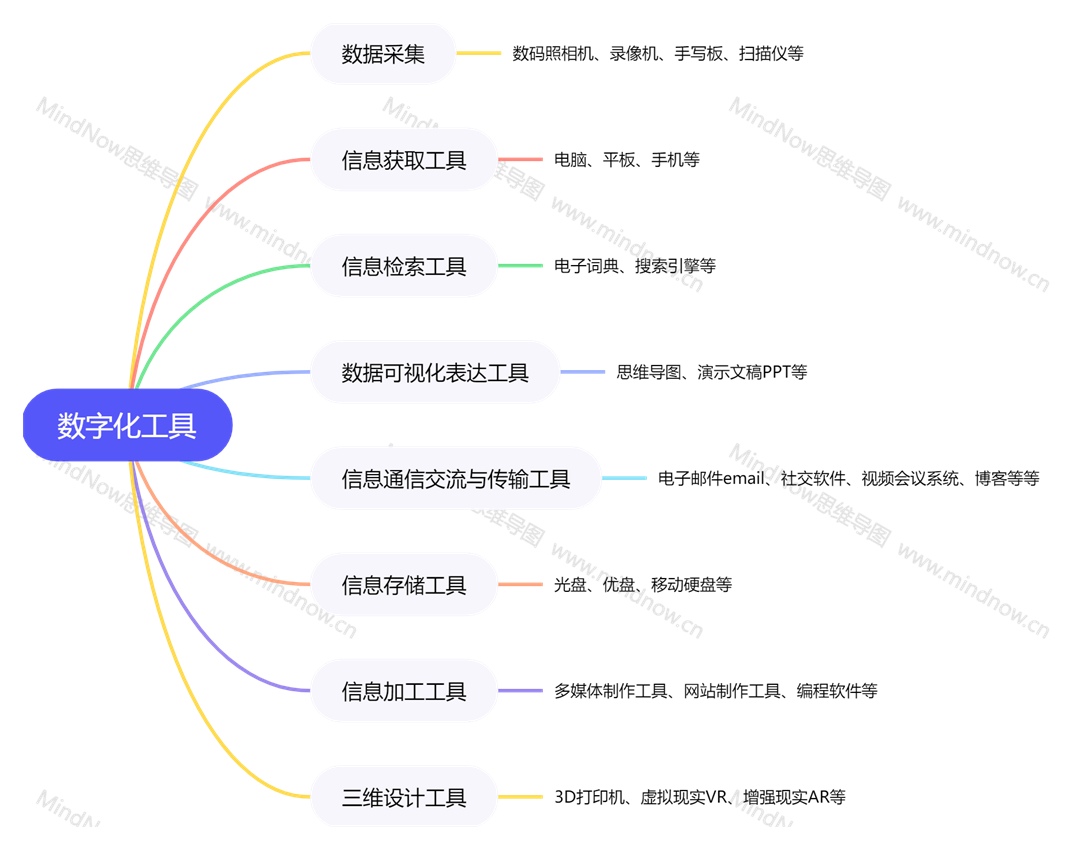
4 、数字化工具与资源
数字化工具是指能够采集、获取、检索、表示、传输、存储和加工多媒体数 字化资源的设备装置。按其功能不同,数字化工具可大致分为以下几种 ∶
5 、数字化工具与资源的优势
- 获取的便捷性。
- 形式的多样性。
- 资源的共享性。
- 平台的互动性。
- 内容的扩展性
6 、数字化学习的特点
数字化学习是伴随计算机多媒体技术、互联网通信技术的发展而产生的,是信息社会的重要特征。与传统的学习方式不同,数字化学习具有问题化、合作性、 个性化、创造性和再生性、开放性等特点。
第三章 算法基础
1 、编写计算机程序解决问题要经过分析问题、设计算法、编写程序、调试运行 程序等若干个步骤。
2 、算法是指在有限步骤内求解某一问题所使用的一组定义明确的规则。通俗地说,算法就是用计算机求解某一问题的方法,是能被机械地执行的动作或指令的有穷集合。
3、算法的特征: 有穷性 、 确定性 、 数据输入 、 数据输出 、 可行性。
- 有穷性。一个算法在执行有穷步之后必须结束,即一个算法所包含的 计算步骤是有限的。
- 确定性。算法执行的每一个步骤必须有确切的定义,不能出现模棱两 可的情况。
- 数据输入。一个算法必须有零个或多个数据输入,以刻画运算对象的 初始情况。例如,在上面的算法中,就没有数据输入。
- 数据输出。一个算法有一个或多个数据输出,以反映对输入数据加工 后的结果,没有输出的算法是毫无意义的。
- 可行性。算法中执行的任何计算步骤都可以被分解为基本的可执行的 操作步骤,即每个计算步骤都可以在有限时间内完成。
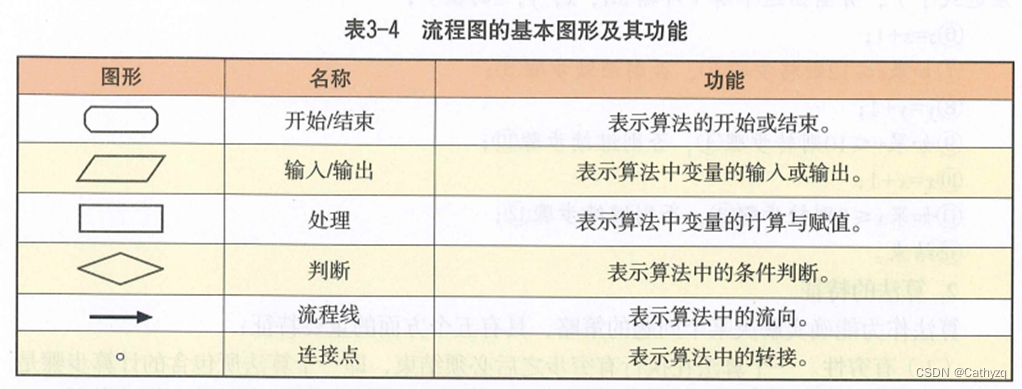
4 、描述算法的常用方法有自然语言描述算法、流程图描述算法和伪代码描述算法。
-
用自然语言描述算法,就是用人们日常所用的语言,如汉语、英语等来描述算法。
-
用流程图描述算法是用程序框图来描述算法的一种表示方法。
-
用伪代码描述算法就是用介于自然语言和计算机语言之间的文字和符号来描 述算法。它不用图形符号,书写方便,格式紧凑,易于理解,便于向计算机程序 设计语言过渡。
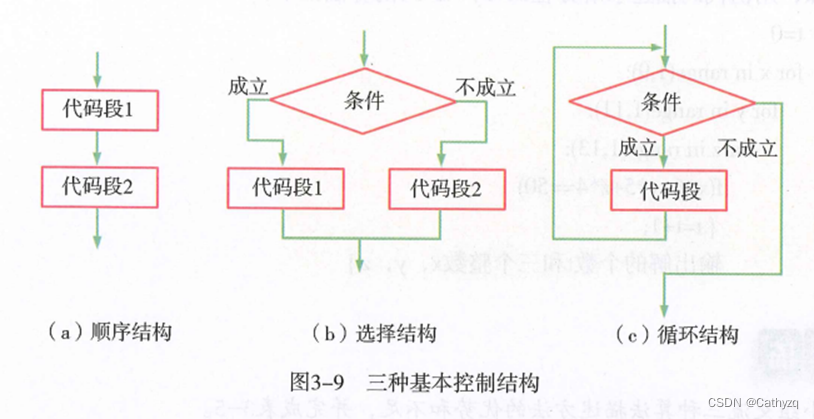
5 、三种基本控制结构: 顺序结构、选择结构和循环结构
6 、计算机程序是指为了得到某种结果而可以由计算机等具有信息处理能力的装置执行的代码化指令序列,或者可被自动转换成代码化指令序列的符号化指令序 列或者符号化语句序列。简而言之,计算机程序就是指计算机可以识别运行的指令集合。
7、计算机主要包括运算器、控制器、存储器、输入设备和输出设备五大基本部件。计算机内部采用二进制形式表示和存储指令或数据,把解决问题的程序和需要加工处理的原始数据是先转换成二进制数,并存入存储器中。
8、计算机程序设计语言,是指一组用来定义计算机程序的语法规则,通常简称为“编程语言” 。它是一种被标准化的交流技巧,用于向计算机发出指令。
9、计算机程序设计语言的发展,经历了从机器语言、汇编语言到高级语言的发展历程。
- 机器语言:由0和1组成的二进制代码,由计算机直接识别,是第一代编程语言,也是编程的低级语言。
- 汇编语言:不能被计算机直接识别,介于机器语言和高级语言之间。
- 高级语言:不能被计算机直接识别和执行,必须经过编译程序或解释程序将其翻译成机器语言。例如:VB、Python、C、C++等。 高级语言的翻译程序有两种类型: 编译程序和解释程序。
第 4 章 程序设计基础
基础知识可参考之前的博客文章。
1 、常量是指在程序运行过程中其值始终不发生变化的量,通常是固定的数值或字符串。
2 、变量是指在程序运行过程中其值可以发生变化的量。在程序设计语言中,变量可以用指定的名字来代表,即变量由变量的"标识符"(又称"名字")和变量的 “内容” (又称"值")两部分组成。
Python 程序设计语言规定标识符规则:
(1)由字母(A~Z ,a~z)、数字(0~9)、下划线组成;
(2)尽量不要与系统函数、关键词等名字冲突,例如len、print、False不要使用
(3)第一个字符必须是字母或下划线,而不能是数字,如 s1 ,k ,num , pai等。
(4)在标识符中,字母大小写是有区别的,如"value"与"Value"是两个不同的标识符。
(5)尽量按照英文命名,例如姓名使用name而不是xingming
Python变量的赋值及其使用
(1)Python中定义变量时不用申明数据类型,变量的数据类型由值来决定;
(2)变量必须要赋值后才能使用,没有赋值的变量是没有被创建的;
python是动态语言,定义变量时无须声明数据类型,且数据类型可以改变。
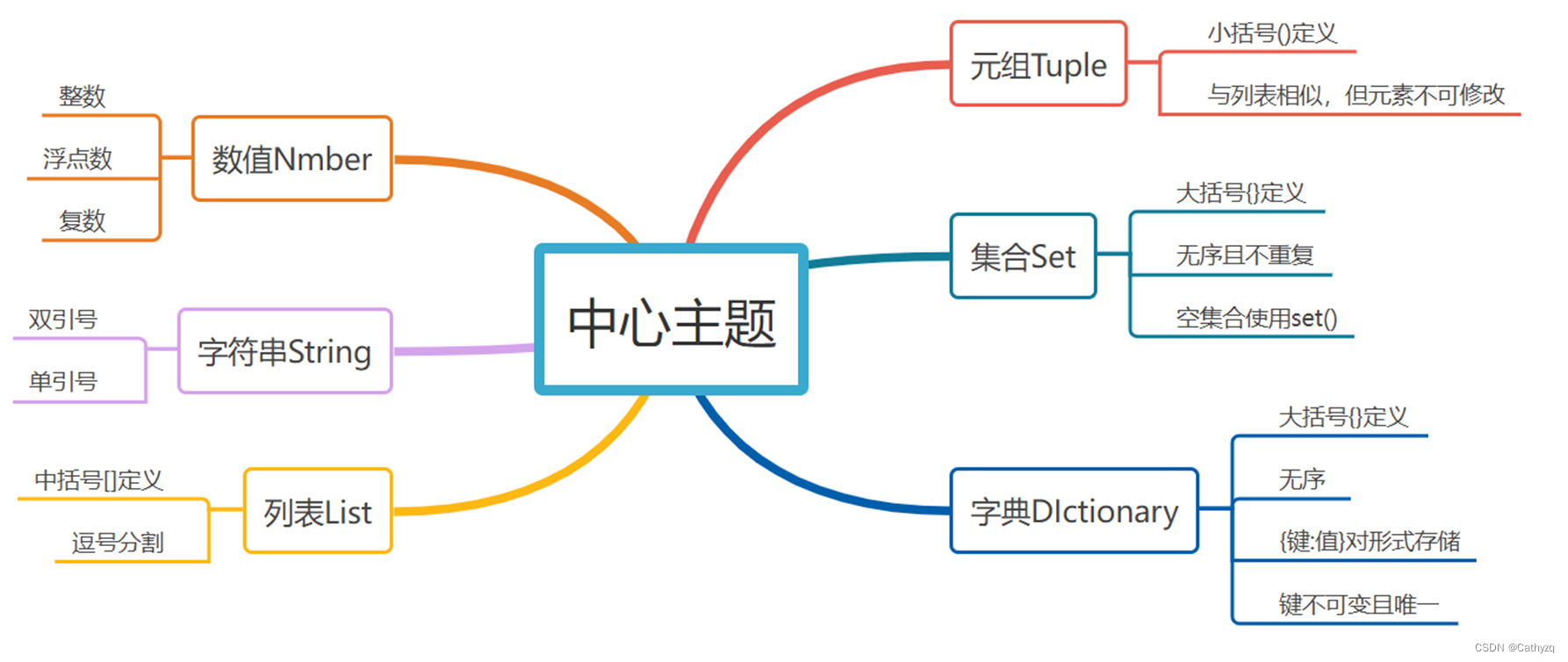
3、 Python数据类型:数值、字符串、列表、元组、集合、字典。
- 【数值】整型(int)、浮点型(float)、复数(complex)
a = 4
b =3.14159
c = 1 + 2j
d = complex(1,2)
- 【字符串】以单引号或双引号括起来的任意文本。
字符串是以单引号或双引号括起来的文本,如‘abc’、"xyz"等。
a = "hello"
b = 'world'
包含单引号的字符串,如I’m a student。
str1 = 'I'm a student.' # 错误,会将I后面的单引号看作返回单引号
# 在字符串里面存在单引号时,使用转义字符\,表示将\后的字符看着普通字符。
str2 = 'I\'m a student.'
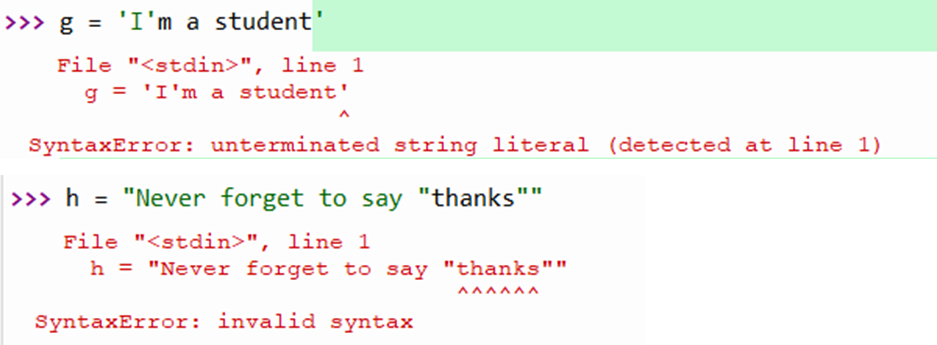
包含双引号的字符串,如Never forget to say “thanks”。
str1 = "Never forget to say "thanks"" # 错误,会将thanks前面的双引号看作返回双引号
# 在字符串里面存在双引号时,使用转义字符\,表示将\后的字符看着普通字符。
str2 = "Never forget to say \"thanks\""
字符串的访问,使用索引,索引从0开始,0代表第一个, -1代表尾部最后一个

>>> a = "hello"
>>> a[0]
'h'
>>> a[-1]
'o'
>>> a[5] #索引越界了
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: string index out of range
>>>
字符串的运算:
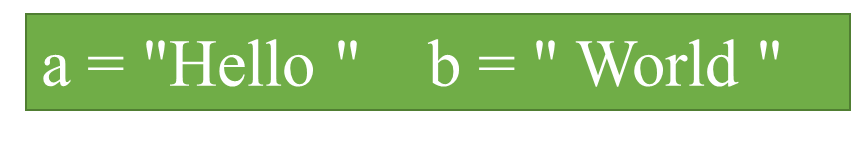
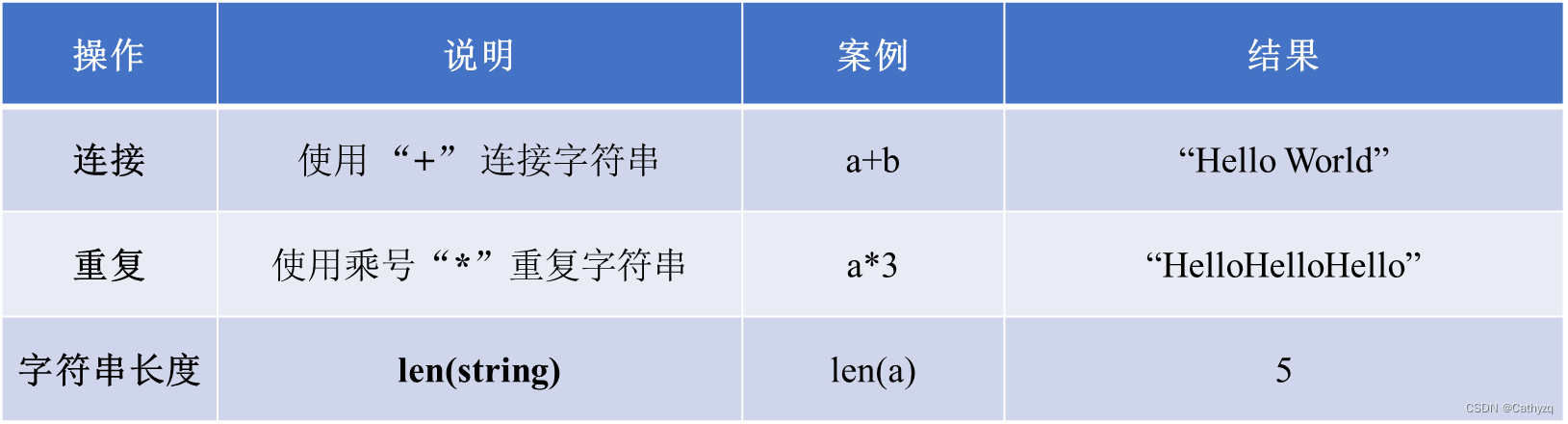
-
【列表】写在“[ ]”之间、用逗号隔开的元素列表,列表的数据项不需要具有相同的类型,与字符串的索引一样,列表索引从0开始。
列表运算

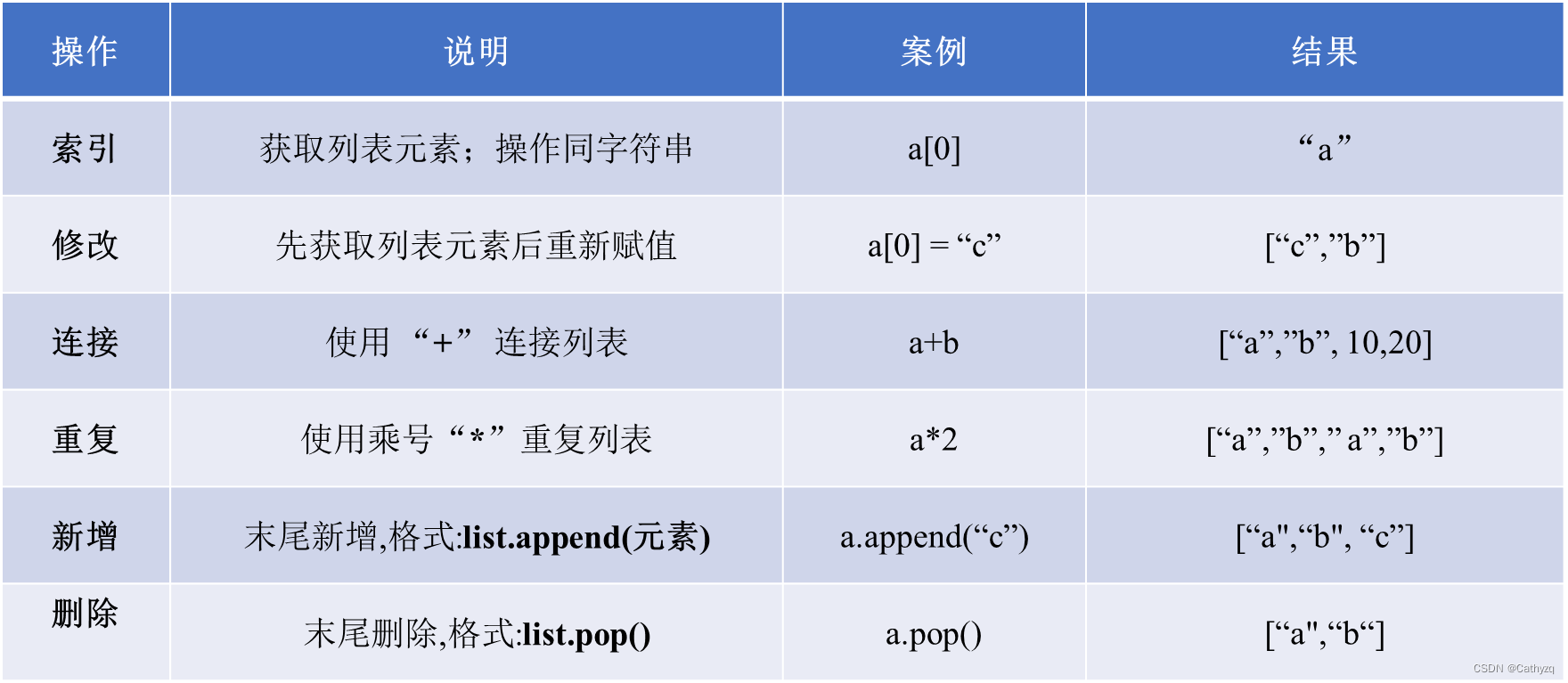
-
【元组】元组与列表相似,不同之处在于元组列表不能修改。元组使用小括号,元素之间用逗号隔开。

元组运算

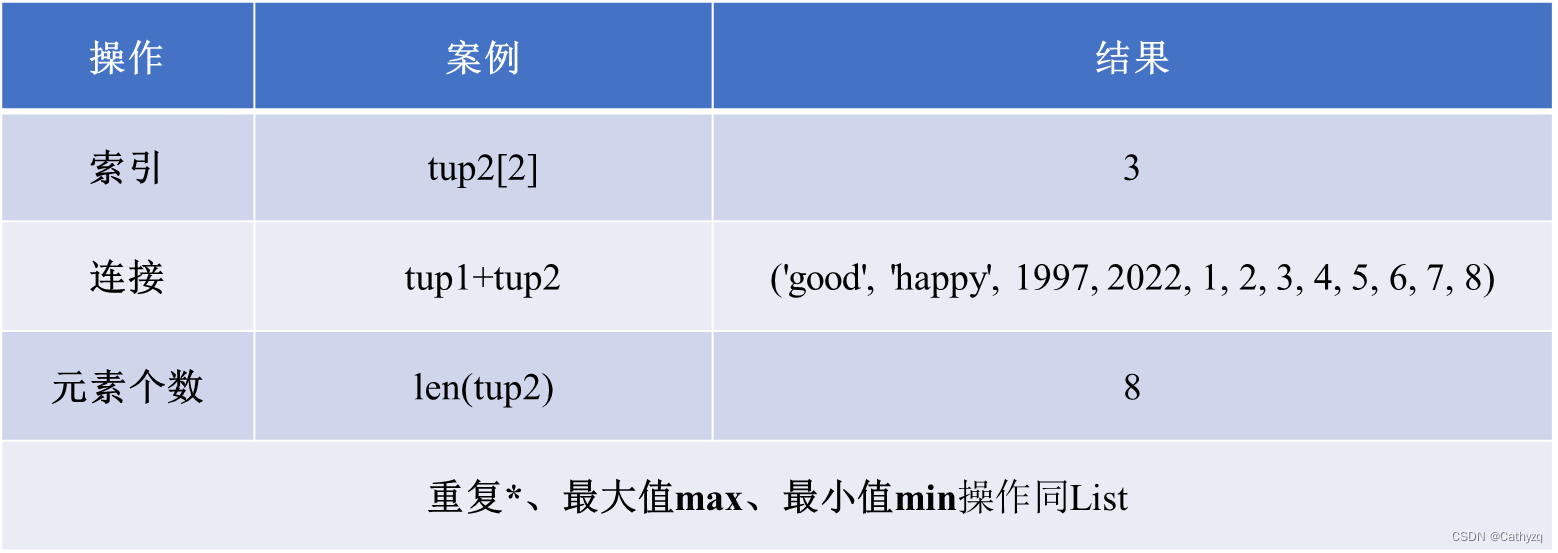
-
【集合】是一个无序不重复序列。基本功能是进行成员关系测试和删除重复元素。使用大括号或者set()函数创建集合。
创建一个空集合必须用 set() 而不是 { }。因为 { } 是用来创建一个空字典。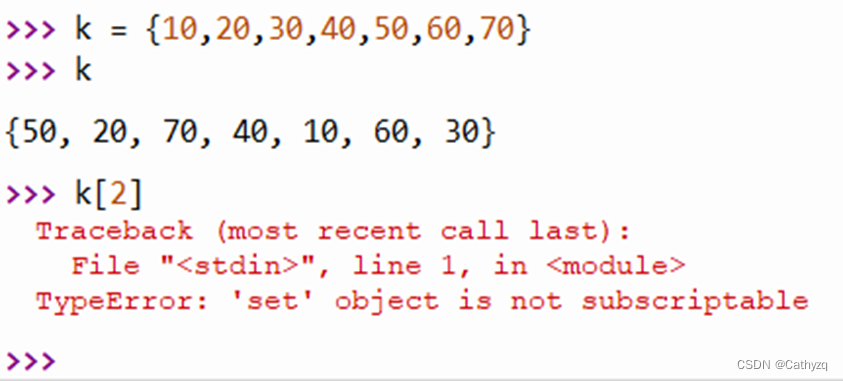
取值:集合是不能通过下标索引来取值和赋值的。

-
【字典】字典是无序的对象集合。

字典运算

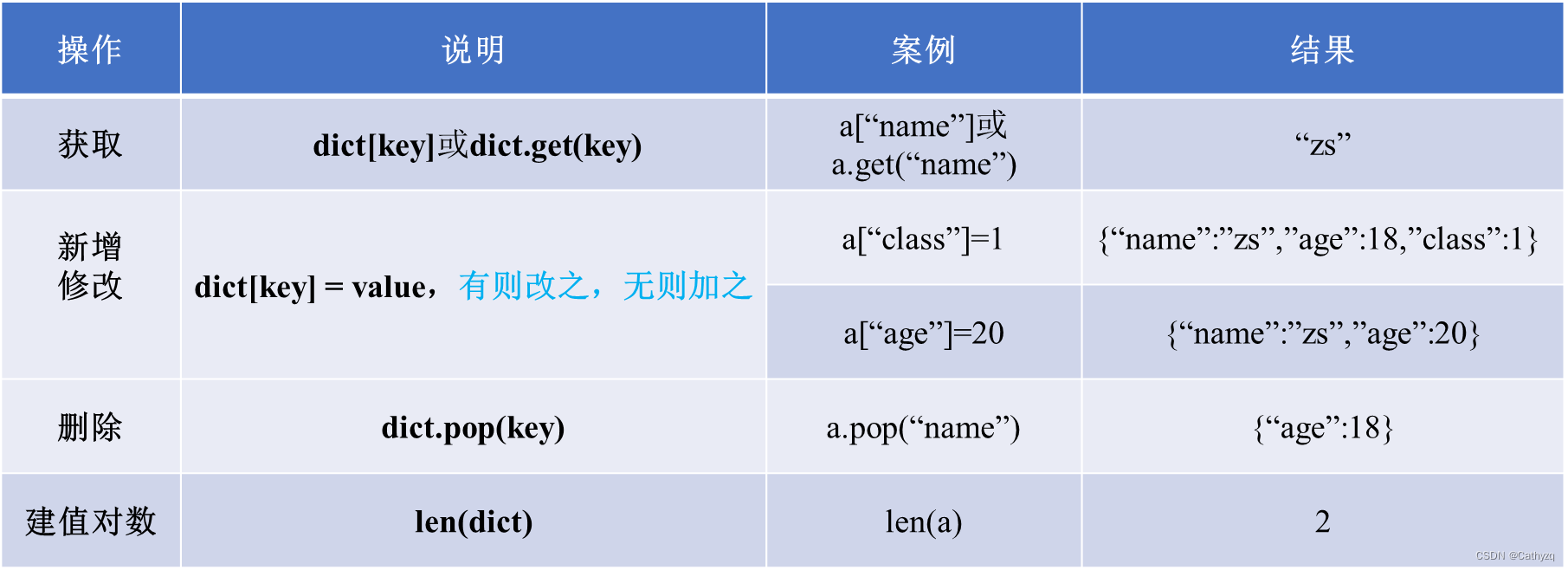
数据类型的总结
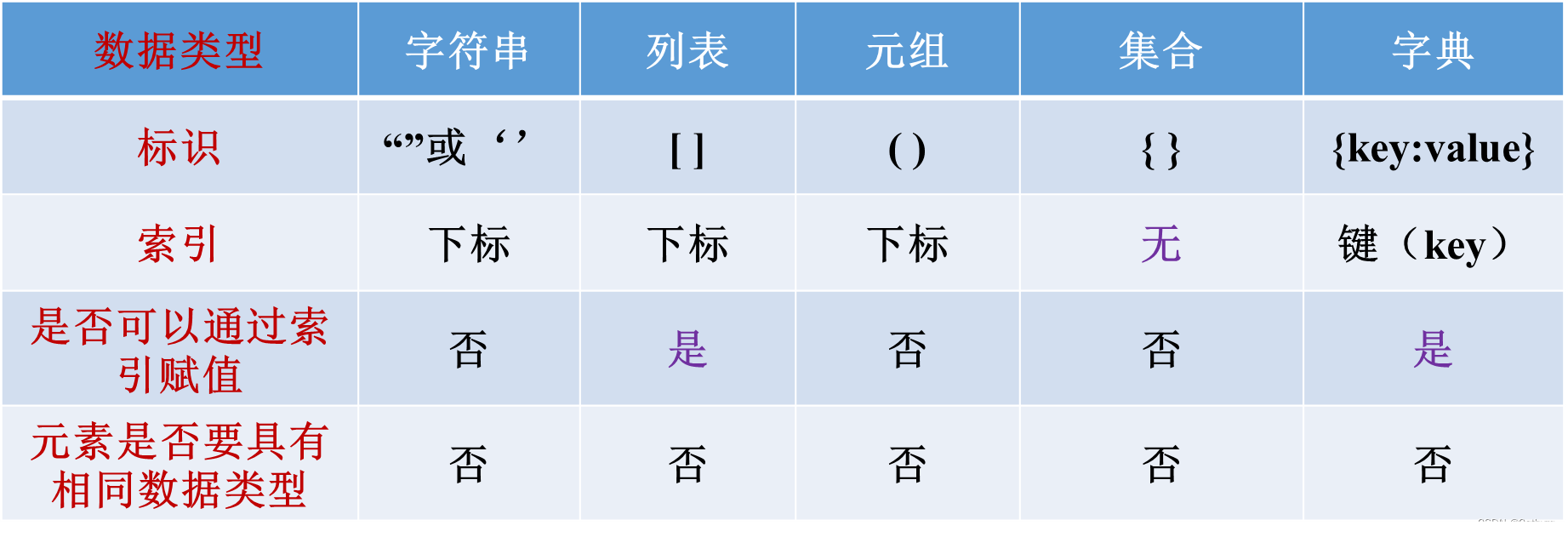
4 、算术运算符与算术表达式
算术运算符包括“+”“- ”“*”“/”“%”“**”和“/”, 分别表示加、减、乘、 除、求余、幂运算和整除。
>>> a =10
>>> b =5
>>> a+b # 加法
15
>>> a-b # 减法
5
>>> a*b # 乘法
50
>>> a/b # 除法
2.0
>>> a//b # 整除
2
>>> -b # 负数
-5
>>> a%b #求余数
0
>>> a**b #幂次方
100000
>>>
- 逻辑运算符与逻辑表达式
逻辑运算符包括"and"(与)、“or”(或)、“not”"(非) 共三个。由逻辑运算符连接而成的表达式称为逻辑表达式。逻辑表达式的值为 True 或 False。

>>> a =0
>>> b =1
>>> c =2
>>> a and b
0
>>> b and c
2
>>> c and b
1
>>> a or b
1
>>> c or b
2
>>> not a
True
>>> not(a and b)
True
>>>
6 、关系运算符与关系表达式
判断数据大小关系的运算符称为关系运算符,关系运算符有">“(大于) 、”>=" (大于等于) 、“<”(小于) 、“<=”(小于等于) 、“==”(等于) 、“!=”(不等于)。
关系表达式的值为逻辑值True 或者 False。
A = 1
B = 2
print(A>=B) # False
print(A!=B) # True
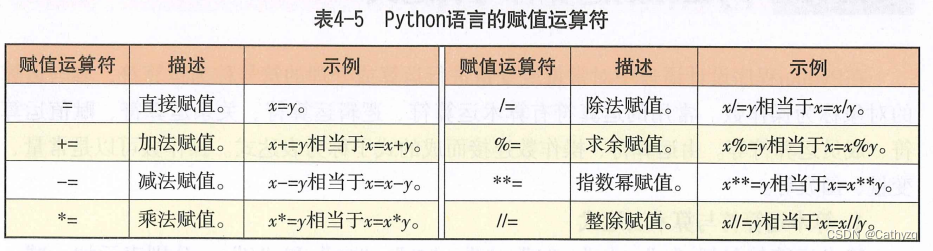
7 、 赋值运算符与赋值表达式
在 Python 中对变量的赋值通过赋值运算符"="来完成。
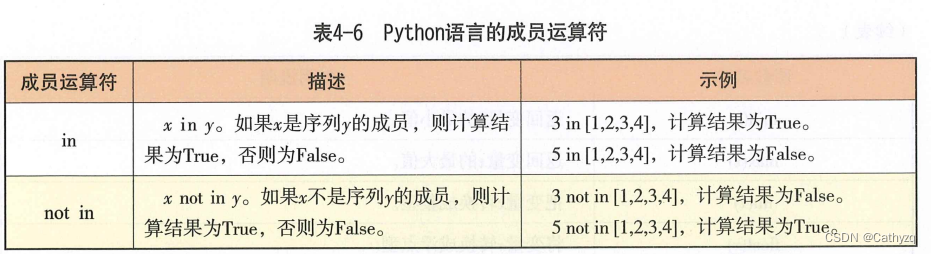
8 、成员运算符
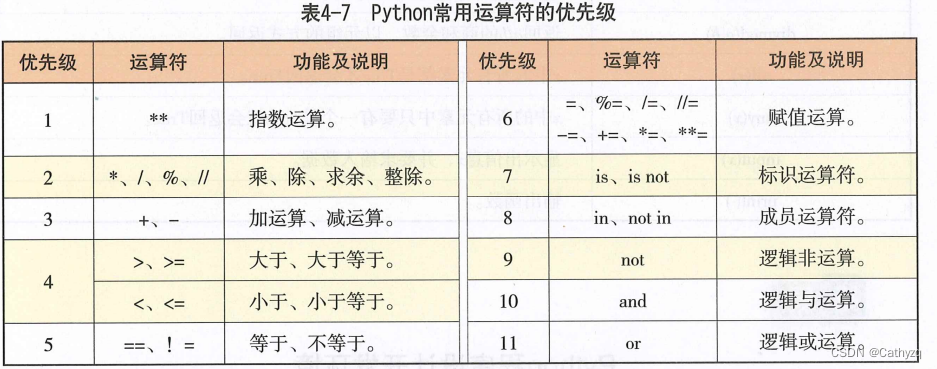
9 、运算符的优先级
10 、Python 的函数

11 、数据的输入格式为 ∶<变量>=input( '提示信息 ∶')
12 、数据的输出格式为 ∶ print( [object, …] [, sep=’’][,end=’\n’]) 说明 ∶
- 方括号中的项是可选的,可以省略,如省略则取系统的默认值。
- object 是要输出的对象,可以是常量、变量或表达式等。
- sep 后面的空格(可以指定为其他字符) 表示每个输出对象之间的分隔符, 如果缺省的话,默认值是一个单个的空格。例如,“
print(4 ,5 ,6 ,sep=***)” ,则输出结果为"4**5**6"。 - end 后面的字符串含义为输出文本尾的一个字符串,如果缺省的话,默认 值是一个\n 换行符。如果设为其他字符,如 end=’ ’ ,则输出当前行的所有内容 后,在末尾加一个空格,不换行接着输出下一个 print() 的输出对象。
例如,print( )输出示例程序如下 ∶
print("hello"end='')
print("world")
# 输出为"hello world"
(5)print () 函数支持参数格式化,与 C 语言的 printf 类似。
例如:>>> print("the length of (%s) is %d" %('runoob',len('runoob'))
the length of (runoob) is 6
关于python中的三种基本结构的内容稍后会有专门的博客详细介绍,这里先不做整理。
第 5 章 数据处理与可视化表达
1 、数据是指无法在可承受的时间范围内用常规软件工具进行高效捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
2 、大数据的产生是与人类日益普及的网络行为所伴生的。物联网、云计算、移 动互联网、车联网、手机、电脑以及遍布地球各个角落的各种各样的传感器,无 一不是数据的来源或是承载的方式。
3 、大数据的特征:
- 从互联网产生大数据的角度来看,大数据具有“4V”特征: 大量(Volume)、多样(Variety)、低价值密度(Value)、高速(Velocity)。
- 从互联网思维的角度来看,大数据具有三个特征: 样本渐趋于总体,精确让位于模糊,相关性重于因果。
- 从大数据存储与计算的角度来看,大数据具有两个特征: 分布式存储和分布式并行计算。
4 、传统数据与大数据的区别
| 传统数据 | 大数据 |
|---|---|
| 数据量小 | 数据体量巨大 |
| 数据类型少 | 数据类型繁多 |
| 价值密度高 | 价值密度低 |
| 更新速度慢 | 更新速度快 |
| 追求数据精确性 | 追求数据模糊性性 |
| 本地存储 | 分布式存储 |
5 、大数据使人们日常生活更为便捷: 方便支付、方便出行、方便购物与产品推 介、方便看病与诊病。
6 、大数据对人们日常生活产生的负面影响: 个人信息泄露、信息伤害与诈骗。
7 、数据采集的基本方法包括系统日志采集法、网络数据采集法和其他数据采集法。
8 、在信息系统中,系统日志是记录系统中硬件、软件和系统问题的信息文件。
9 、网络数据采集是指通过网络爬虫或网站公开 API(应用程序接口) 等方式从网站上获取数据信息。
10、存储数据主要有两种方式,一种是把数据存在本地内部,另一种是把数据放在第三方公共或私有的“云端”存储。
11、数据安全保护技术。数据安全保护指数据不被破坏、更改、泄露或丢失。安装杀毒软件和防火墙只能防备数据安全隐患,而采用拷贝、备份、复制、镜像、 持续备份等技术进行数据保护才是更为彻底、有效的方法。
12、解决隐私泄露问题有三个办法: 一是技术手段,常用的隐私保护有: ①数据收集时进行数据精度处理; ②数据共享时进行访问控制; ③数据发布时进行人 工加扰; ④数据分析时进行数据匿名处理等。二是提高自身的保护意识。三是要对数据使用者进行道德和法律上的约束。
12 、数据分析一般包括特征探索、关联分析、聚类与分类、建立模型和模型评价 等。
- 特征探索: 对数据进行预处理,发现和处理缺失值,异常数据、绘制直方 图,观察数据分布的特征,求最大值、最小值、极差等描述性统计量。
- 关联分析: 分析发现存在于大量数据之间的关联性和相关性,从而描述一 个事物的共同规律和模式。
- 聚类分析: 是一种探索性的分析。不必事先给出一个分类标准,而是让其 自动分类。
- 数据分类: 是数据分析中最基本的方法。先基于样本数据构建分类器,然 后进行预测。
第 6 章 人工智能及其应用
1 、人工智能是研究计算机模拟人的某些感知能力、思维过程和智能行为(如学 习、推理、思考、规划等) 的学科。
2 、智能问答系统主要包括常见问题解答(FAQ)、问题理解、信息检索、文档
库、答案抽取五大模块。
3 、问题理解模块
该模块主要实现计算机理解用户的问题,确定问题的关键词和问题的类型,为后面的信息检索和答案提供服务。问题理解模块的实现过程一般包括问题预处理、问题分类、关键词提取和关键词扩展等。其中,问题分类主要确定问题的类别,以方便信息检索和答案抽取。问题理解模块主要运用的技术有分词、同义词 词典、分类方法等。
4 、信息检索模块
该模块主要从互联网或者知识库中找到与问题相关的文档作为答案提取的原材料。信息检索的方法一般有两种,一种是直接利用搜索引擎检索信息;另一种是建立特定的知识库,然后根据知识库建立索引模块,从而可以方便、快速地找到相关文档,并根据特点的排序算法对文档进行排序。信息检索模块运用的技术主要包括查询扩展、语料库的构建技术、词汇索引、文档排序等。
5 、文档库模块
文档库用于存放专家提供的知识,其内部含有大量某个领域的常识性知识和专家水平的知识与经验总结,且能够利用专家的知识和解决问题的方法来处理该领域问题。
6 、答案抽取模块
该模块主要利用问题的类型构建相应的答案抽取策略,从信息检索后的文档中对排序靠前的文档进行答案的定位和输出,所用技术主要有答案抽取模板的制定、模式匹配、聚类等。
7 、图灵测试是指测试者在与被测试者(一个人和一台机器) 隔开的情况下,通 过一些装置(如键盘) 向被测试者随意提问。问过一些问题后,如果被测试者有**超过 70%**的答复不能使测试者确认出哪个是人、哪个是机器,那么这台机器就通过了测试,并被认为具有人类智能。
8 、人工智能发展大致分为三个阶段。
- 第一阶段( 20 世纪 50-80 年代) 刚刚诞生,符号主义快速发展。
- 第二阶段( 20 世纪 80 年代-90 年代末) 专家系统快速发展,数学模型有重大突 破。
- 第三阶段(21 世纪初至今) 大数据的积聚、理论算法的革新、计算能力的提升, 人工智能进入繁荣时期。
9 、人工智能在生活中的应用有智能制造、智能家居、智能教育、智能交通、智能安防、智能医疗、智能物流。














 1358
1358











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









