







一. SQL通信的基本概念
- 通信类型:同步方式
- 连接方式:长连接,服务端有连接池,连接池中创建的连接数默认为151个,最大可设置为10w,连接的超时时间默认为8h。
非交互式:show global variables like "wait_timeout" --jdbc--默认8h`
交互式:`show global variables like "interactive_timeout"--navicate--默认8h`
查询连接线程: `show status like 'Thread%' `
连接数:`show variables like "max_connections"`-默认151, 最大10w
- 通信协议:TCP/IP
- 通讯方式: 半双工,在一个时刻,线路上只允许一个方向上的数据传输,传输的过程中有字节大小的限制,不管是查询sql语句,还是返回语句大小,都不能超过某个数,否则会报错。(单工:遥控器,全双工:打电话)
每次通讯允许的最大字节数:show variable like "max_allo";(默认4M)
二. mysql的架构分层

- 连接层:客户端和服务端进行连接的时候,需要输入ip,端口,用户名,密码,那么连接层会帮我们作连接的管理,权限的验证。
- 缓存:MySQL内部自带了一个缓存模块,以key-value的形式存在,因为不推荐使用,所以默认是关闭的,第一个是它要求 SQL 语句必须一模一样,中间多一个空格,字母大小写不同都被认为是不同的的 SQL。第二个表里面任何一条数据发生变化的时候,这张表所有缓存都会失效,所以对于有大量数据更新的应用,也不适合。
- 解析器:一个是词法解析器,把一个完整的 SQL 语句打碎成一个个的单词。一个是语法解析器,语法分析会对 SQL 做一些语法检查,比如单引号有没有闭合,然后根据 MySQL 定义的语法规则,生成解析树。

- .预处理器:一个是语义分析,判断表名是否存在,字段是否存在,别名是否正确。另一个是权限的分析,比如给某个用户分配了查询的权限,那么他就没有更新的权限。同时生成一个新的解析器。
- 查询优化器:客户端发送的查询语句,并不是直接执行的,要根据解析树生成不同的执行计划,选择一个开销最小的计划去执行,例如:where a = 6 and b > a 可以优化为为a = 6 and b > 6;where 1 = 1 and a = 6 可以去掉1 = 1;当我们对多张表进行关联查询的时候,以哪个表的数据作为基准表;有多个索引可以使用的时候,选择哪个索引;
查看sql语句的执行计划:explain select * from bank_acount where id = 1;

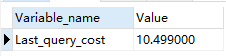
查看执行成本:show status like “last_query_cost”; (注意:单位并不是毫秒)
- 执行器:调用存储引擎的api操作数据,例如数据的过滤,排序等,是执行器在内存中执行。
- innodb存储引擎
(1) 以update bank_acount set name = “张三三” where id = 2;为例
(2) 执行器请求修改id为2的银行账户的账户名字为"张三三";
注意:所有的操作都是由执行器在缓冲池中完成,因此需要把数据加入内存
(3) 存储引擎从内存或者磁盘读取到这条数据返回给执行器(所有操作在内存中进行)
注意:如果缓冲池中没有,那么innodb会将要操作的数据加入到缓冲池(buffer pool)中, 为了避免性能的浪费(磁盘相对于内存,很慢),根据局部性原理(某一行被操作,附近的数据也很有可能被操作),每次会加载一页(16k),而不是一行。
(4) 执行器修改id=2的账户名字为张三三
(5) 记录到undolog;
注意:
(6) 记录到redolog;
注意:redolog是被顺序写入磁盘,由线程定时将redolog中记录的数据写入数据对应的本地磁盘,。
(7) 将修改的内容加载到bufferpool中
(8) 由线程负责刷脏
















 3931
3931











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











