






🔥作者主页:疯狂行者🔥 💖✌java领域优质创作者,专注于Java技术领域技术交流✌💖
💖文末获取源码💖
精彩专栏推荐订阅:在 下方专栏👇🏻👇🏻👇🏻👇🏻Java精彩实战项目案例
Java精彩新手项目案例
Python精彩新手项目案例
NodeJS精彩项目
文章目录
一、 引言
乳腺癌的高发病率与诊断精准性不足的矛盾日益凸显,临床诊断中大量多维乳腺癌数据缺乏高效的整合管理与直观分析手段,传统数据处理方式难以应对海量数据的存储与运算需求,特征提取不全面、诊断依据呈现模糊等问题直接影响诊断效率与准确性,开发一套能实现数据高效处理、多维度分析及可视化呈现的系统成为临床诊断辅助的迫切需求。
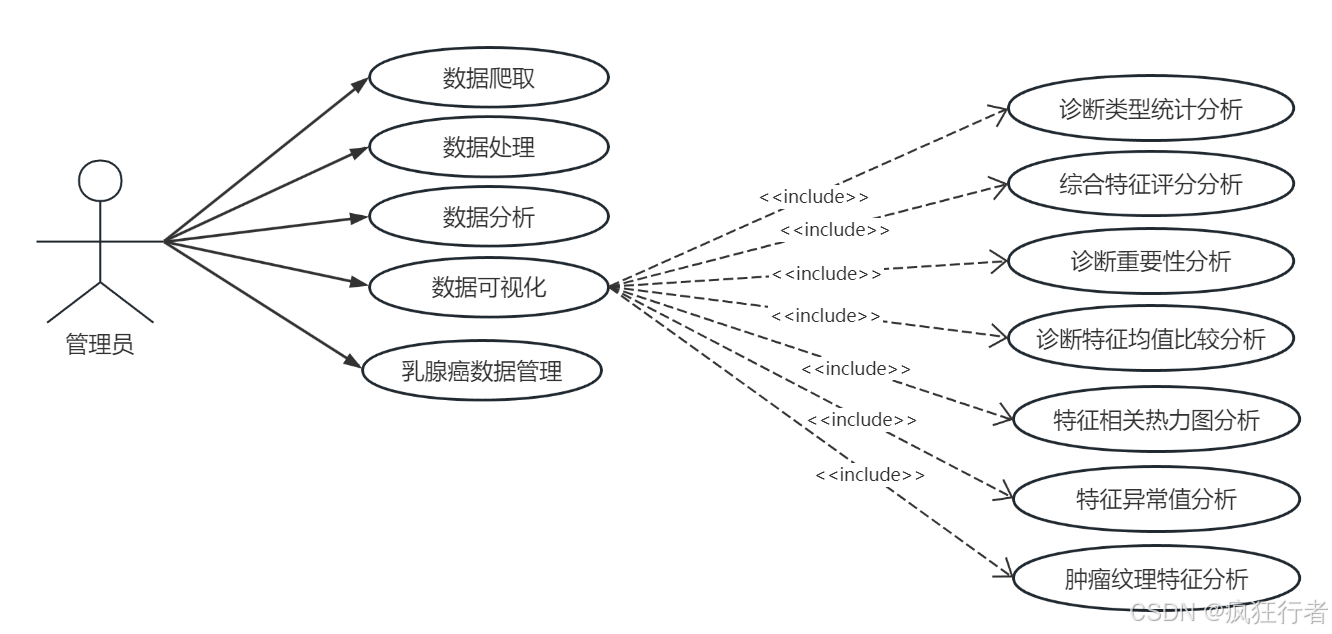
系统以乳腺癌诊断相关数据为核心,通过 Scrapy 爬虫技术获取多源数据,借助 Python 与 Pandas 完成数据清洗、整合及预处理,依托 Hadoop 框架实现海量数据的分布式存储与高效运算,采用 Django 搭建 Web 应用架构支撑登录注册、个人信息管理、乳腺癌数据管理及系统管理等基础功能,运用 Echarts 构建多维度可视化模块,涵盖诊断类型统计、综合特征评分、诊断重要性等多项分析场景,结合 CNN 与 LSTM 模型完成情感分析,同时通过多模态融合模型强化疾病预测能力,实现数据爬虫、处理、管理、分析与可视化的全流程覆盖。
系统通过整合大数据处理、深度学习与可视化技术,为乳腺癌诊断提供了全面的数据支撑与直观的分析工具,规范了乳腺癌数据的管理流程,提升了特征分析的全面性与诊断依据的可读性,其多维度分析结果与可视化呈现形式可为临床医生提供可靠的决策参考,一定程度上降低诊断偏差,为疾病预测与早期干预提供技术支持,具有实际的临床应用价值与推广潜力。
二、系统分析
2.1 开发环境
- 开发语言:Python
- 技术:Django+Hadoop+Spark
- 数据库:MySQL
- 架构:B/S
- 源码类型: Web
- 编译工具:PyCharm、VsCode
2.2 研究意义
世界卫生组织国际癌症研究机构发布的全球癌症统计数据显示,2022 年全球乳腺癌新发病例达 230 余万例,占女性新发癌症病例的 29%,位居女性恶性肿瘤发病首位,而在我国,每年乳腺癌新发病例超 40 万例,且呈现出发病率逐年上升、发病年龄逐渐年轻化的趋势,与此同时,临床诊断数据显示,约有 15%-20% 的乳腺癌病例因早期诊断不及时或诊断依据不充分导致病情延误,这些数据都表明乳腺癌已成为威胁女性健康的重要疾病,而高效的诊断辅助手段对提升乳腺癌早期诊断率、改善患者预后具有关键作用,但当前临床中对乳腺癌诊断相关数据的处理仍以传统方式为主,大量包含肿瘤纹理、特征均值等关键信息的数据分散存储于不同系统,难以实现高效整合与深度分析,这一现状与日益增长的乳腺癌诊断需求之间形成明显差距,也凸显了构建专业数据处理与分析系统的必要性。
现有乳腺癌诊断数据处理方案中,部分医疗机构仍采用 Excel 表格等简单工具进行数据记录与统计,这种方式不仅无法实现海量数据的快速存储与调用,还容易出现数据重复录入、异常值遗漏等问题,比如某地区基层医院在处理近 5 年乳腺癌患者数据时,因缺乏专业数据管理工具,导致约 8% 的患者特征数据出现录入错误,影响后续诊断分析;还有些方案虽具备基础数据管理功能,但缺乏多维度可视化分析模块,医生无法直观查看诊断类型分布、特征相关热力图等关键信息,难以快速把握数据背后的诊断规律,针对这些问题,本课题研究目的是开发一套基于 Hadoop 的乳腺癌诊断数据可视化分析系统,通过整合数据爬虫、处理、管理、分析与可视化功能,实现乳腺癌数据的高效处理与直观呈现,为临床诊断提供更全面的技术支持。
本课题的意义可从临床应用、技术实践与行业发展三个角度展开,在临床应用角度,系统能规范乳腺癌数据管理流程,减少数据处理过程中的错误率,其多维度可视化分析功能可帮助医生快速识别诊断关键特征,比如通过特征异常值分析及时发现潜在风险病例,一定程度上提升诊断效率与准确性,为患者争取更早的治疗时机;在技术实践角度,系统整合 Scrapy、Hadoop、Django 等多种技术,实现了大数据处理与 Web 应用开发的有效结合,为同类医疗数据可视化系统的开发提供了可参考的技术方案;在行业发展角度,系统将深度学习技术融入情感分析与疾病预测环节,推动了大数据技术在医疗诊断领域的实际应用,有助于促进医疗数据资源的高效利用,为医疗信息化建设提供助力,这些意义都让系统在实际应用中具备较高的实用价值。
2.3 需求分析
本系统整体功能需求围绕乳腺癌诊断数据的全流程处理展开,主要目标是实现乳腺癌数据的高效获取、规范管理、深度分析与直观可视化呈现,为临床医生、医疗数据管理人员提供专业工具支持,服务对象涵盖各级医疗机构的临床诊断人员、医疗数据处理人员及相关研究人员,通过整合多模块功能满足乳腺癌诊断数据从采集到应用的各环节需求,助力提升诊断辅助效率与数据利用价值。
2.3.1 管理员模块:
- 数据爬虫角色功能
数据爬虫角色需借助 Scrapy 技术从多源医疗数据平台获取乳腺癌相关数据,包括患者基本信息、肿瘤特征数据、诊断结果记录等,过程中要确保数据采集的合法性与完整性,避免遗漏关键特征字段,同时能根据需求设定采集频率与范围,解决传统人工采集效率低、数据覆盖不全面的问题,为后续数据处理提供充足且规范的数据源。
数据处理角色功能
数据处理角色以 Python 与 Pandas 为核心工具,对爬虫获取的原始数据进行清洗、整合与预处理,包括剔除重复数据、修正异常值、补全缺失字段、标准化数据格式等操作,还要完成数据的分类存储与格式转换,使其适配 Hadoop 分布式存储框架,确保处理后的数据能满足后续分析与可视化模块的调用需求,减少因数据质量问题影响分析结果的情况。 - 乳腺癌数据管理角色功能
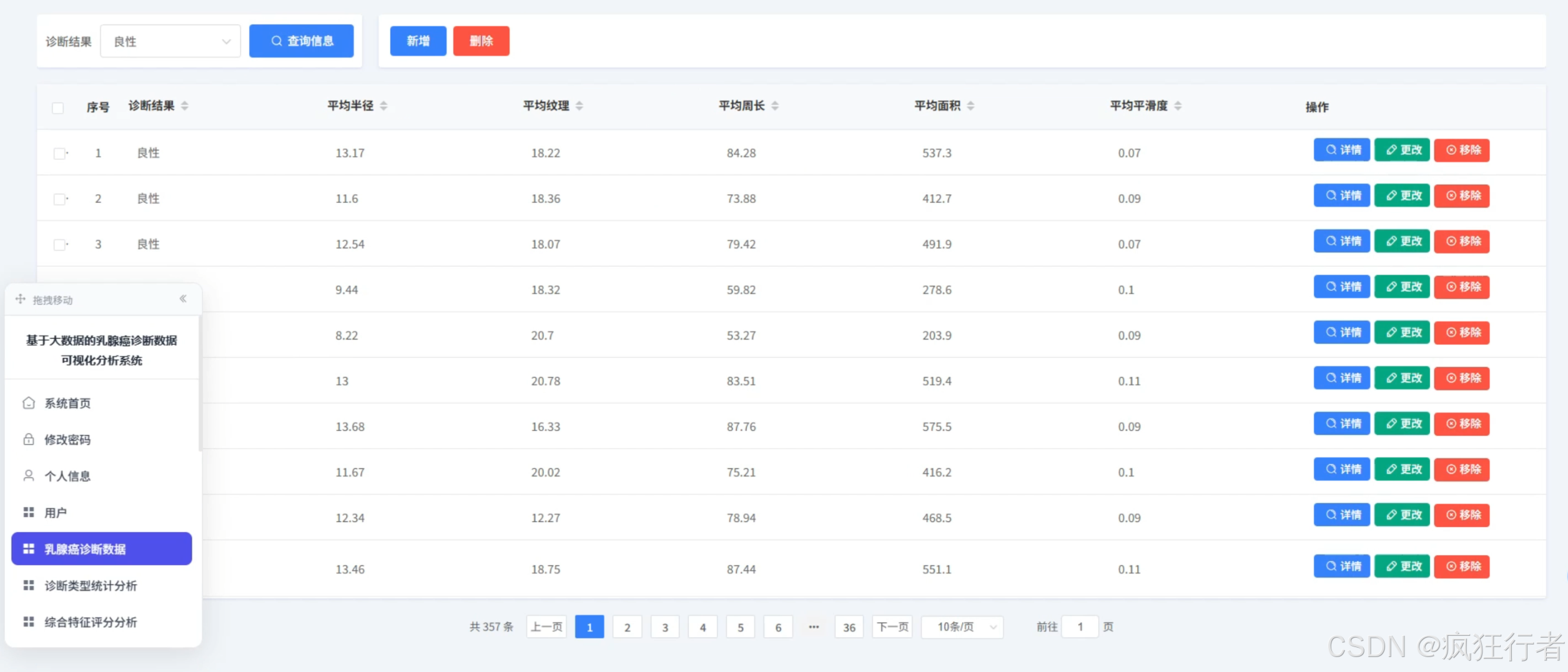
乳腺癌数据管理角色负责对处理后的乳腺癌数据进行系统化管理,包括数据的新增录入、查询检索、更新维护与删除归档,支持按患者 ID、诊断时间、肿瘤类型等多条件精准查询,能实时监控数据存储状态,确保数据安全与可追溯,同时可根据医疗数据管理规范设置数据访问权限,避免敏感信息泄露,让数据管理流程更符合临床实际应用场景。 - 数据分析角色功能
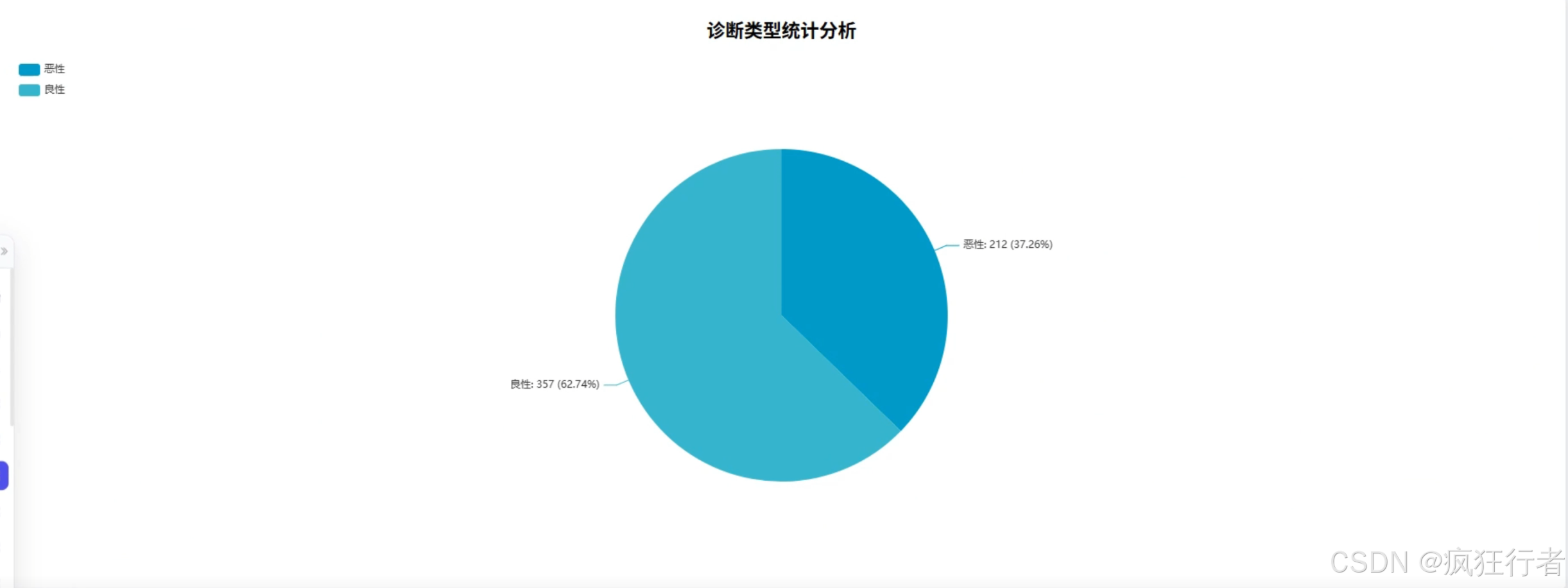
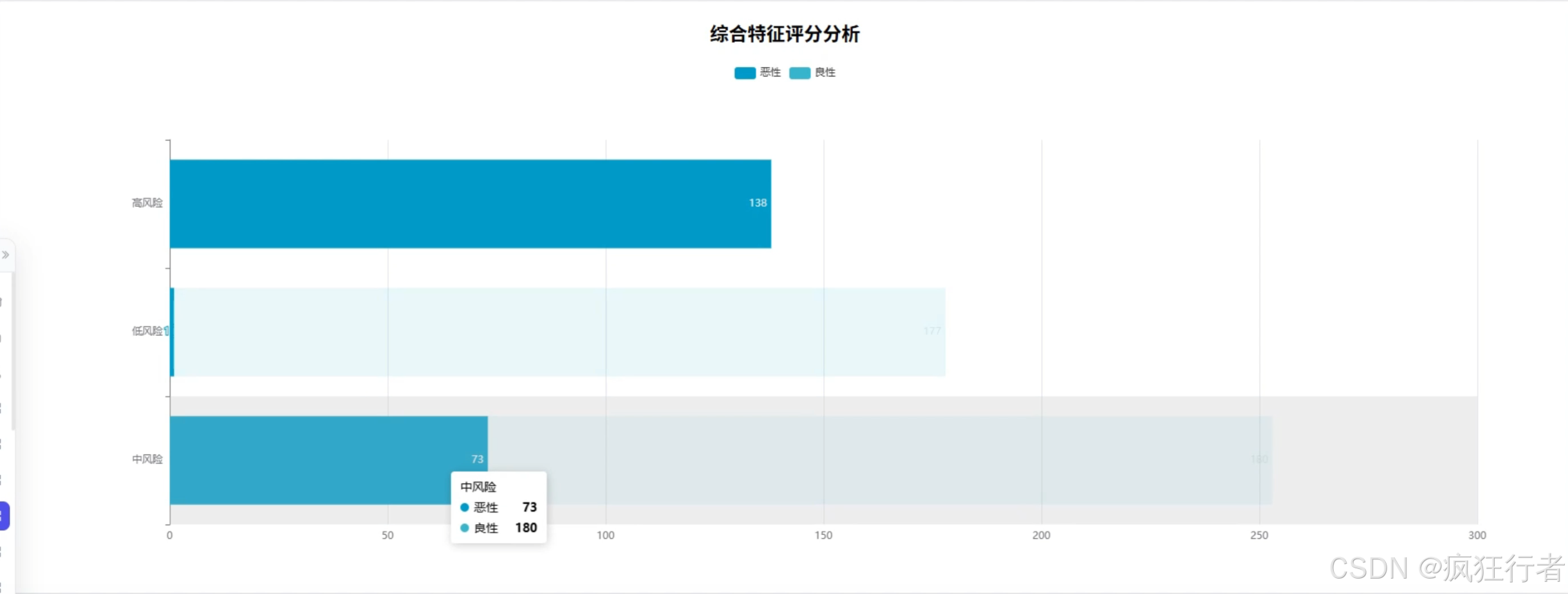
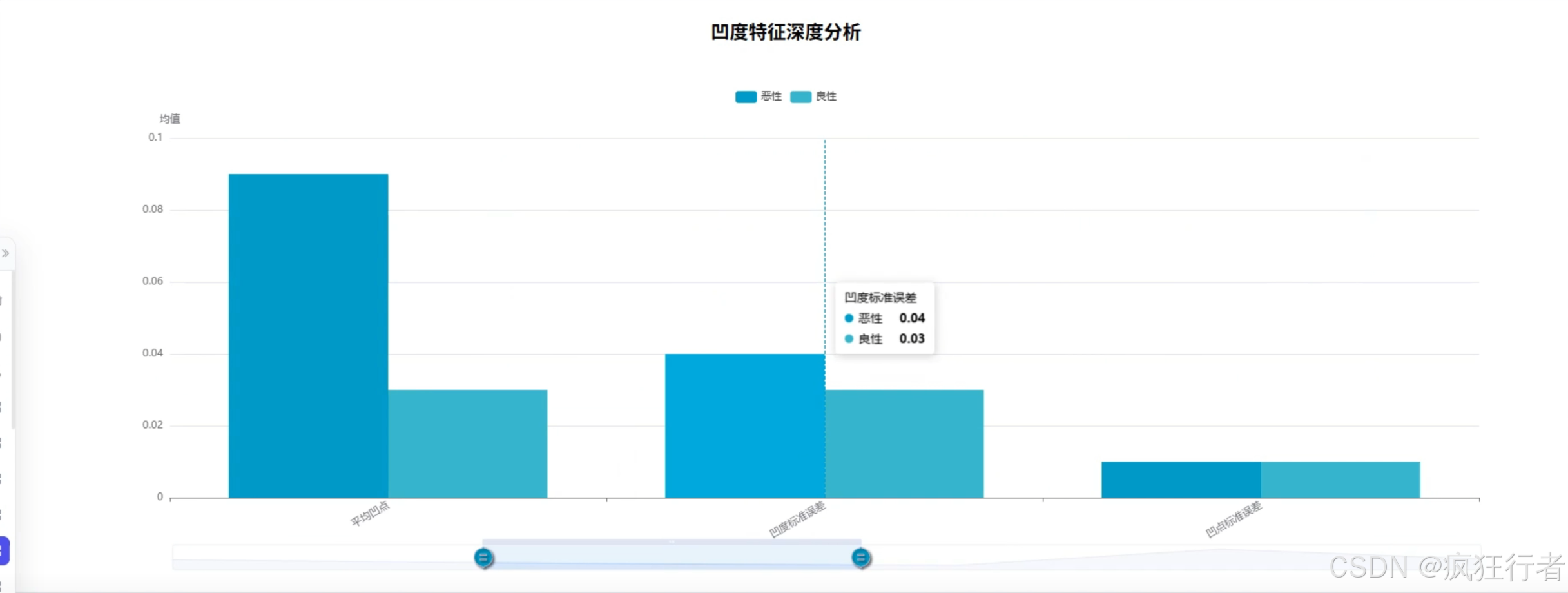
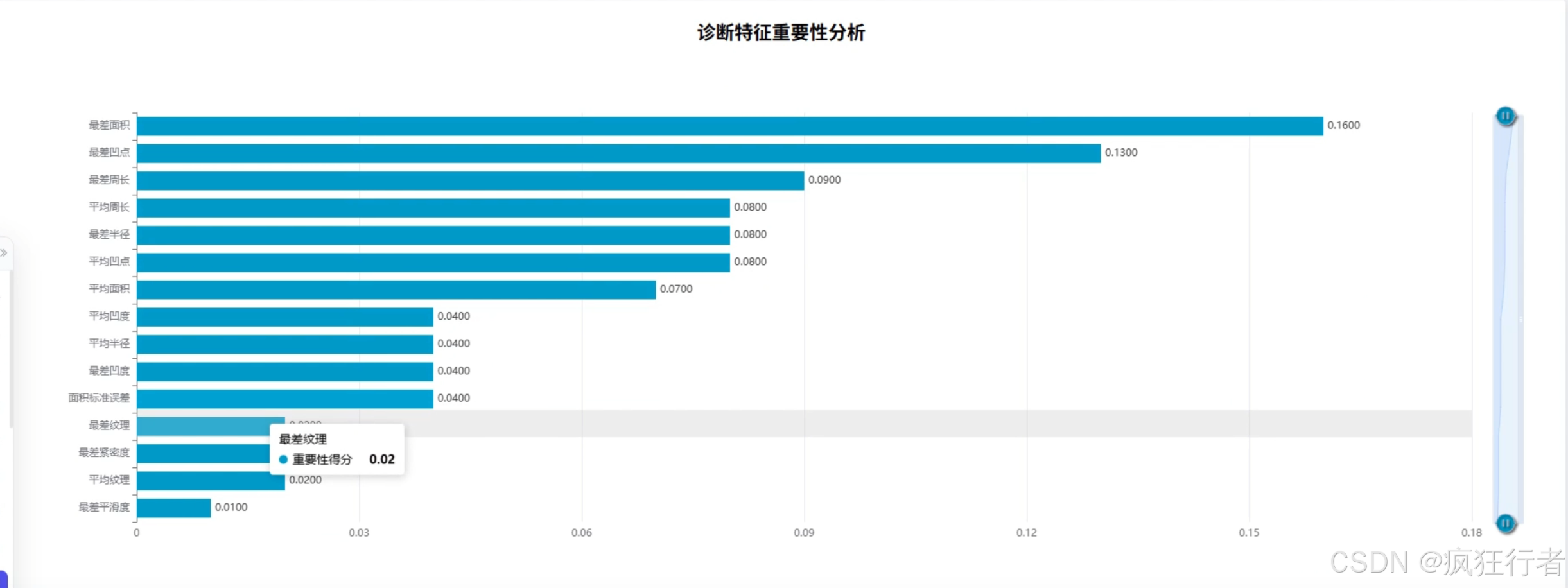
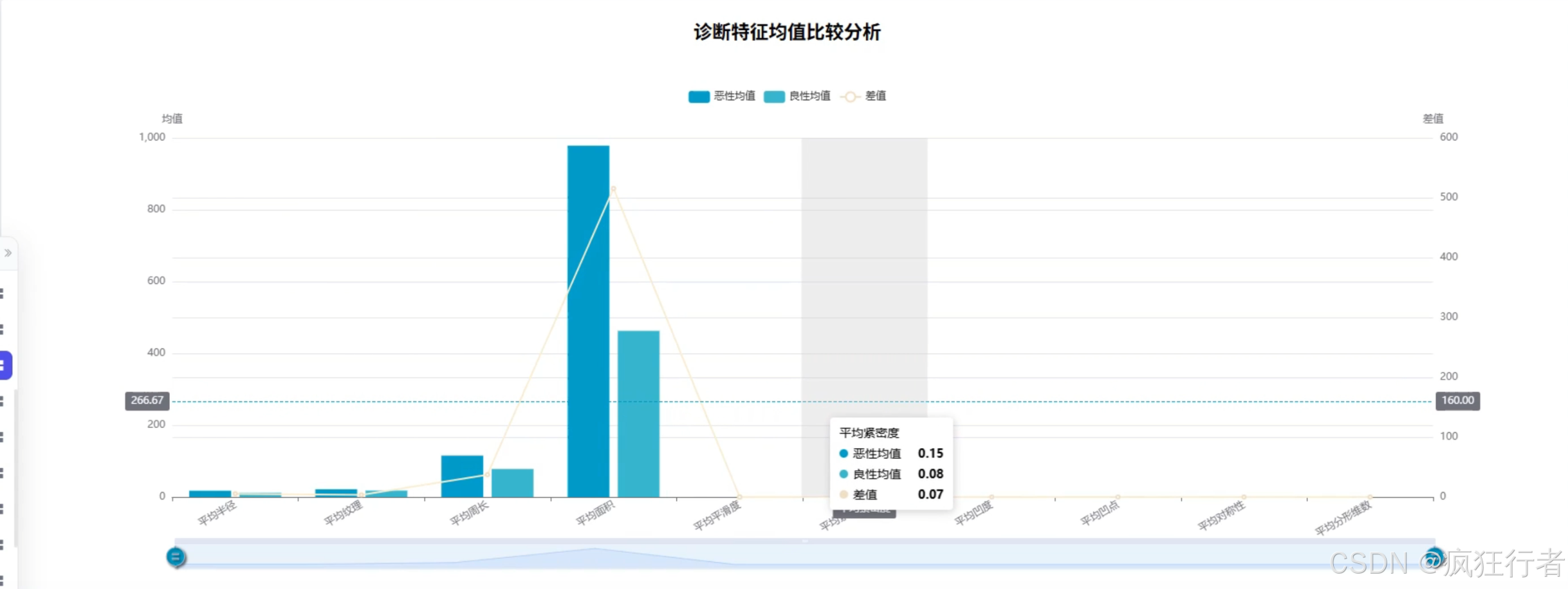
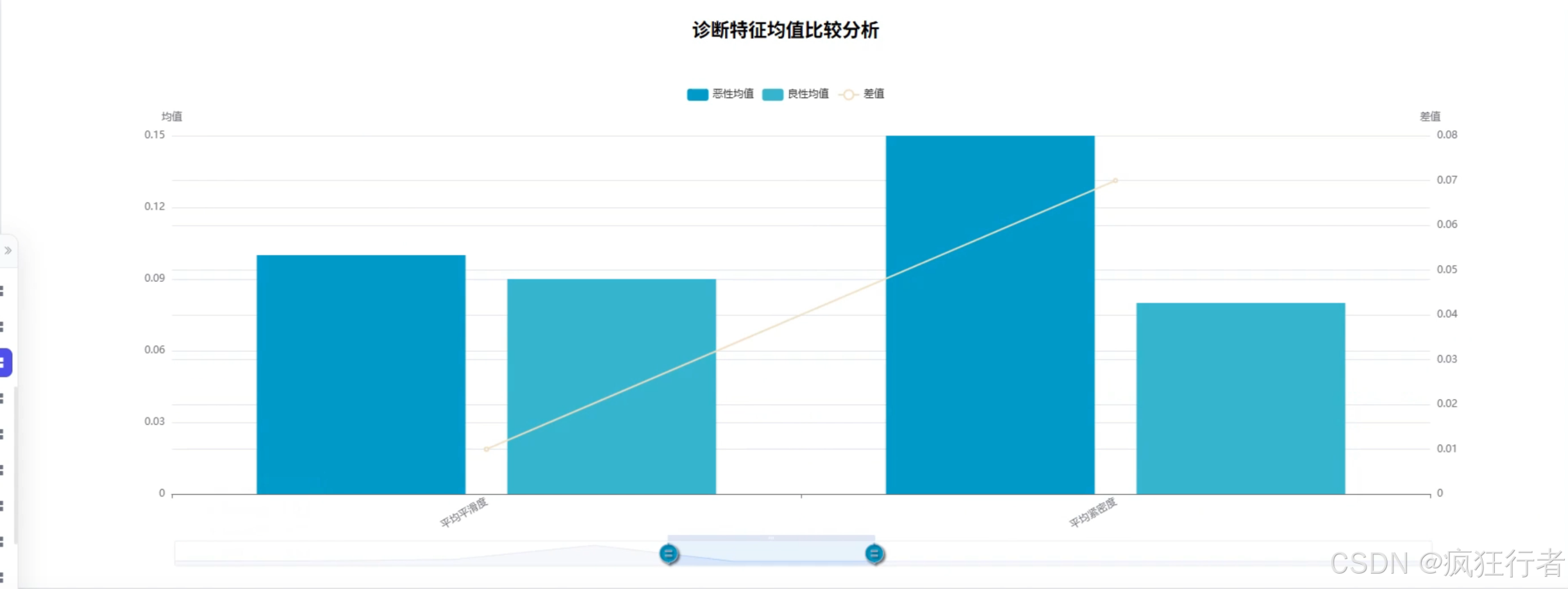
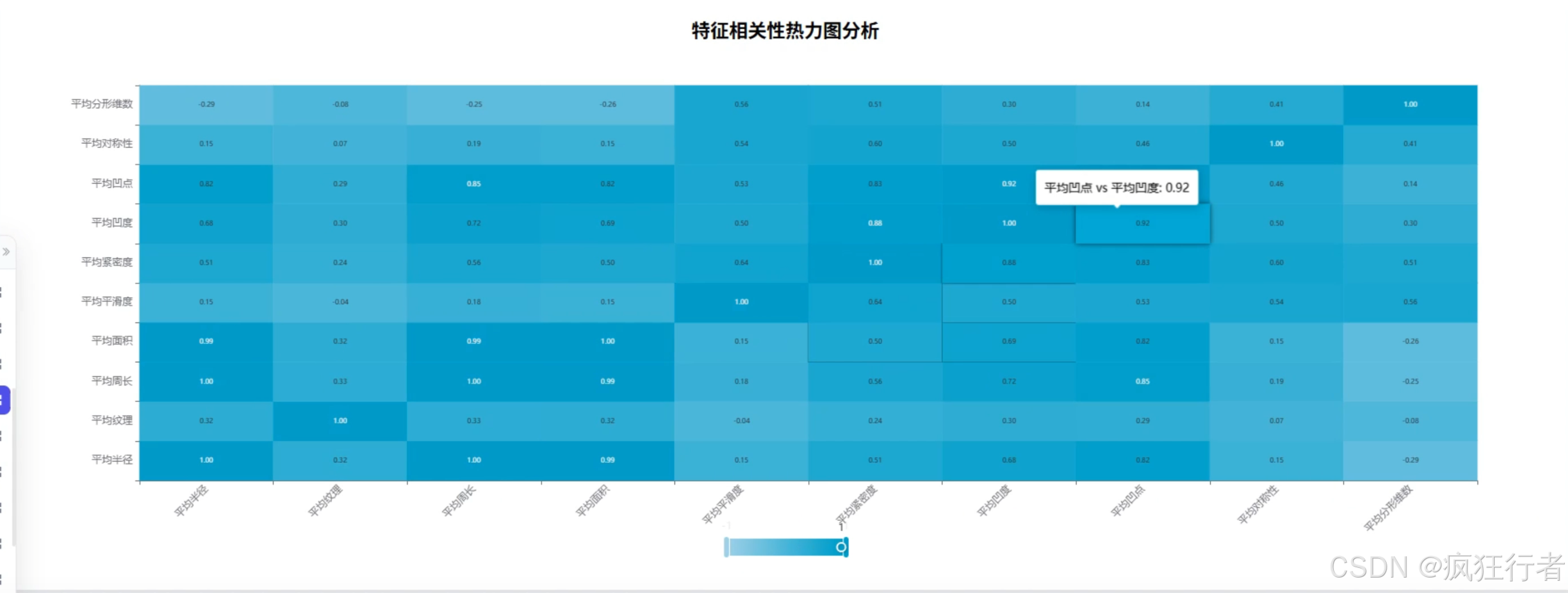
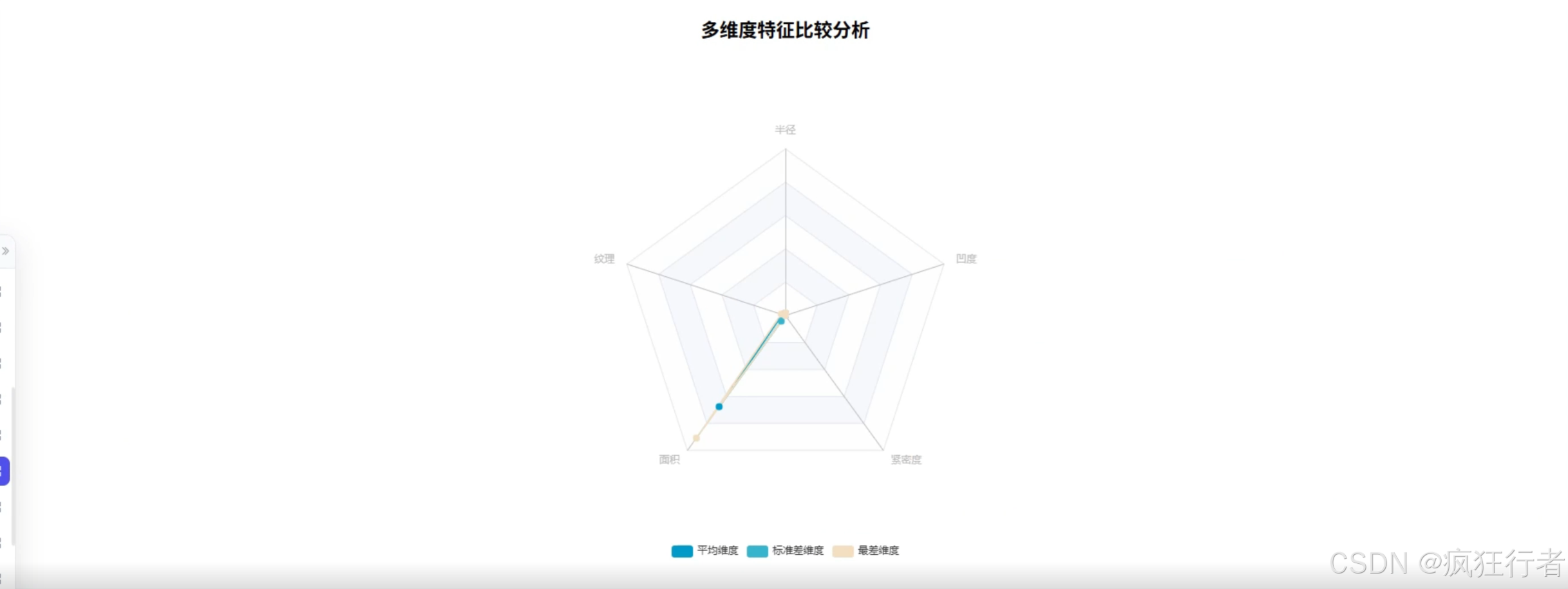
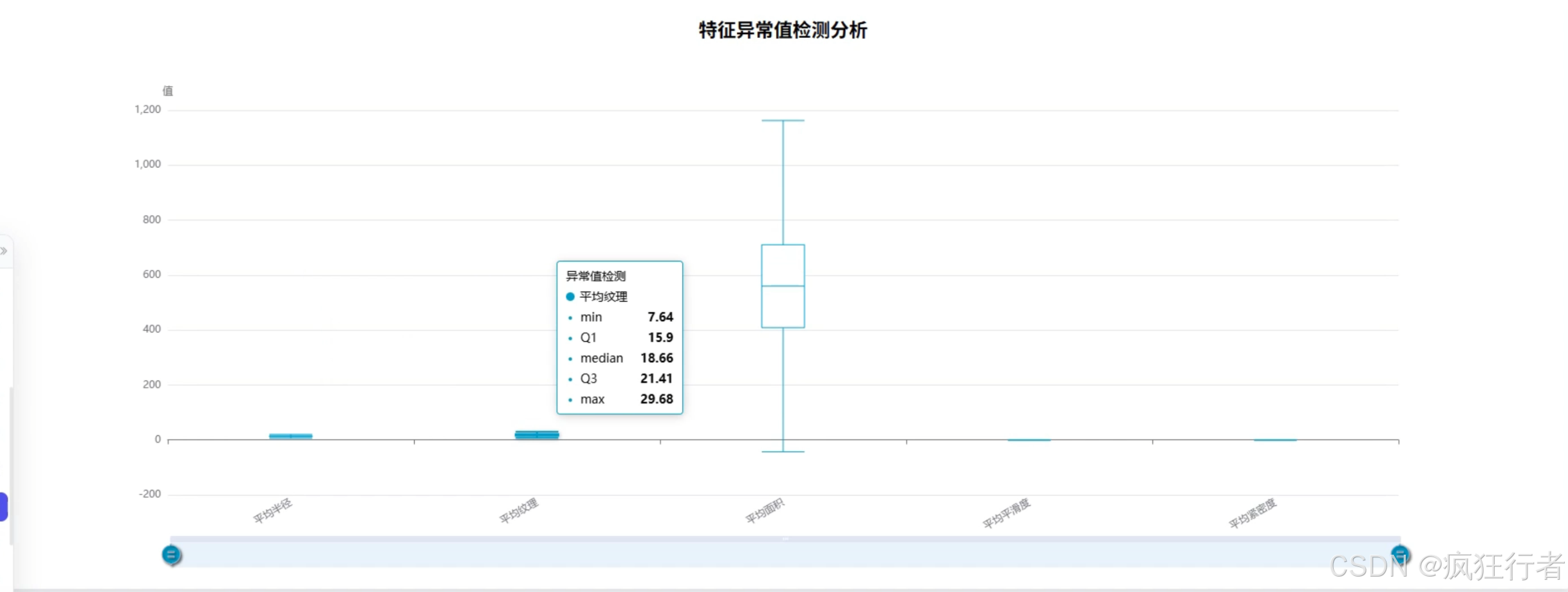
数据分析角色需实现多维度乳腺癌诊断数据分析,包括诊断类型统计分析、综合特征评分分析、诊断重要性分析、诊断特征均值比较分析、特征相关热力图分析、特征异常值分析及肿瘤纹理特征分析,通过调用预处理后的数据集,运用专业分析算法挖掘数据背后的诊断关联规律,生成详细的分析报告,为医生提供量化的诊断参考依据,比如通过特征相关热力图直观呈现不同肿瘤特征间的关联强度。
可视化分析角色功能
可视化分析角色依托 Echarts 技术将数据分析结果以图表形式呈现,包括柱状图展示诊断类型分布、折线图呈现综合特征评分变化、热力图显示特征相关性、箱线图识别特征异常值等,图表需支持交互操作,如点击查看具体数据详情、缩放调整视图范围,让复杂的分析结果更易被理解,帮助医生快速把握关键诊断信息,降低数据解读难度。 - 情感分析角色功能
情感分析角色基于 CNN 与 LSTM 融合模型,对乳腺癌患者相关文本数据(如病历中的症状描述、患者反馈信息)进行情感倾向识别,判断文本中蕴含的积极、消极或中性情感,提取其中与病情相关的关键信息,为临床诊断提供额外参考维度,比如通过分析患者对治疗效果的反馈文本,辅助评估治疗方案适用性,这种分析方式能补充传统数据维度的不足。 - 登录注册角色功能
登录注册角色为系统用户提供身份验证入口,新用户需填写真实身份信息(如医生执业编号、管理人员工号)完成注册,系统对注册信息进行审核确认后开通账号,已注册用户通过输入账号密码或验证身份信息完成登录,登录过程中需具备密码加密存储、登录异常提醒(如多次密码错误锁定账号)功能,确保用户身份合法性与账号安全,防止非授权人员访问系统。 - 个人信息管理角色功能
个人信息管理角色允许系统用户查看与修改个人基本信息(如姓名、联系方式、所属科室),更新账号密码,管理个人操作记录(如数据查询历史、分析报告生成记录),还可根据用户需求设置信息隐私权限(如是否允许其他用户查看个人生成的分析报告),操作过程中需保证信息修改的准确性与记录的可追溯性,让用户能便捷管理个人账号相关信息。 - 系统管理角色功能
系统管理角色主要负责系统整体运维与权限分配,包括管理所有用户账号(如新增用户、冻结违规账号、分配用户角色权限),监控系统运行状态(如服务器负载、数据存储容量、模块运行日志),及时处理系统故障(如数据传输错误、模块无法正常调用),还可根据业务需求更新系统功能(如新增分析维度、优化可视化图表样式),确保系统稳定运行并适配不断变化的应用需求。
三、系统设计
3.1 功能模块设计
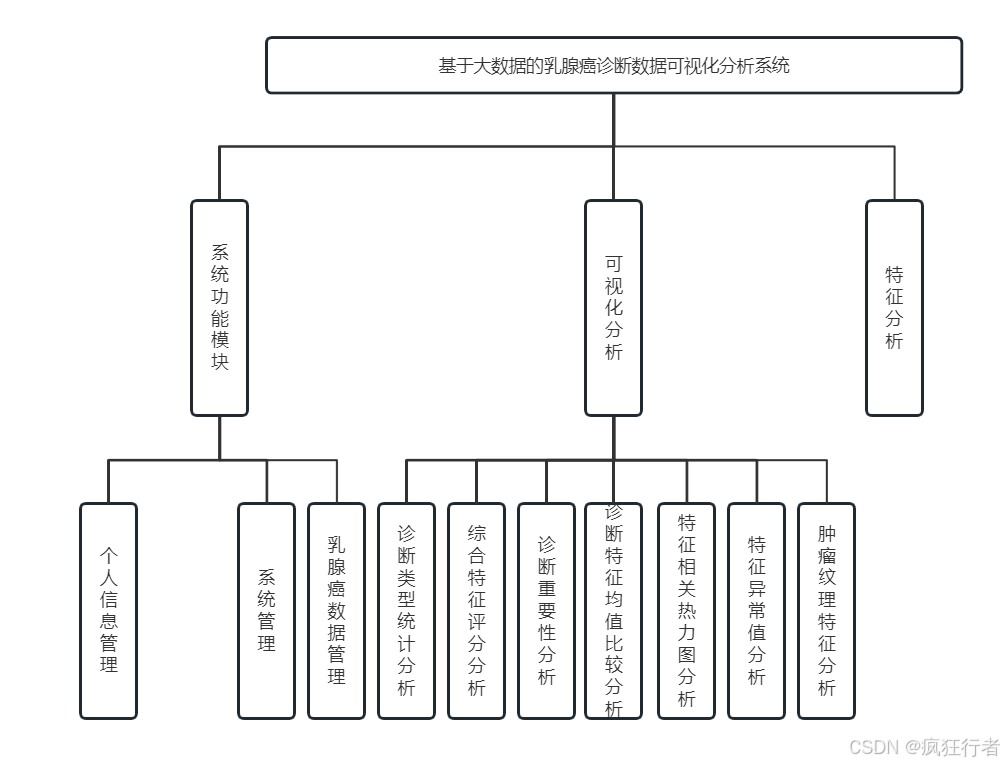
功能模块设计围绕各核心角色展开,数据爬虫模块借助 Scrapy 技术从多源医疗平台获取乳腺癌患者基本信息、肿瘤特征及诊断结果等数据,保障数据采集的合法性与完整性并可灵活设定采集频率与范围;数据处理模块以 Python 和 Pandas 为工具,对原始数据进行清洗、整合、预处理及格式转换,剔除重复数据、修正异常值、补全缺失字段,使数据适配 Hadoop 分布式存储框架以满足后续模块调用需求;乳腺癌数据管理模块负责处理后数据的新增、查询、更新与归档,支持多条件精准查询,监控数据存储状态并按规范设置访问权限,保障数据安全可追溯;数据分析模块实现诊断类型统计、综合特征评分、诊断重要性、特征均值比较、特征相关热力图、特征异常值及肿瘤纹理特征等多维度分析,调用预处理数据挖掘关联规律并生成分析报告;可视化分析模块依托 Echarts 将分析结果以柱状图、折线图、热力图、箱线图等形式呈现,支持交互操作以降低数据解读难度;情感分析模块基于 CNN 与 LSTM 融合模型,对患者病历症状描述、反馈信息等文本数据进行情感倾向识别,提取病情相关关键信息补充传统数据维度;登录注册模块为用户提供身份验证,新用户需填写真实信息经审核开通账号,已注册用户通过账号密码登录,具备密码加密存储与登录异常提醒功能;个人信息管理模块允许用户查看修改个人基本信息、更新密码、管理操作记录,并可设置信息隐私权限;系统管理模块负责用户账号管理、系统运行状态监控、故障处理及功能更新,分配用户角色权限,确保系统稳定运行并适配业务需求变化。系统的总体结构设计如图。
四、部分功能展示
五、部分代码设计
@RequestMapping("/page")
public R page(@RequestParam Map<String, Object> params, ProductEntity product,
HttpServletRequest request) {
EntityWrapper<ProductEntity> ew = new EntityWrapper<>();
PageUtils page = productService.queryPage(params, MPUtil.sort(MPUtil.between(MPUtil.likeOrEq(ew, product), params), params));
return R.ok().put("data", page);
}
@RequestMapping("/addOrder")
public R addOrder(@RequestBody OrderEntity order, HttpServletRequest request) {
order.setId(new Date().getTime() + new Double(Math.floor(Math.random() * 1000)).longValue());
orderService.insert(order);
return R.ok();
}
@RequestMapping("/userPage")
public R userPage(@RequestParam Map<String, Object> params, UserEntity user,
HttpServletRequest request) {
EntityWrapper<UserEntity> ew = new EntityWrapper<>();
PageUtils page = userService.queryPage(params, MPUtil.sort(MPUtil.between(MPUtil.likeOrEq(ew, user), params), params));
return R.ok().put("data", page);
}
总结
源码获取:
大家点赞、收藏、关注、评论啦 、
打卡 文章 更新 142/ 365天
精彩专栏推荐订阅:在 下方专栏👇🏻👇🏻👇🏻👇🏻
Java精彩实战项目案例
Java精彩新手项目案例
Python精彩新手项目案例
NodeJS精彩项目


















 1207
1207

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











