






Daily learning:图像分割
只对论文进行了解其网络模型,后续代码重现会慢慢补、
1.摘要
提出了一种基于SegNet的efficientSegNet腹部器官图像分割,由三个部分组成encoder,slim decoder,efficient context block,三部分组成。
- encoder:选择Basic Convolution,设计了一个
片内卷积核(inter-slice convolution)和一个
片内卷积核(inter-slice convolution),为了减少计算量。
- context block:提出了AnisotropicAvgPooling block,对比SSP block 等有更优秀的上下文表示能力
- slim decoder:选择Anisotropic Convolution,对于分割指标影响较小。
这种方法在2021-MICCAI-FLARE挑战赛上获得第一名。
2.介绍
本文主要研究腹部CT扫描的多器官分割。如图所示,主要难点来自四个方面:
- 不同器官的视场、形状和大小的差异。
- 病变器官等异常可能导致分割失败。
- 多中心、多阶段、多厂商案例的数据源多样性。
- GPU内存大小有限,计算成本高。
常用解决方法:
是开发一个滑动窗口( sliding-window method)方法,用来平衡GPU内存的使用。通常,该方法需要样本子体相互重叠以提高分割精度,但计算成本较高。同时,不可避免地要从整个CT模块中抽取子模块失去了一些3D信息,这对于区分多器官与隐藏物是很重要的。
作者怎么做的:
我们开发了一个基于全容量的粗到细框架,以有效和高效地解决这些问题。粗模型旨在从整个CT体积中获得目标器官的粗略位置。然后,精细模型在粗糙结果的基础上对分割进行细化。这个从粗到细的管道可以涵盖不同情况下的解剖学差异。为了捕获多器官之间的空间关系,我们利用带状池化来收集各向异性和长的上下文。这个条带池有两个好处。首先,与自注意或非本地模块相比,条带池消耗的内存和矩阵计算更少。其次,它沿着一个空间维度部署长而窄的池内核,以同时聚合全局和局部上下文。
作者的贡献:
- 我们提出了一个基于全容积的粗-细框架,充分利用整体的3D背景,该管道涵盖了不同情况下发生的解剖变异。
- 我们设计了计算成本低的各向异性卷积块。我们提出了条带池模块来捕获各向异性和长程上下文信息。
- 在FLARE2021挑战数据集上验证了所提出的基于整体进化的粗-细框架的有效性和效率,我们以较低的时间成本和更少的内存使用达到了最先进的水平。
3.数据预处理
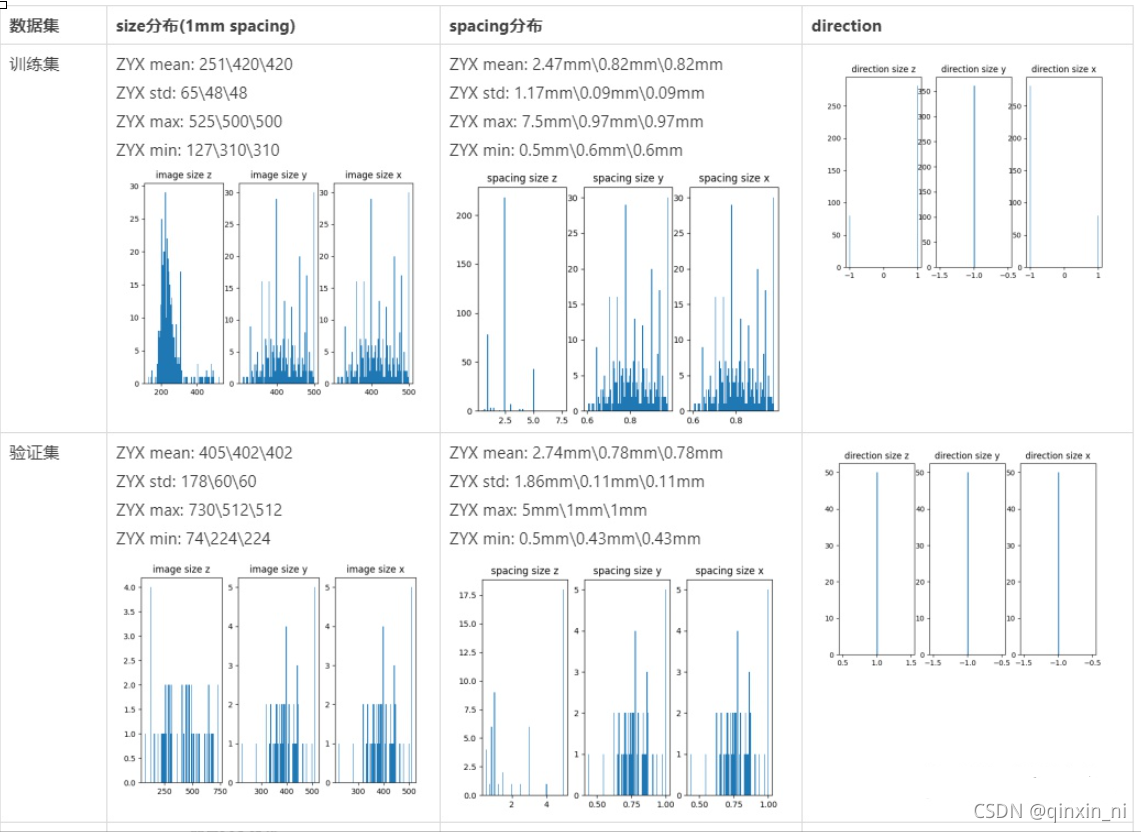
图像信息统计如下,训练集的图像大小呈现正态分布,验证集为均匀分布,平均大小为Z,Y,X=251,420, 420(训练集)、Z,Y,X=405,402,402(验证集), X、Y轴大小一致,但Z轴差异较大,主要是扫描范围差异较大导致的; 图像spacing平均为Z,Y,X=2.5, 0,8, 0.8mm,训练集和验证集基本一致; 训练集图像Z轴direction不一致,验证集图像direction为Z,Y,X=1,-1,-1,本文将所有图像的direction归一化为Z,Y,X=1,-1,-1,这样能够减少do redirection的次数。
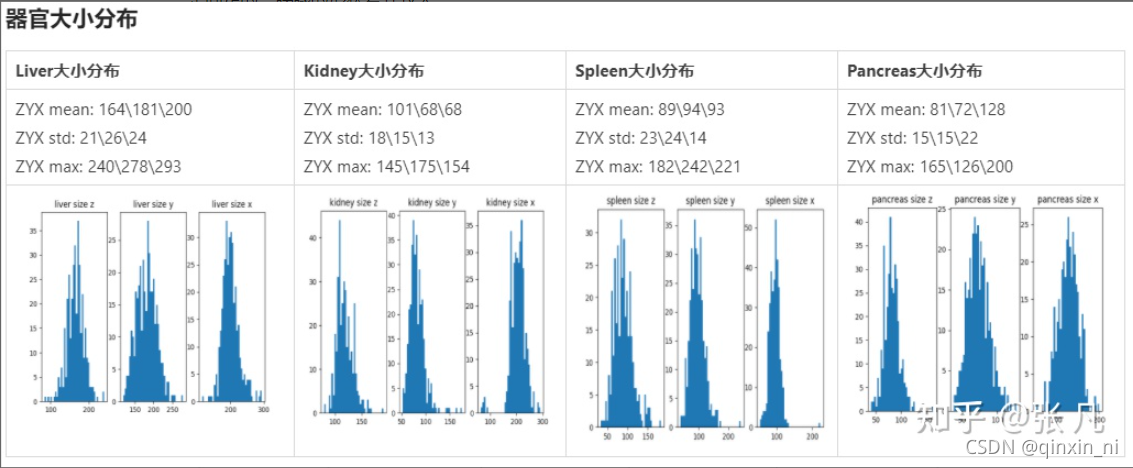
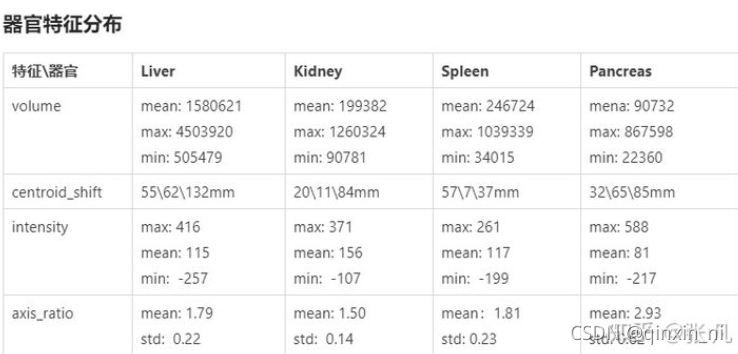
各个器官形状特征的分布如下。参考器官volume特征,设置保留最大连通区域的阈值;参考intensity特征,设置对比度增强参数;参考centroid_shift特征,统计器官之间的相对位置关系;参考axis_ratio特征,统计器官的形状差异。不同器官的大小符合正态分布;不同器官的相对位置是固定的;胰腺的形状差异较大。
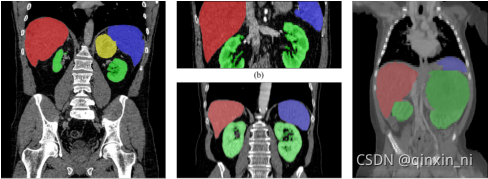
badcase特征如下:
badcase主要包括器官病变和器官缺失,尤其是肾脏、肝脏病变case较多。
肾脏病变:
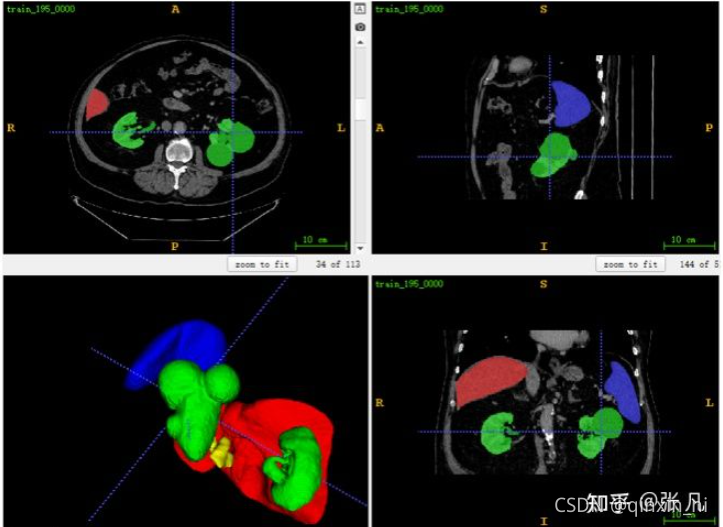
胰腺病变:
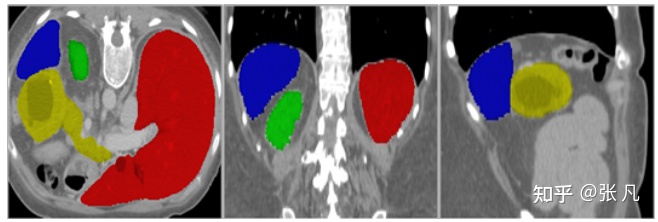
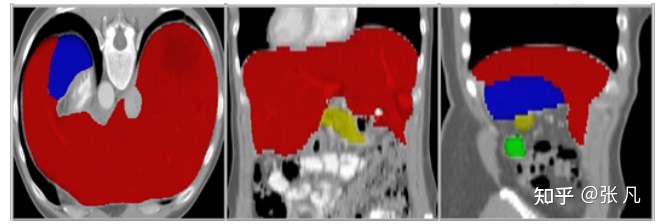
肝脏病变:
器官缺失:
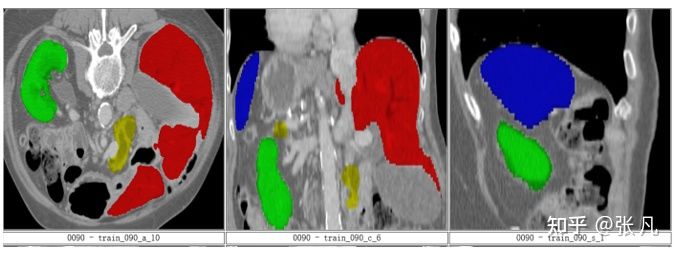
4. Implementation Details
环境配置和需求
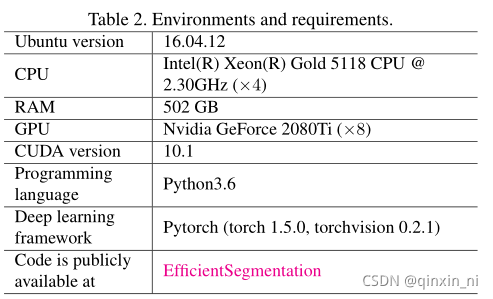
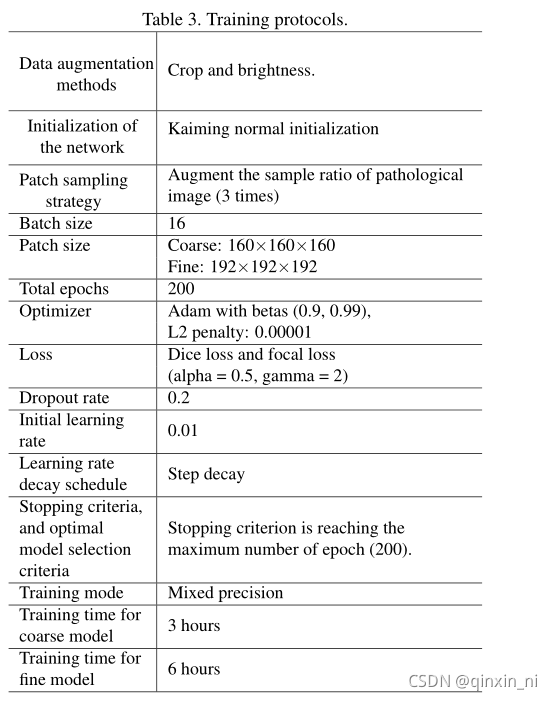
Training protocols
Testing protocols
训练步骤采用相同的前处理和后处理方法。为了减少预处理和后处理的时间开销,在GPU中计算重采样和强度归一化。在C++中实现连通性分析,即cc3d 。在FP16模式下实现了该推理模型。使用动态空缓存来减少GPU内存。
Pipeline
本文采用基于整图的二阶段分割流程,阶段一实现腹部器官的定位,阶段二实现器官的细分割。关于分割流程的设计参考:如何破解医学影像分析算法显存不足的困境 - 知乎前言 做三维医学图像分析的同学,是不是经常遇到显存不够用的绝望。本文将通过经典的肺分割算法流程,分享多阶段分割、合理的图像分块、模型优化及模型训练技巧来提高GPU显存的利用率。本文更多是从算法工程化的角… https://zhuanlan.zhihu.com/p/210910247
https://zhuanlan.zhihu.com/p/210910247
分割算法流程如下图:
粗分割输入大小为160, 160, 160, 细分割为192, 192, 192。由于粗分割用于器官定位,采用更低的输入分辨率、复杂度更低的网络结构;根据粗分割mask,裁剪腹部区域图像块作为细分割的输入,这样能够降低不同case图像块之间的差异。

本文在GPU中实现resampe和normalization,来加快推理速度。由于后处理比较耗时,本文采用异步实现细分割后处理。本文采用C++ library实现保留最大连通区域 cc3dhttps://github.com/seung-lab/connected-components-3d/tree/424328a11d712b38a032b57d8b25fe2d09051787 https://github.com/seung-lab/connected-components-3d/tree/424328a11d712b38a032b57d8b25fe2d09051787以及提取目标特征fastremap
https://github.com/seung-lab/connected-components-3d/tree/424328a11d712b38a032b57d8b25fe2d09051787以及提取目标特征fastremap
https://github.com/seung-lab/tinybrainhttps://github.com/seung-lab/tinybrain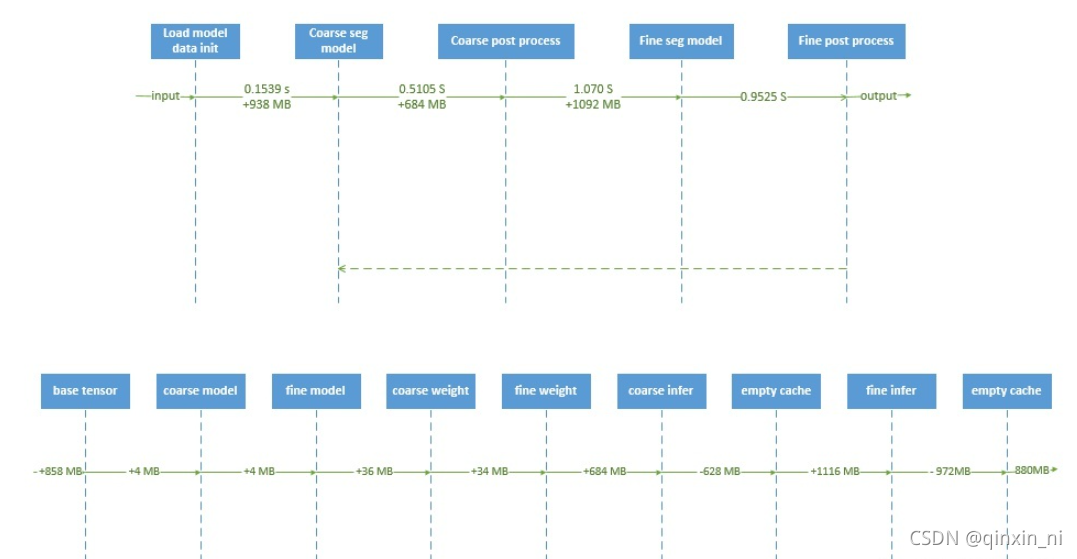
Network
EfficientSegNet网络,该网络由basic encoder、slim decoder和efficient context模块组成。在decoder模块中引入anisotropic卷积,提升了网络计算效率;设计mixed pyramid pooling的context模块,融入strip pooling结构,提升了anisotropic和long-range上下文特征的表示能力。相较于self-attention和non-local模块,strip pool具有更低的显存占用和矩阵运算量。算法实现上,采用混合精度、分布式训练技术来缩短训练过程时间,提升显存利用效率。在推理过程中,采用CUDA加速图像预处理和后处理,FP16量化推理提升模型推理效率。
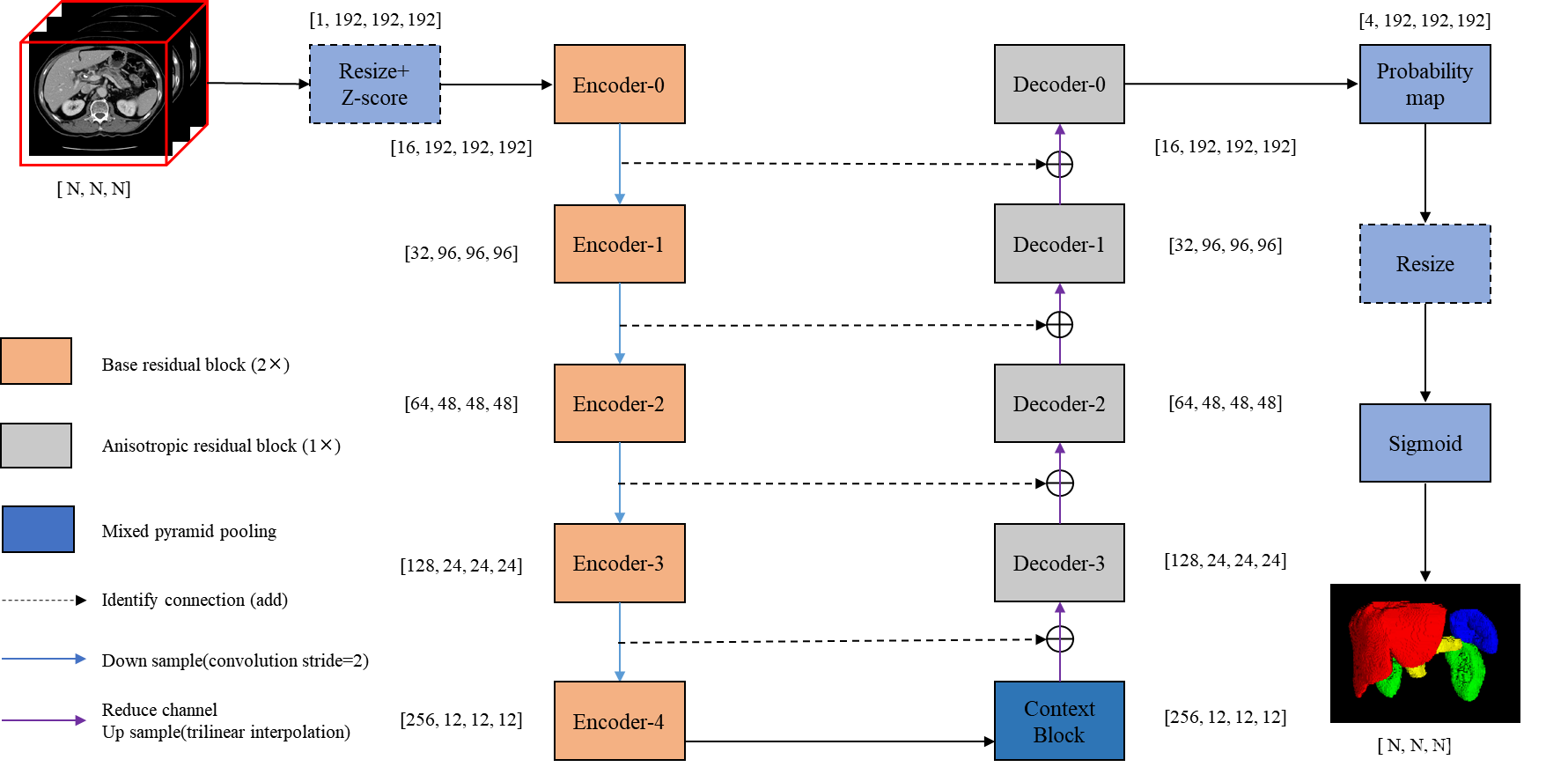
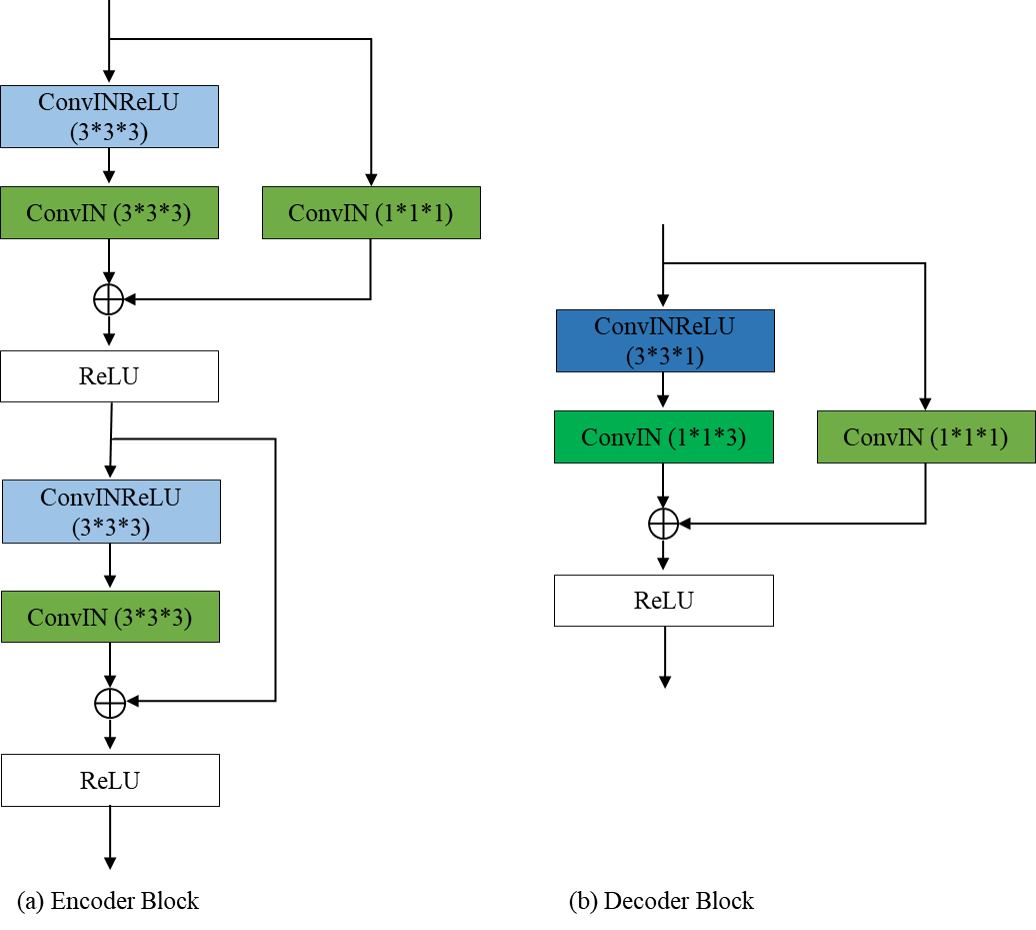
Encoder/Decoder
如图所示,编码器模块由两个残差卷积块组成,解码器模块由一个残差卷积块组成。在解码器模块中,我们将一个核大小为3×3×3的标准3D卷积分离为3×3×1片内卷积和1×1×3片间卷积。残差卷积块的实现如下:convent -instnorm-ReLU- convent -instnorm-ReLU(残差的加入发生在最后一个ReLU激活之前)。
Context block
我们采用基于3D-based mixed pyramid pooling (3D的混合金字塔池化)方法提取背景特征,该方法由标准空间池化和各向异性条带池化两部分组成。标准空间池使用两个平均池,大小分别为2×2×2和4×4×4。anisotropic strip pooling具有三个不同方向的感受域:1×N×N, N×1×N, N×N×1,其中N为上一个编码器模块中feature map的大小。
粗模型初始特征图个数为8,细模型初始特征图个数为16。我们通过添加而不是连接来聚合低级的水平特性,因为前者消耗的GPU内存更少。此外,对于192×192×192输入大小,模型参数的数量是9 MB,失败的数量是333 GB。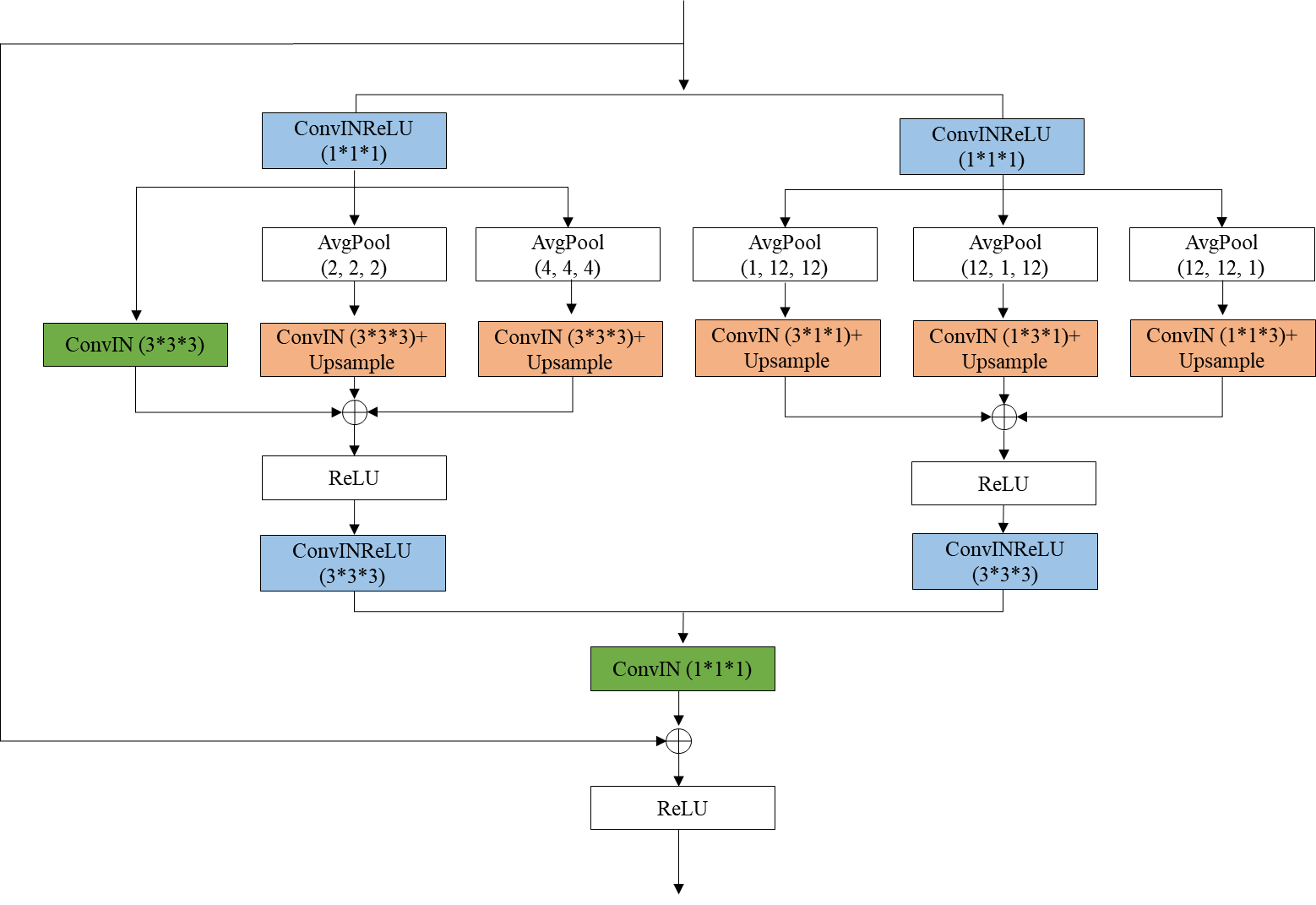
本文基于UNet,对Encoder、Decoder、Context block进行如下优化:
- 对比Basic Convolution、Bottleck Convolution、Depthwise Separable Convolution、Anisotropic Convolution,Encoder最优选择为Basic Convolution,Decoder最优选择为Anisotropic Convolution。相对于Basic Convolution,其他卷积方式具有更低的运算复杂度,但是分割指标存在一定程度的下降。Decoder采用更低复杂度的Convolution block,对于分割指标影响较小。
- 对比SPP block(https://arxiv.org/abs/1612.01105)、StripPooling block(https://arxiv.org/abs/2003.13328)、AnisotropicAvgPooling block,AnisotropicAvgPooling block具有更优的上下文特征表示能力
- 不同尺度特征的融合方式,本文将upsample+concate+convolution的融合方式,修改为down channel+upsample+add+convolution,后者计算复杂度更低
- 采用非对称的UNet结构,Encoder采用4层卷积block(包含2个residual block),Decoder采用2层卷积block(包含1个residual block)
结果与讨论
通过实验验证,最佳的系统配置如下:
- 数据增强方式:随机裁剪,加性对比度增强
- 网络结构:Encoder采用2个basic residual block,Decoder采用1个anisotropic residual block,Context采用AnisotropicAvgPooling
- 损失函数:dice+focal


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









