






原文连接:https://arxiv.org/abs/1904.08128
原文开源代码:https://github.com/MIC-DKFZ/nnUNet
Q1:2D U-Net?
A1: U-net 网络_qinxin_ni的博客-CSDN博客
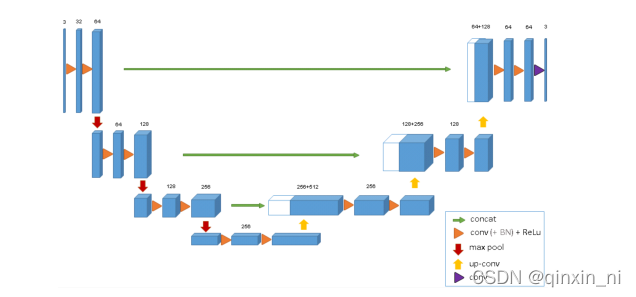
(1) 使用全卷积神经网络。(全卷积神经网络就是卷积取代了全连接层,全连接层必须固定图像大小而卷积不用,所以这个策略使得,你可以输入任意尺寸的图片,而且输出也是图片,所以这是一个端到端的网络。)
(2) 左边的网络是收缩路径:使用卷积和maxpooling.
(3) 右边的网络是扩张路径:使用上采样产生的特征图与左侧收缩路径对应层产生的特征图进行concatenate操作。
(4) 最后再经过两次反卷积操作,生成特征图,再用两个1X1的卷积做分类得到最后的两张heatmap,例如第一张表示的是第一类的得分,第二张表示第二类的得分heatmap,然后作为softmax函数的输入,算出概率比较大的softmax类,选择它作为输入给交叉熵进行反向传播训练。

A2:3D-U-Net?
Q2:3D U-Net_qinxin_ni的博客-CSDN博客
核心:训练过程只要求一部分2D slices,去生成密集的立体分割。
具体有两种方法:
(1)在一个稀疏标注的数据集上训练并在此数据集上预测其他未标注的地方;
(2)在多个稀疏标注的数据集上训练,然后泛化到新的数据。整个网络的结构前半部分(analysis path)包含及使用如下卷积操作:
- 每一层神经网络都包含了两个 3 * 3 * 3的卷积(convolution)
- Batch Normalization(为了让网络能更好的收敛convergence)
- ReLU
- Downsampling:2 * 2 * 2的max_polling,步长stride = 2
而与之相对应的合成路径(synthesis path)则执行下面的操作:
- upconvolution: 2 * 2 * 2,步长=2
- 两个正常的卷积操作:3 * 3 * 3
- Batch Normalization
- ReLU
- 于此同时,需要把在analysis path上相对应的网络层的结果作为decoder的部分输入,这样子做的原因跟U-Net博文提到的一样,是为了能采集到特征分析中保留下来的高像素特征信息,以便图像可以更好的合成。
在最后一层,1×1×1卷积将输出通道的数量减少到3个标签。该体系结构共有19069955个参数。通过在最大池化之前将通道数量加倍来避免瓶颈。
1. 介绍
语义分割将原始的生物医学图像数据转换为有意义的空间结构信息,因此对于该领域的科学发现起着至关重要的作用。同时,语义分割是许多临床应用的重要组成部分,包括人工智能在诊断支持系统、治疗计划支持、术中辅助或肿瘤生长监测中的应用。对自动分割方法的高度兴趣体现在蓬勃发展的研究领域,占生物医学领域国际图像分析竞赛的70%。
尽管基于深度学习的分割方法最近取得了成功,但它们在最终用户的特定图像分析问题上的适用性通常受到限制。方法的特定任务设计和配置需要高水平的专业知识和经验,而小的错误会导致性能大幅下降。尤其是在3D生物医学成像中,数据集属性(如成像方式、图像大小、(各向异性)体素间距或类别比率)会发生巨大变化,流程设计可能很麻烦,因为构成较好配置的经验可能无法转化到手头的数据集。设计和训练神经网络涉及的众多专家决策,从确切的网络体系结构到训练时间表和数据增强或后处理方法,不一而足。每个子组件都由基本的超参数控制,例如学习率、批处理大小或类别抽样。可用于训练和推理的硬件给整体设置增加了一层复杂性。在超参数的这种高维空间中,对相互依赖的设计选择进行算法优化在技术上要求很高,并且会放大所需训练案例的数量以及计算资源的数量级。结果,最终用户通常在方法设计过程中会经历反复的反复试验过程,而反复试验和错误过程主要是由他们的个人经验决定的,只有很少的文献记载和难以复制,不可避免地会引起次优的分割渠道和方法论上的发现到其他数据集。
作者提到,有大量的研究论文提出了架构变化和扩展以提高性能,这些研究对于非专家而言是难以理解的,甚至对于专家而言也难以评估。大约有12000项研究引用了2015年有关生物医学图像分割的U-Net架构,其中许多提出了扩展和进步。于是,作者提出了这样的假设:如果能设计合适的处理过程,基本的U-Net架构是很难被打败的。
作者提出一种nnUNet(no-new-Net)框架,基于原始的UNet(很小的修改),不去采用哪些新的结构,如相残差连接、dense连接、注意力机制等花里胡哨的东西。相反的,把重心放在:预处理(resampling和normalization)、训练(loss,optimizer设置、数据增广)、推理(patch-based策略、test-time-augmentations集成和模型集成等)、后处理(如增强单连通域等)。并由于以下两个关键因素而实现了开箱即用的分割:
- 根据数据指纹(data fingerprint,代表数据集的关键属性)和管道指纹(pipeline fingerprint,代表分割算法的关键设计选择)来制定流水线优化问题;
- 通过将领域知识浓缩到一组启发式规则中,使它们的关系明确化,该规则将在考虑相关联的硬件约束的情况下从相应的数据指纹稳健地生成高质量的管道指纹。
nnUnet可以无需人工介入,充分利用数据集的特点训练基本的U-Net模型,从而达到超越各种魔改U-Net架构的能力。
2.实现方法
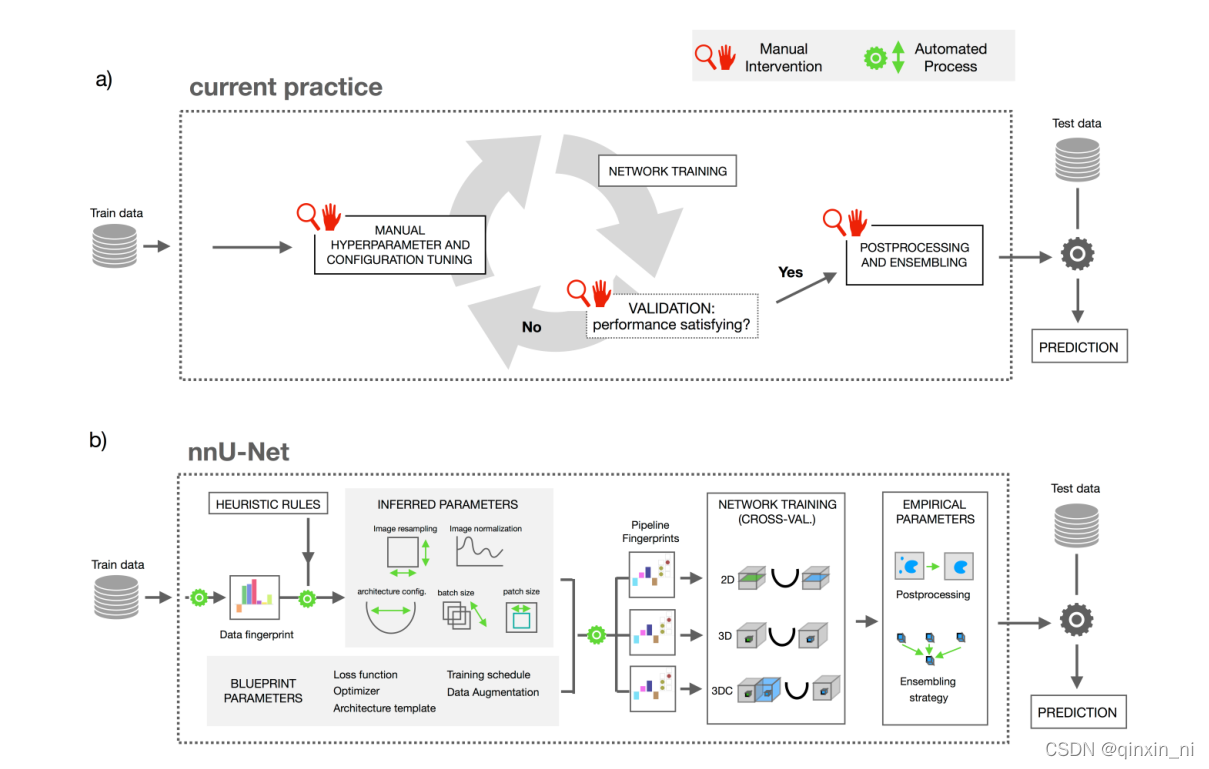
下图a代表了现在根据专家知识和实验修正的模型设计思路,针对于任务,
b代表nnUnet的设计思路,定义了dataset fingerprint和pipeline fingerprint。Dataset fingerprint是数据集的关键表征,比如图像大小、体素空间信息和类别比例;Pipeline fingerprint被分为三组:blueprint、inferred和empirical参数。Blueprint代表基本的架构设计,比如U-Net类的模板、损失函数、训练策略和数据增强;Inferd代表对新数据集的必要适应进行编码,并包括对确切的网络拓扑、补丁大小、批次大小和图像预处理的修改。数据指纹和inferd之间的关系是通过执行一组启发式规则建立的,当应用于看不见的数据集时,无需进行昂贵的重新优化。通过对训练案例进行交叉验证,可以自动确定empirical参数。默认情况下,nnU-Net会生成三种不同的U-Net配置:一个2D U-Net、一个以全图像分辨率运行的3D U-Net和一个3D U-Net级联。交叉验证后,nnU-Net会根据经验选择性能最佳的配置或整体。
2.1 Dataset Fingerprint(数据指纹)
1.整个训练的第一步是将即将要训练的数据集的前景给抠出来
2.nn U-Net跟通过得到的这个前景(crop),抓取它的相关参数,来组成dataset fingerprint(数据指纹),这些参数有:
Ⅰ. image_size: 每个空间维度上的体素的个数;
Ⅱ. image_spacing:每个体素的物理体积大小;
Ⅲ. 模态:头文件获取到的信息;
Ⅳ. 类别数:比如我是做单纯的二分类还多分类;
Ⅴ. 此外,还包括在所有训练案例上计算得到平均值、标准差以及属于任何标签的体素的灰度值的99.5%和0.5%(这部分灰度值的记录在plan.pkl中可以找到,简单的理解就是做归一化的一种行之有效的方式,通过找到训练集中每一套CT的前景像素值进行全局归一化)
2.2 Pipline Fingerprint(管道指纹)
nnUNet将所有应该进行设计的参数缩减到必要的那几个,并且使用启发性规则对这些参数进行推理,该规则集成了很多行业内专业的知识,同时对上面提到的“数据指纹”和本地的硬件约束都能起到作用。
这些得到的推理参数被两种参数所完善:
第一种:蓝图参数,具有数据独立性,不同数据的该参数不同;
第二种:经验参数,训练期间被优化
2.3 Blueprint parameters(蓝图参数)
2.3.1 结构设计
nnUNet配置的这几个不同的网络结构都来自于相同的网络模板,这个模板和原始的UNet及其3D版本十分的相近。我们的理论认为,一个配置完好的nnUNet仍然很难被打败,我们提出的网络架构没有使用任何最近十分流行的网络结构,只是进行了一点相对前者那种大刀阔斧的改动来说小的多的改变。为了适应更大的patch_size,nnUNet把网络的batch_size设计的更小。事实上,大多数3D-Unet的batch_size都只有2。Batch_normalization是用来干什么的呢?BN是用来加速训练同时保持训练稳定的,小的batch_size往往无法体现BN的价值。针对这种情况,我们所有的nnUNet的架构都使用了instance_normalization。更进一步的,我们用Leaky_Relu代替Relu(负轴上斜率为0.01)
2.3.2 深度监督训练
1.网络结构的一些改变:.除了解码阶段的最底下两层,我们给解码器的每一层都加了额外的损失,这样使得梯度信息能够更深层的注入网络,同时促进网络中所有层的训练。所有的Unet网络在同一个像素层次上,都用的一样的操作,无论是编码区还是在解码区(卷积 →instance_normalization →Leaky_Relu)。下采样是一个具有步幅长度的卷积,上采样是一次卷积的转置操作。为了平衡训练效果和显存消耗,最初的feature_map的大小被设定为32,如果要做一次下采样那么这个大小缩小一半,如果做上采样则会变成原来的两倍。为了限制最终生成的模型的大小,feature_map的数量也被做了一定的限制,比如,3D_Unet被限制在320而2D_Unet被限制在512。
2.训练时间表:
Ⅰ.根据以往的一些经验,同时为了增加训练的时效性,我们用一轮大于250的mini_batch,来把网络训练1000轮。随机梯度下降的方法采用μ = 0.99的nesterov的梯度下降,同时初始学习率为0.01.学习率的衰减遵循poly原则,即
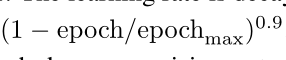
设计的损失函数是(交叉熵损失和 + dice_loss),所以你得到的损失最优为-1,只要是在下降的就是正确的,损失的最小值没有意义。
为了得到每一个深度监督的输出,它对应的每一次分割后mask的ground_truth都用来计算损失,训练的对象就是这每一层的损失的和:
![]()
根据这种方式,在每一次分辨率降低(下采样)时权重减半,就会使得:
![]()
同时将这些权重归一化到和为1
Ⅱ. mini_batch的样本都是从训练案例之中随机选择的,通过采用过采样的方式来控制样本不均衡的带来的稳定性问题:实施过采样是为了确保稳健地处理类失衡:66.7%的样本来自所选训练案例中的随机位置,而33.3%的patch被保证包含所选训练样本(随机选择)中存在的前景类之一
Ⅲ.在训练的运行过程中其实是用到了很多的数据增强的方法,如下:
- 旋转
- 缩放
- 高斯加噪
- 高斯模糊
- 亮度处理
- 对比度处理
- 低分辨率仿真
- Gamma(灰度系数)
3.推理部分
图像的推理预测是通过滑动窗口进行的,而窗口的大小等于训练时的patch_size,相邻的patch尺寸的预测(即滑动一次的两个块)具有一半的重叠比例。分割的准确率随着窗口边界的增大而降低。为了抑制拼接伪影,减少靠近边界位置的影响,采用高斯重要度加权,增加softmax聚合中中心体素的权重。通过沿所有轴进行镜像来增加测试时间,我将镜像去掉剪短了推理时间,一定程度上也损失了精度。
2.4 推理参数(Inferred Parameters)
2.4.1 色彩强度(灰度)归一化
nnUNet支持两种灰度归一化的方式:
- 对于除了CT之外的其他所有模态的归一化方法是z-scoring:在训练和推理过程中,先对每幅图像分别进行减去他们的强度平均值,同时除以他们的标准差来进行归一化。If cropping resulted inan average size decrease of 25% or more, a mask for central non-zero voxels is created and the normalization is applied within that mask only, ignoring the surrounding zero voxels(如果裁剪导致平均尺寸减少25%或更多,则创建中心体素不是0的mask(mask的大小?),并只在该掩模内应用标准化,忽略周围的零体素)
- 那么对于CT图的计算,就换用了另外一种方法:因为CT图的每一层各个像素的灰度值是一个定量并且反映的是该切片上的一些物理属性,因此这种有利于使用全局归一化的方式,来应用到所有的图片上面。To this end, nnU-Net uses the 0.5 and 99.5 percentiles of the foreground voxels for clipping as well as the global foreground mean a standard deviation for normalization on all images. 。
2.4.2 重采样
在一些数据集中,尤其是医学图像中,voxel_spacing(体素块间距)是一个非常重要的属性,而且这个属性通常是很多样的(有些厚有些薄)。但是我们卷积处理图像的时候是在处理一个数组或者tensor,是没有这个voxel_spacing的信息的,为了适应这种spacing很多样的特征,就需要用到一些插值算法,比如说三阶样条插值、线性插值、临近插值等。对于具备各向异性的图片(spacing最大的那个轴的spacing / spacing最小的那个轴的spacing 是大于3的)来说,平面内(x轴, y轴)的插值采用的是三阶样条插值,而平面外(z轴)的插值用的是最邻近插值。对z轴进行不同的插值方法会抑制重采样的伪影,比如如果voxel_spacing很大,那两个相邻切片的边缘的变化就通常很大。
对于分割图像的重采样其实是通过将他们转换成独热编码。每一个通道都要用一次线性插值,然后再用argmax对分割图片进行恢复。再者,对于各项异性图片来说,是在低分辨率的那几层进行最邻近插值。
重采样是怎么进行的
- 采样的对象:
- ① 训练时输入的标签和推理时输出的标签:独热编码后进行线性插值,
- ② 训练时输入的数据和推理时输入的数据:
- Ⅰ. 各向同性则不进行z轴的插值,xy使用临近插值;
- Ⅱ. 各向异性则对xy进行最邻近插值,对z进行三阶样条插值。
2.4.3 Target-Spacing(目标间距)
目标间距:选择的目标间距是一个关键参数。更大的间隔导致更小的图像,从而丢失细节,而更小的间隔导致更大的图像,阻止网络积累足够的上下文信息,因为patch的大小受到给定GPU内存预算的限制。虽然3D U-Net级联部分解决了这个问题,但仍然需要合理的目标间距来实现低分辨率和全分辨率。对于3D全分辨率U-Net, nnU-Net使用每个轴独立计算的训练用例中间隔的中值作为默认目标间距。对于各向异性数据集,这种默认会导致严重的插值伪影,或者由于训练数据在分辨率上的巨大差异而导致大量信息丢失。因此,当体素和间距各向异性(即最低间距轴与最高间距轴之比)均大于3时,在训练案例中,选择最低分辨率轴的目标间距为间距的第10个百分位。对于2D U-Net, nnU-Net通常在分辨率最高的两个轴上运行。如果三个轴都是各向同性的,则利用两个后向轴进行切片提取。目标间距是训练案例的中值间距(每个轴独立计算)。对于基于切片的处理,不需要沿面外轴重新采样。
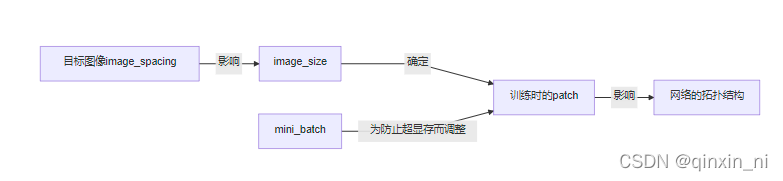
2.4.4 网络拓扑、patch_size 、batch_size的自适应性
- 寻找一个合适网络拓扑结构对于得到一个优秀的分割表现相当的重要。在一定的GPU显存的限制下,nnUNet优先选择一个大的patch_size,更大的patch_size会获取到更多的上下文的信息,这显然能提高模型的表现。但是,相对应的代价就是要减小batch_size(同时很大肯定占显存),而减小batch_size就会使反向传播的梯度下降变得不稳定(有时候学的好有时候学的坏,因为输入的不同batch的数据差距大)。为了提高训练的稳定性,我们提出一个值为2的mini_batch同时在网络训练时加入一个大的动量项(蓝图参数里有)。
- 图像的spacing也被作为自适应的一部分去考虑:
下采样的操作很可能只在某个特定的轴上进行操作,3D U-net的卷积核可能对特定的平面进行操作(伪2D)。所有U-Net配置的网络拓扑都是根据重新采样后图像尺寸的中值以及重新采样到的目标间距来选择的。附录E.1有一个流程图展示了这个自适应的流程。接下来会探讨更多的网络结构模板的自适应的细节,通常都不会以昂贵的计算力为代价。因为GPU的内存消耗估计是基于feature_map的大小,而这个适应过程和feature_map的关系很小,所以不需要GPU参与这个进程。
2.4.5 初始化(Initialization)
patch_size被初始化成重采样以后的图像尺寸的中位数,如果这个patch_size不能被
![]()
整除,那么将会对图像进行填充。
2.4.6 拓扑结构 (Architecture topology)
- 网络结构通过确定每根轴上的下采样次数,而这个下采样的次数,又取决于patch_size的大小和voxel_spacing的大小。
- 下采样会一直进行,除非上一个下采样会把feature_map的尺寸减小到4个体素以下,或者特征图的spacing是各向异性的。
- 采样策略是被体素间隔(voxel_spacing)来确定的,高分辨率轴分别向下采样,直到它们的分辨率在低分辨率轴的2倍之内,随后所有的轴同时进行下采样。所有轴的下采样是分别中止的,分别终止于他们的特征图的尺寸达到某个它们各自的限制条件。
- 3D_Unet和2D_Unet默认的卷积核的大小分别是3x3x3和3x3,分别地如果轴之间存在初始分辨率差异(定义为大于2的间距比),则平面外轴的内核大小将设置为1,直到分辨率在系数2内。请注意,对于所有轴,卷积内核大小保持为3。
2.4.7对GPU内存限制的自适应
patch_size的大小是根据GPU 的大小尽可能大的进行设定的。由于在重新采样后,patch_size的大小被初始化为图像尺寸的中值大小,所以对于大多数数据集来说,patch_size最初太大了,无法适应GPU。nnU-Net根据网络feature_map的大小来估计给定架构的内存消耗,并将其与已知内存消耗的参考值进行比较。然后在迭代过程中减少patch_size的大小,同时在每个步骤中相应地更新架构配置,直到达到所需的预算(参见附录E.1)。缩小patch_size的大小总是应用在数据相对于图像中值形状的最大轴上,一步中的减少相当于该轴的
![]()
其中nd是下采样操作的数量。
2.4.8 batch_size
最后一步是配置batch_size。如果执行了减少patch_size大小的操作,则批大小设置为2。否则,剩余的GPU内存空间将会用来增加batch_size,直到GPU被充分利用为止。为了防止过拟合,对batch_size进行了限制,使mini_batch中的体素总数不超过所有训练案例体素总数的5%。附录C1&C2给出了生成U-Net架构的例子。
2.4.7 3D_Unet_cascade是如何配置的
- 在下采样数据上进行模型分割增大了与图像相关的patch_size,这样可以使网络获取更多的上下文信息,但这是以牺牲模型在一些细节或者纹理上的分割表现为代价的。假设有一个显存无穷大的GPU,那么最好的patch_size应当覆盖整个图像大小。
- 3D-U-net-cascade是如何模拟patch_size无穷大这个过程:先用3D_Unet在下采样数据集上跑一个模型;再用一个全像素的3D_Unet来修正前者的分割效果;利用这种方法,低分辨率下采样层会获得更大的上下文信息,以此来生成它的分割输出,这个输出作为一个新的通道加入到下一个模块的输入中。
- 这个级联什么时候会被使用:
- 仅仅当3d_full_resolution的patch_size小于图像尺寸中值的12.5%使会使用级联,如果这个事件发生了,那么下采样数据的target_spacing和低分辨率部分的网络架构将会再一个迭代过程中被共同配置
- 这个迭代过程是这样的:初始化的target_spacing是全像素的target_spacing,为了让patch_size占据整个图的合适的一部分,在更新网络结构的过程中,逐渐每次增加1%的target_spacing,直到网络拓扑的patch_size超过目前图像尺寸中值的25%,如果目前的spacing是各向异性的(最低分辨率轴和最高分辨率轴之间的系数2差)那就只有更高分辨率的轴的spacing会被增大。
- 第二个3D_Unet的配置和独立的3D_Unet的上面的配置是一样的,除了第一个UNet的上采样的分割图与它的输入是condatenated。附录E.1b就是这个优化过程的描述。
2.5 经验参数(Empirical parameters)
- 推理模式:
- nnUNet会在推理时根据训练集中的验证dice表现来自动选择配置——是选择单个推理方式还是选择一起推理方式。
- 四种单个推理模式:2D、3D_full resolution、3Dliangl_lower resolution &the full resolution of the cascade。
- 合作推理模式:四个模式中两两进行组合来实现合作推理。
- nnUNet会在推理时根据训练集中的验证dice表现来自动选择配置——是选择单个推理方式还是选择一起推理方式。
- 后处理:Connected Components算法(连通分支算法)在医学图像领域非常常用,尤其是在器官分割中,经常用于去除最大的连接组件,从而来消除假阳性。nnU-Net同样用到这个方法,并自动对交叉验证中抑制较小组件的效果进行测试:首先所有的前景会被当做一个组件(多类别的1、2、3都被当做1),如果对除最大区域以外的所有分支的抑制提高了前景的平均dice而没有减小任何类别的dice,这一步将会被选择作为第一步的后处理步骤。最终,nnUNet会依靠这个步骤的表现来衡量要不要把相同的步骤用于不同的类别上。
3 结果
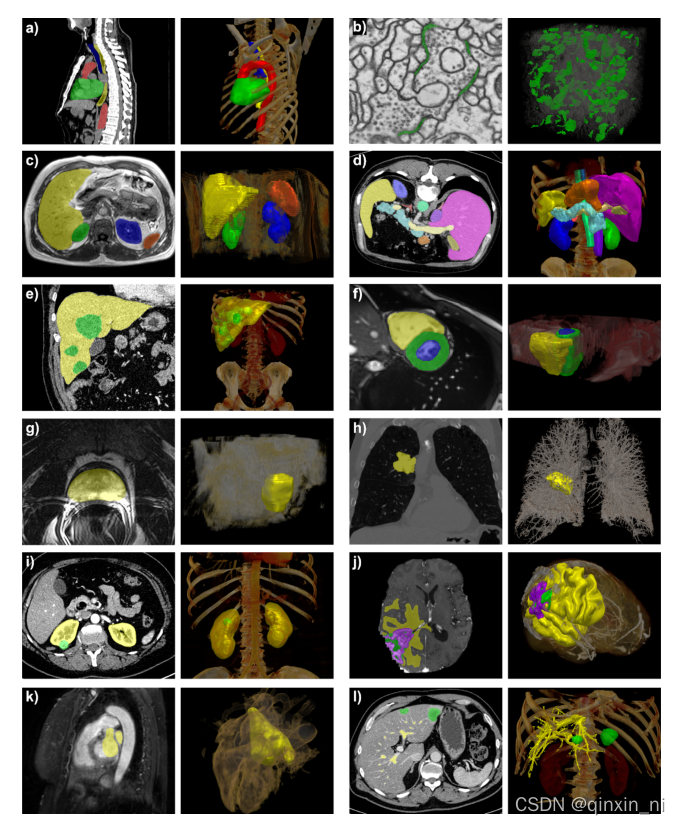
nnUNet是一个不需要任何实验设计和参数调节就可以为你训练3D医学图像的深度学习语义分割框架。一些对于比较典型的数据集的分割效果在下中展示。
1.nnUNet掌握了数据集的多样性和标签的属性: 以上所有的测试集都来自nnUNet对国际上各项挑战赛事的数据集的应用,左边是原数据的标签,右边是nnUNet模型的推理结果。所有这些可视化操作是在MITK上进行的。
2.人为调节的参数和本文提出的自动参数调节对比:
1) 最近普遍的深度学习的步骤:进行迭代式的训练和调参,训练之后评估结果,效果不好则进行调参,调参之后继续训练,最终进行侦测,反复如此;
2) nnUNet:
1.数据【无论是训练数据还是测试数据,都具有相对应的属性,即指纹】的属性会被总结成一种“数据指纹”;
2.一系列的启发式的规则会推理出适合这种指纹的“管道”(由蓝图参数(计划参数)推理得出):
3.上一步推理出的参数,例如image resample、batch_size等,联合起来成为“管道指纹”:
4.2D、3D和3D_Cascaded三个网络分别训练,得出各自的模型(三个网络结构共享一个“管道指纹”,五折交叉验证)
5.选择出最优的模型进行推理(可以单个进行推理,也可以三个模型一起进行推理)
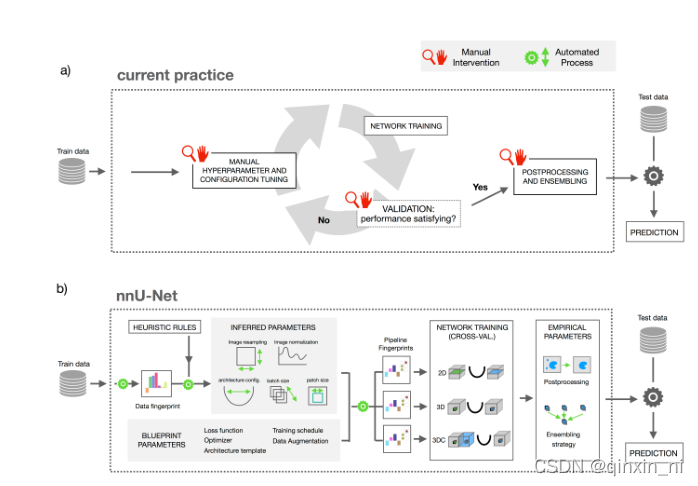
3.1 nnUNet可以自动适应任何新的数据
上图(a)展示了近来的多数医学图像分割是如何进行一个新的数据集的训练的。这个过程是“专家驱动”的,而且需要长时间的人为的试错的过程,显然,这样的训练方式对于手头上要处理的数据可能极少有先兆的参考。上图(b)中nnUNet却将这个自适应的过程系统化。
因此,我们在此定义了一个类似于“图片大小”这样的标准数据集的属性——dataset fingerprint(数据指纹),和一个pipeline fingerprint(管道指纹)[一个训练计划中各个配置的合体]。对于一个给定的“数据指纹”,nnUNet负责生成一个指定的“管道指纹”。
- 在nnUNet中,这些“管道指纹”被分为蓝图参数、推理参数和经验参数
- 蓝图参数:
- 基础的网络架构选择:比如一个朴素的nnUNet网络;
- 易于选择的一些表现较好的常用超参数:比如损失函数、训练进度表、数据增强方式;
- 推理参数
- 对一个新数据集进行适应性的编码,包括新的网络拓扑结构、patch_size、batch_size和图像预处理
- 数据指纹’和‘管道指纹’两者之间的关系可以通过执行一系列启发式的规则来进行建立,而且遇到未知的数据集时也不需要昂贵的反复训练的代价;
- 注意许多的设计选择都是相互依赖的
- nnUNet卸去了人为解释这些依赖关系的压力
- 经验参数:经验参数只会在后面的推理时使用,这点从上图b可以看出
- 2D、3D、3D-cascade
- 2D-Unet: 普通的2D-Unet
- 3D-Unet: 对一整张图片像素进行操作
- 3D-cascade: 级联网络:第一个网络对下采样图片进行操作,而第二个网络对前一个网络产生的结果在整个图片的像素上进行调整。
- 在进行完交叉验证之后,nnUNet会经验性的选择表现最好的参数,可能是独个的推理结果,也可能是一起推理的结果。在结果可以评估的情况下,把对次优效果的抑制作为一项后处理操作。
nnUNet的输出是自适应的,对于未知的数据集,训练完整的模型同样能够做良好的预测。我们通过网络平台对nnUNet背后的方法论进行了深入的描述。我们最重要的设计原则(也就是我们对一个新的数据集训练提出的建议),都在后面附录的B中。而所有分割任务的“管道”的手稿,都放在附录的F中。
3.2 不同的数据集需要不同“管道”配置
以下是nnUNet在19个数据集上的“管道指纹”(附录A),可见“管道指纹”体现了数据集的关键性质(displayed on z-score normalized scale)。数据集在他们的属性上体现出了巨大的差异,所以一方面需要很努力的适应不同的数据集,另一方面需要很大量的数据的支撑来得到其方法结论。右下角时三个模态。

我们抽取了19个实验数据集和相对应的“管道指纹”,并展示在图五中。这记录了在医学图像领域,数据集具有超乎寻常的复杂性。同时也暴露了为什么其他算法不如nnUNet的原因:
我们进行一次“管道指纹”的设计,要么就是人为的设置,要么就是利用各个“数据指纹”之间的隐藏关系进行设置。结果可能就是,对于一个数据集来说优化的效果很好,而对于其他数据集可能没有什么作用,对于一个新的数据集,就需要人为的不断的进行再建计划和再次优化。比如图片的尺寸会影响patch_size,patch_size会反过来影像网络的拓扑结构(下采样的次数和卷积核的尺寸等),而网络的拓扑结构将再次影响其他的超参数。
还有很多具体解释在附录部分:
参考:(一:2020.07.06)nnUNet论文主体解析(8.02更新认识)_Jojo论文基地-CSDN博客_nnunet
(二:2020.07.08)nnUNet方法解析(7.31更新认识)_Jojo论文基地-CSDN博客_nnunet结构
(三:2020.07.10)nnUNet附录解析(7.31更新认识)_Jojo论文基地-CSDN博客_nnunet


















 1801
1801

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









