







Heritrix的默认抓取策略为 HostnameQueueAssignmentPolicy,而这个策略是用hostname作为key的,因此一个域名下的所有连接都都会被放到同一个线程中去,这样就会造成在抓取时一般只有一个线程在运行(通常我们都是抓取特定网站上的内容)。这种方式在很大程度上可以解决广域网中信息抓取时队列的键值问题。但是,它对于某个单独网站的网页抓取,就出现了很大的问题。以Sina的新闻网页为例,其中大部分的URL都来自于Sina网站的内部,因此,如果使用了 HostnameQueueAssignmentPolicy,则会造成有一个队列的长度非常长的情况。在Heritrix中,一个线程从一个队列中取URL链接时,总是会先从队列的头部取出第一个链接,在这之后,这个被取出链接的队列会进入阻塞状态,直到待该链接处理完,它才会从阻塞状态中恢复。假如使用 HostnameQueueAssignmentPolicy策略来应对抓取一个网站中内容的情况,很有可能造成仅有一个线程在工作,而其他所有线程都在等待。这是因为那个装有绝大多数URL链接的队列几乎会永远处于阻塞状态,因此,别的线程根本获取不到其中的URL,在这种情况下,抓取工作会进入一种类似于休眠的状态。
因此,我们需要改变Heritrix的抓取策略,也就是改变key的生成方式,需要用这个key能够有效的把所有的URL散列到不同的队列中去,最终能够使所有队列的长度的方差变小,在这种情况下,才能保证工作线程的最大效率。我们就需要继承 QueueAssignmentPolicy类并重写 getClassKey()方法, getClassKey方法的参数为一个链接对象,而利用ELF Hash算法可以通过这个链接对象返回一个值,将其均匀分配到各个队列中去,就能够利用较多的线程抓取同一域名下的网页,抓取速度将会大大提高。
ELFHash算法是对字符串的散列,它巧妙地对字符的ASCII编码值进行计算,能够比较均匀地把字符串分布在散列表中。
1、下面是通过ELFHash算法实现的抓取策略:
package org.archive.crawler.frontier;
import java.util.logging.Level;
import java.util.logging.Logger;
import org.apache.commons.httpclient.URIException;
import org.archive.crawler.datamodel.CandidateURI;
import org.archive.crawler.framework.CrawlController;
import org.archive.net.UURI;
import org.archive.net.UURIFactory;
public class ELFHashQueueAssignmentPolicy extends QueueAssignmentPolicy {
private static final Logger logger = Logger.getLogger(ELFHashQueueAssignmentPolicy.class.getName());
/**
* When neat host-based class-key fails us
*/
private static String DEFAULT_CLASS_KEY = "default...";
private static final String DNS = "dns";
public String getClassKey(CrawlController controller, CandidateURI cauri) {
String scheme = cauri.getUURI().getScheme();
String candidate = null;
try {
if (scheme.equals(DNS)){
if (cauri.getVia() != null) {
// Special handling for DNS: treat as being
// of the same class as the triggering URI.
// When a URI includes a port, this ensures
// the DNS lookup goes atop the host:port
// queue that triggered it, rather than
// some other host queue
UURI viaUuri = UURIFactory.getInstance(cauri.flattenVia());
candidate = viaUuri.getAuthorityMinusUserinfo();
// adopt scheme of triggering URI
scheme = viaUuri.getScheme();
} else {
candidate= cauri.getUURI().getReferencedHost();
}
} else {
<span style="color:#3366ff;">// 注释掉原来的
// candidate = cauri.getUURI().getAuthorityMinusUserinfo();
// 使用ELFHash算法
String uri = cauri.getUURI().toString();
long hash = ELFHash(uri);
candidate = Long.toString(hash % 100); // 取模 100,Heritrix默认开100个线程,对应100个不同的URI处理队列</span>
}
if(candidate == null || candidate.length() == 0) {
candidate = DEFAULT_CLASS_KEY;
}
} catch (URIException e) {
logger.log(Level.INFO,
"unable to extract class key; using default", e);
candidate = DEFAULT_CLASS_KEY;
}
if (scheme != null && scheme.equals(UURIFactory.HTTPS)) {
// If https and no port specified, add default https port to
// distinguish https from http server without a port.
if (!candidate.matches(".+:[0-9]+")) {
candidate += UURIFactory.HTTPS_PORT;
}
}
// Ensure classKeys are safe as filenames on NTFS
return candidate.replace(':','#');
}
public long ELFHash(String str) {
long hash = 0;
long x = 0;
for (int i = 0; i < str.length(); i++) {
hash = (hash << 4) + str.charAt(i);
if ((x = hash & 0xF0000000L) != 0) {
hash ^= (x >> 24);
hash &= ~x;
}
}
return (hash & 0x7FFFFFFF);
}
}
2、在org.archive.crawler.frontier.AbstractFrontier类中查找“HostnameQueueAssignmentPolicy”关键字,大概在293行,注释掉改行,然后添加我们的ELFHashQueueAssignmentPolicy,如下(蓝色字体的行):
// Read the list of permissible choices from heritrix.properties.
// Its a list of space- or comma-separated values.
String queueStr = System.getProperty(AbstractFrontier.class.getName() +
"." + ATTR_QUEUE_ASSIGNMENT_POLICY,
// HostnameQueueAssignmentPolicy.class.getName() + " " +
ELFHashQueueAssignmentPolicy.class.getName() + " " +</span>
IPQueueAssignmentPolicy.class.getName() + " " +
BucketQueueAssignmentPolicy.class.getName() + " " +
SurtAuthorityQueueAssignmentPolicy.class.getName() + " " +
TopmostAssignedSurtQueueAssignmentPolicy.class.getName());
Pattern p = Pattern.compile("\\s*,\\s*|\\s+");
String [] queues = p.split(queueStr);3、修改heritrix.properties文件中的配置,在该文件中查找”HostnameQueueAssignmentPolicy“关键字,大概在159、160两行,复制后注释掉这两行,并粘贴到下面,替换这两行中”HostnameQueueAssignmentPolicy“为”ELFHashQueueAssignmentPolicy“,如下(蓝色的字体):
#org.archive.crawler.frontier.AbstractFrontier.queue-assignment-policy = org.archive.crawler.frontier.HostnameQueueAssignmentPolicy org.archive.crawler.frontier.IPQueueAssignmentPolicy org.archive.crawler.frontier.BucketQueueAssignmentPolicy org.archive.crawler.frontier.SurtAuthorityQueueAssignmentPolicy org.archive.crawler.frontier.TopmostAssignedSurtQueueAssignmentPolicy
# org.archive.crawler.frontier.HostnameQueueAssignmentPolicy org.archive.crawler.frontier.IPQueueAssignmentPolicy org.archive.crawler.frontier.BucketQueueAssignmentPolicy org.archive.crawler.frontier.SurtAuthorityQueueAssignmentPolicy org.archive.crawler.frontier.TopmostAssignedSurtQueueAssignmentPolicy
org.archive.crawler.frontier.AbstractFrontier.queue-assignment-policy = org.archive.crawler.frontier.ELFHashQueueAssignmentPolicy org.archive.crawler.frontier.IPQueueAssignmentPolicy org.archive.crawler.frontier.BucketQueueAssignmentPolicy org.archive.crawler.frontier.SurtAuthorityQueueAssignmentPolicy org.archive.crawler.frontier.TopmostAssignedSurtQueueAssignmentPolicy
org.archive.crawler.frontier.ELFHashQueueAssignmentPolicy org.archive.crawler.frontier.IPQueueAssignmentPolicy org.archive.crawler.frontier.BucketQueueAssignmentPolicy org.archive.crawler.frontier.SurtAuthorityQueueAssignmentPolicy org.archive.crawler.frontier.TopmostAssignedSurtQueueAssignmentPolicy
org.archive.crawler.frontier.IPQueueAssignmentPolicy \
org.archive.crawler.frontier.BucketQueueAssignmentPolicy \
org.archive.crawler.frontier.SurtAuthorityQueueAssignmentPolicy \
org.archive.crawler.frontier.TopmostAssignedSurtQueueAssignmentPolicy
org.archive.crawler.frontier.BdbFrontier.level = INFO下面用这个两个抓取策略分别创建抓取任务,做一个对比:
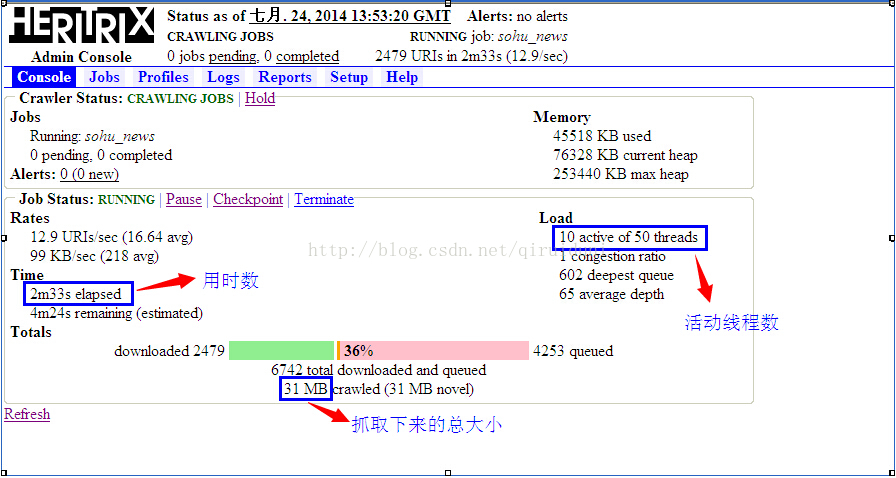
下图是用HostnameQueueAssignmentPolicy抓取策略创建的任务的状态图:
下图是用ELFHashQueueAssignmentPolicy抓取策略创建的任务的状态图:
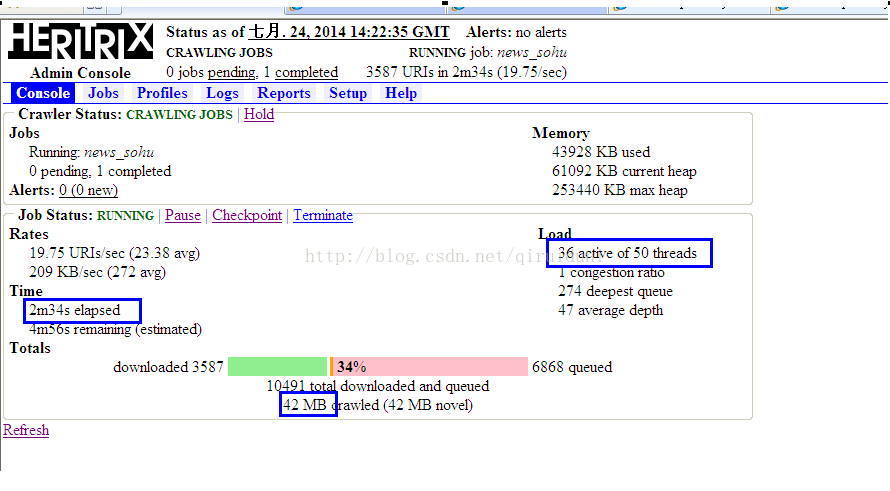
从上面两图中可以看出,在相同时间里,在活动线程数量和抓取的总大小,ELFHashQueueAssignmentPolicy比HostnameQueueAssignmentPolicy都要高很多。
注:使用ELFHashQueueAssignmentPolicy抓取策略时,可能会遇到抓取停止的现象,查看任务的crawl.log日志,URL后带有”robots.txt“字样,如:”http://news.sohu.com/robots.txt“,这是由于Heritrix是一个完全遵守”robots.txt“协议的网络爬虫,如果一个网站在该文件中声明了不想被robot访问的部分,那么Heritrix是不会爬取这些内容的。可以去除robots.txt的限制,就应该没有这种现象了。
b、取消rebots.txt的限制。
关于取消rebots.txt协议,可以参考另一篇文章:http://blog.csdn.net/qiruiduni/article/details/38097379
c、抓取指定网页内容
Heritrix 的Extractors,用于解析当前服务器返回的内容,抽取页面中的URL,放入抽取队列中。因为它会抓取网页中所有的链接,但有些链接不是我们想要的,例如图片、pdf文档等的链接,需要把这些链接过滤掉,我们可以创建自己的Extractor,用于抓取特定的网页内容。如下,是一个用于抓取sohu新闻的自定Extractor:
package org.archive.crawler.extractor;
import java.io.IOException;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import org.archive.crawler.datamodel.CrawlURI;
import org.archive.io.ReplayCharSequence;
import org.archive.util.HttpRecorder;
public class ExtractorSohu extends Extractor {
private static final long serialVersionUID = -7914995152462902519L;
public ExtractorSohu(String name, String description) {
super(name, description);
}
public ExtractorSohu(String name) {
super(name, "sohu news extractor");
}
// http://news.sohu.com/20131020/n388534488.shtml
private static final String A_HERF = "<a(.*)href\\s*=\\s*(\"([^\"]*)\"|[^\\s>])(.*)>";
private static final String NEWS_SOHU = "http://news.sohu.com/(.*)/n(.*).shtml";
@Override
protected void extract(CrawlURI curi) {
String url = "";
try {
HttpRecorder hr = curi.getHttpRecorder();
if(hr == null){
throw new IOException("HttpRecorder is null");
}
ReplayCharSequence cs = hr.getReplayCharSequence();
if(cs == null){
return;
}
String context = cs.toString();
Pattern pattern = Pattern.compile(A_HERF, Pattern.CASE_INSENSITIVE);
Matcher matcher = pattern.matcher(context);
while(matcher.find()){
url = matcher.group(2);
url = url.replace("\"", "");
if(url.matches(NEWS_SOHU)){
curi.createAndAddLinkRelativeToBase(url, context, Link.NAVLINK_HOP);
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
创建自定义的Extractor后,需要在“modules/Processor.options”文件中注册下,用于在UI页面中设置。如下图:

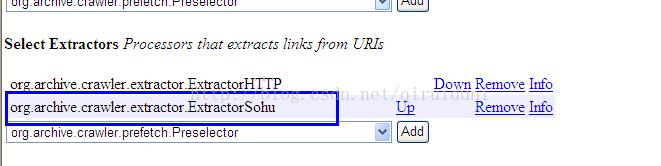
在创建抓取任务时,记得添加我们自定义的Extractor,否则是不起作用的,如下图:
至此,Heritrix 的优化暂时就这些。















 919
919

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









