







a、类和构造函数
在Scala中通过class关键字声明一个类,如下:
<scala> class MongoClient(val host:String, val port:Int)这看起来和java有些不同,Scala的类名后带有参数,表示在声明类的同时,也创建了主构造函数。当在创建MongoClient实例时,需要直接或间接从重载的构造函数中调用主构造函数。
在Scala中声明主构造函数是嵌入在定义类的代码中的。构造函数中定义的参数,可以看做类的属性,并且无需像JavaBean那样为类的属性创建相应的set/get方法。参数的前缀可以为val或var,当为val时,将创建一个不可以变的实例,当为var时,将创建一个可变的实例。如果val和var都没有,将创建一个私有的实例,该实例对其它的类是不可访问的,如下:
scala> class MongoClient(host:String, port:Int)
defined class MongoClient
scala> val client = new MongoClient("localhost", 123)
client: MongoClient = MongoClient@4089f3e5
scala> client.host
<console>:7: error: value host is not a member of MongoClient
client.hostclass MongoClient(val host:String, val port:Int) {
def this() = this("127.0.0.1", 27017)
}在Scala中,packing(包)也是一个对象,作为类和对象的集合,用于对编写的代码进行逻辑分组或命名空间,避免相互冲突。它混合采用了java和C#的包声明方式,当然可以根据自己的喜好,采用java的方式来定义包。如下的几种定义包的方式:
java风格:
package com.scalainaction.mongo
import com.mongodb.Mongo
class MongoClient(val host:String, val port:Int) {
require(host != null, "You have to provide a host name")
private val underlying = new Mongo(host, port)
def this() = this("127.0.0.1", 27017)
}<pre name="code" class="html">package com.scalainaction.mongo {
import com.mongodb.Mongo
class MongoClient(val host:String, val port:Int) {
require(host != null, "You have to provide a host name")
private val underlying = new Mongo(host, port)
def this() = this("127.0.0.1", 27017)
}
}或者
<pre name="code" class="html">package com {
package scalainaction {
package mongo {
import com.mongodb.Mongo
class MongoClient(val host:String, val port:Int) {
require(host != null, "You have to provide a host name")
private val underlying = new Mongo(host, port)
def this() = this("127.0.0.1", 27017)
}
}
}
}包对象
package com.persistence {
package mongo {
class MongoClient
}
package riak {
class RiakClient
}
package hadoop {
class HadoopClient
}
}包对象的一个用处是可以在包中定义一些辅助方法,这样在包中的所有成员都可以使用。如下:
package.scala文件:
package object bar {
val minimumAge = 18
def verifyAge = {}
}<pre name="code" class="html">BarTender.scala文件:package bar
class BarTender {
def serveDrinks = { verifyAge; ... }
}c、导入
Scala的导入和java的导入很像,都是通过import关键字来导入引用的类,但又有些不同,例如:
导入某包下的所有类是用“_”:import com.mongodb._
看下面的例子:
package monads { class IOMonad }
package io {
package monads {
class Console { val m = new monads.IOMonad }
}
}val m = new _root_.monads.IOMonad另外,如果创建的类或对象没有包的声明,那么它们就属于empty package包,而empty package包是不能导入的,但是empty package包中的成员是可以相互看的见的。
有时,会导入不同包中的同名的类,很容易造成混淆,这时可以通过指定别名的方式来加以区分,如下:import java.util.Date
import java.sql.{Date => SqlDate}
import RichConsole._
val now = new Date
p(now)
val sqlDate = new SqlDate(now.getTime)
p(sqlDate)
d、对象和伴生对象(Objects and companion objects)
Scala是一种纯面向对象的语言,每个值都是对象,每个操作都是方法调用,每个变量都是某些对象的成员。Scala中没有static修饰符,因为这不符合它纯面向对象的设计目标,并且在代码中使用static修饰符可能会有副作用。相反,Scala通过single object(单例对象)来替代static。Scala创建single object是挺简单的,如下:
object RichConsole {
def p(x: Any) = println(x)
}伴生对象
在Scala中,当一个对象和一个类同名时,这个对象叫做companion object(伴生对象),这个类叫做companion class(伴生类)。如下:
package com.scalainaction.mongo
import com.mongodb.{DB => MongoDB}
class DB private(val underlying: MongoDB) {
}
object DB {
def apply(underlying: MongoDB) = new DB(underlying)
}首先,DB类的主构造函数声明为private,意味着其他的类或对象都不能使用它,除了companion object(伴生对象)。在Scala中,只有伴生对象可以访问伴生类中的私有成员,其它的外部类都不可以访问。
Scala的特质(trait)可以起到代码复用的作用,它和抽象类很相似,可以定义成员变量、抽象方法和具体方法,不同的是抽象类可以有构造参数,而trait不可以带有任何参数。另外,与类的继承不同(每一个类只能继承一个类),一个类可以混入任意多的trait,这又和java的接口很相似。
通常,trait以混入(mixin)的方式混入到类中,可以使用extends或with关键字把trait 混入(mixin)到类中,这里的混入和其它语言的多重继承有重要的差别。使用extend关键字混入trait,这种情况下隐式地继承了trait的超类。使用with关键字混入trait,此时的类还可以继承其他的类。
混入的顺序很重要,越靠近右侧的特质越先起作用。当你调用带混入的类的方法时,最右侧特质的方法首先被调用,如果那个方法调用了super,它调用其左侧特质的方法,以此类推。
另外,特质还可以作为类型,在定义变量时可以指定变量的类型为trait类型。
特质主要有两种常用的使用方式,一种是把瘦接口(接口中定义的方法较少)转变为胖接口(接口中定义的方法较多)。另一种是为类提供可堆叠的改变。这两种使用方式下面会做详细介绍。
1、类线性化
先看个问题:UpdatableCollection 类继承了DBCollection类,同时又混入Updatable特质,而DBCollection类和Updatable特质都继承了ReadOnly特质,ReadOnly中有一具体的实现方法find(),那么在UpdatableCollection类中调用find()方法,将产生歧义,因为有两条路径可以到达ReadOnly特质。看具体的示例:
class UpdatableCollection extends DBCollection(collection(name)) with Updatable
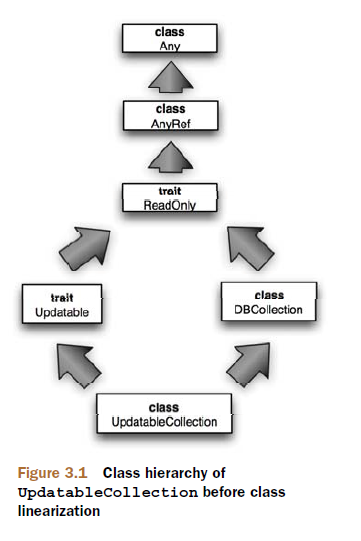
Scala通过使用类的线性化类处理这种问题,类线性化指定了类到达祖先类(Any类)的一条路径,其中包括普通的超类和特质。通常采用先从最右侧(为类声明语句的最右侧),深度优先搜索,去掉除在层次结构中最后一个匹配的类,来确定类线性化的路径。
Scala中所有类的超类为Any(相当于Java中的Object类)。从上图可以判断每个对象的线性化路径为:
特质ReadOnly :ReadOnly -> AnyRef -> Any
特质Updatable :Updatable -> ReadOnly -> AnyRef -> Any
类DBCollection : DBCollection -> ReadOny -> AnyRef -> Any
类UpdatableCollection :UpdatableCollection -> Updatable -> DBCollection -> ReadOnly -> AnyRef -> Any
---------------------------------------------------------------
另一个例子:假设你有一个类 Cat,继承自超类 Animal 以及两个特质 Furry 和 FourLegged, FourLegged 又扩展了另一个特质 HasLegs。
class Animal
trait Furry extends Animal
trait HasLegs extends Animal
trait FourLegged extends HasLegs
class Cat extends Animal with Furry with FourLegged
当这些类和特质中的任何一个通过super调用了方法,那么被调用的实现将是它线性化的右侧的第一个实现。

2、堆叠
Scala特质的堆叠特性,可以在不修改现有组件的前提下,添加或修改组件的行为。
f、Case Class(样本类)
Scala中,Case Class是一种特殊的类,通过使用case修饰符创建样本类,当编译器在编译时遇到case class时,会自动生成一些样本代码,如下:
1、构造函数的参数默认为val修饰符,意味着这些参数为public成员。
2、自动生成hashCode、equals、toString方法。
3、自动生成的copy()方法,可以较简便的创建类实例的完整或部分变更副本。
4、每个Case类默认都实现了scala.Product特质和scala.Serializable特质。
5、每个Case类都带有apply()和unapply()方法,这样在创建类实例时,就不用通过new 关键字,可以直接使用类名加参数来创建。
像其它的类一样,Case类也可以继承其它类,包括特质和Case类,但是,当Case类定义为abstract case class时,编译器将不会再为其自动生成apply()方法,因为抽象类不可以被实例化。另外,还可以创建case object,这样该object就为单例对象和序列化的了,这种情况通常用于在网络上传送消息,并发编程时比较常用。
Case Class 常用于模式匹配,如下例子:
scala> case class Person(firstName:String, lastName: String)
defined class Person
scala> val p = Person("Matt", "vanvleet")
p: Person = Person(Matt,vanvleet)
scala> p match {
case Person(first, last) => println(">>>> " + first + ", " + last)
}
>>>> Matt, vanvleet
object Person {
def apply(firstName:String, lastName:String) = {
new Person(firstName, lastName)
}
def unapply(p:Person): Option[(String, String)] =
Some((p.firstName, p.lastName))
}g、命名参数、默认参数、复制构造函数(copy constructor)
命名参数
通常,在调用函数时,参数传入是按定义时的参数顺序来传递的,从Scala2.8开始,Scala提供了一种可以通过参数名来传递值,这样就可以按任意顺序来出入参数了。这样做可以避免传入同类型的参数时混淆参数的含义,同时也增强了可读性。如下例:
按顺序传入参数:
scala> case class Person(firstName:String, lastName:String)
defined class Person
scala> val p = Person("lastname", "firstname")
p: Person = Person(lastname,firstname)scala> val p = Person(lastName = "lastname", firstName = "firstname")
p: Person = Person(firstname,lastname)默认参数的定义形式为arg: Type = expression,如:def methodA(name: String = "xxx"),当调用methodA()时,“name”就会使用默认值“xxx”
复制构造函数
命名参数和默认参数一个非常有用的运用是编译器自动为case类生成copy方法。这个方法采取一种轻量级的语法来创建一个原始实例的修改拷贝。copy方法具有和被拷贝的case类的基本构造方法同样类型和参数,并且每个参数都使用基本构造方法中相应值作为默认值。
case class A[T](a: T, b: Int) {
// def copy[T'](a: T' = this.a, b: Int = this.b): A[T'] = new A[T'](a, b)
}
val a1: A[Int] = A(1, 2)
val a2: A[String] = a1.copy(a = "someString")Java中的访问修饰符有四种private(私有的)、protected(受保护的)、public(公共的)、包级别(默认没有任何修饰符),而在Scala中同样也有这几种修饰符,不同的是
Scala中包、类或对象的访问修饰符默认为public,并且在某种程度上,基本废除了包级别的访问限制。
private修饰符仅可以对类内部成员、伴生对象或伴生类可见。见下例:
class Outer {
class Inner {
private def f() { println("f") }
class InnerMost {
f() // OK
}
}
(new Inner).f() // Error: f is not accessible
}package outerpkg.innerpkg
class Outer {
class Inner {
private[Outer] def f() = "This is f"
private[innerpkg] def g() = "This is g"
private[outerpkg] def h() = "This is h"
}
}另外还可以对this对象限定修饰符,这样,this就为私有对象,表示仅可以被同一对象调用。
protected修饰符仅可以被定义他的类及其子类,还有伴生对象及伴生对象的所有子类访问。protected同样也可以作用于包、类、this。
同Java一样,Scala也提供了override修饰符,用于重写父类成员,不同的是Scala中的override修饰符是强制的。另外,override还可以和abstract修饰符组合,这种情况只适用于特质(trait),并且混入此特质的类或特质必须要有一个具体的实现。如下:
trait DogMood {
def greet
}
trait AngryMood extends DogMood {
override def greet = {
println("bark")
super.greet // Error
}
}
trait AngryMood extends DogMood {
abstract override def greet = {
println("bark")
super.greet
}
}另外,Scala还提供了一个新的修饰符:sealed(密封),该修饰符主要有2个作用:
1、其修饰的trait,class只能在当前文件里面被继承。
2、用sealed修饰这样做的目的是告诉scala编译器在检查模式匹配的时候,让scala知道这些case的所有情况,scala就能够在编译的时候进行检查,看你写的代码是否漏掉什么没case项,减少编程的错误。
i、值类(value class)
详见http://blog.csdn.net/qiruiduni/article/details/46763759
j、隐式类
k、继承体系















 688
688

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









