import pandas
titanic = pandas.read_csv("D:\\test\\titanic_train.csv" )
print titanic.describe() PassengerId Survived Pclass Age SibSp \
count 891.000000 891.000000 891.000000 714.000000 891.000000
mean 446.000000 0.383838 2.308642 29.699118 0.523008
std 257.353842 0.486592 0.836071 14.526497 1.102743
min 1.000000 0.000000 1.000000 0.420000 0.000000
25% 223.500000 0.000000 2.000000 NaN 0.000000
50% 446.000000 0.000000 3.000000 NaN 0.000000
75% 668.500000 1.000000 3.000000 NaN 1.000000
max 891.000000 1.000000 3.000000 80.000000 8.000000
Parch Fare
count 891.000000 891.000000
mean 0.381594 32.204208
std 0.806057 49.693429
min 0.000000 0.000000
25% 0.000000 7.910400
50% 0.000000 14.454200
75% 0.000000 31.000000
max 6.000000 512.329200
C:\Users\qiujiahao\Anaconda2\lib\site-packages\numpy\lib\function_base.py:3834: RuntimeWarning: Invalid value encountered in percentile
RuntimeWarning)
titanic["Age" ] = titanic["Age" ].fillna(titanic["Age" ].median())
print titanic.describe() PassengerId Survived Pclass Age SibSp \
count 891.000000 891.000000 891.000000 891.000000 891.000000
mean 446.000000 0.383838 2.308642 29.361582 0.523008
std 257.353842 0.486592 0.836071 13.019697 1.102743
min 1.000000 0.000000 1.000000 0.420000 0.000000
25% 223.500000 0.000000 2.000000 22.000000 0.000000
50% 446.000000 0.000000 3.000000 28.000000 0.000000
75% 668.500000 1.000000 3.000000 35.000000 1.000000
max 891.000000 1.000000 3.000000 80.000000 8.000000
Parch Fare
count 891.000000 891.000000
mean 0.381594 32.204208
std 0.806057 49.693429
min 0.000000 0.000000
25% 0.000000 7.910400
50% 0.000000 14.454200
75% 0.000000 31.000000
max 6.000000 512.329200
print titanic["Sex" ].unique()
titanic.loc[titanic["Sex" ]=="male" ,"Sex" ] = 0
titanic.loc[titanic["Sex" ]=="female" ,"Sex" ] = 1 ['male' 'female']
print titanic["Embarked" ].unique()
titanic["Embarked" ] = titanic["Embarked" ].fillna('S' )
titanic.loc[titanic["Embarked" ]=="S" ,"Embarked" ] = 0
titanic.loc[titanic["Embarked" ]=="C" ,"Embarked" ] = 1
titanic.loc[titanic["Embarked" ]=="Q" ,"Embarked" ] = 2 ['S' 'C' 'Q' nan]
from sklearn.linear_model import LinearRegression
from sklearn.cross_validation import KFold
predictors = ["Pclass" ,"Sex" ,"Age" ,"SibSp" ,"Parch" ,"Fare" ,"Embarked" ]
alg = LinearRegression()
kf = KFold(titanic.shape[0 ],n_folds=3 ,random_state=1 )
predictions = []
for train,test in kf:
train_predictors = titanic[predictors].iloc[train,:]
train_target = titanic["Survived" ].iloc[train]
alg.fit(train_predictors,train_target)
test_predictors = alg.predict(titanic[predictors].iloc[test,:])
predictions.append(test_predictors)import numpy as np
predictions = np.concatenate(predictions,axis=0 )
predictions[predictions>.5 ] = 1
predictions[predictions<=.5 ]= 0
accuracy = sum(predictions[predictions == titanic["Survived" ]])/len(predictions)
print accuracy0.783389450056
C:\Users\qiujiahao\Anaconda2\lib\site-packages\ipykernel\__main__.py:7: FutureWarning: in the future, boolean array-likes will be handled as a boolean array index
from sklearn import cross_validation
from sklearn.linear_model import LogisticRegression
alg = LogisticRegression(random_state=1 )
scores = cross_validation.cross_val_score(alg,titanic[predictors],titanic["Survived" ],cv=3 )
print (scores.mean())0.787878787879
from sklearn import cross_validation
from sklearn.ensemble import RandomForestClassifier
predictors = ["Pclass" ,"Sex" ,"Age" ,"SibSp" ,"Parch" ,"Fare" ,"Embarked" ]
alg = RandomForestClassifier(random_state=1 ,n_estimators=10 ,min_samples_split=2 ,min_samples_leaf=1 )
kf = cross_validation.KFold(titanic.shape[0 ],n_folds=3 ,random_state=1 )
scores = cross_validation.cross_val_score(alg,titanic[predictors],titanic["Survived" ],cv=kf)
print (scores.mean())0.785634118967
alg = RandomForestClassifier(random_state=1 ,n_estimators=50 ,min_samples_split=4 ,min_samples_leaf=2 )
kf = cross_validation.KFold(titanic.shape[0 ],n_folds=3 ,random_state=1 )
scores = cross_validation.cross_val_score(alg,titanic[predictors],titanic["Survived" ],cv=kf)
print (scores.mean())0.81593714927
titanic["FamilySize" ] = titanic["SibSp" ] + titanic["Parch" ]
titanic["NameLength" ] = titanic["Name" ].apply(lambda x:len(x))
import re
def get_title (name) :'([A-Za-z]+)\.' ,name)
if title_search:
return title_search.group(1 )
return ""
titles = titanic["Name" ].apply(get_title)
print (pandas.value_counts(titles))
print "......................."
title_mapping = {"Mr" :1 ,"Miss" :2 ,"Mrs" :3 ,"Master" :4 ,"Dr" :5 ,"Rev" :6 ,"Major" :7 ,"Col" :7 ,"Mlle" :8 ,"Mme" :8 ,"Don" :9 ,
"Lady" :10 ,"Countess" :10 ,"Jonkheer" :10 ,"Sir" :9 ,"Capt" :7 ,"Ms" :2 }
for k,v in title_mapping.items():
titles[titles==k]=v
print (pandas.value_counts(titles))
print "......................."
titanic["Title" ] = titles
print titanic["Title" ]Mr 517
Miss 182
Mrs 125
Master 40
Dr 7
Rev 6
Col 2
Major 2
Mlle 2
Countess 1
Ms 1
Lady 1
Jonkheer 1
Don 1
Mme 1
Capt 1
Sir 1
Name: Name, dtype: int64
.......................
1 517
2 183
3 125
4 40
5 7
6 6
7 5
10 3
8 3
9 2
Name: Name, dtype: int64
.......................
0 1
1 3
2 2
3 3
4 1
5 1
6 1
7 4
8 3
9 3
10 2
11 2
12 1
13 1
14 2
15 3
16 4
17 1
18 3
19 3
20 1
21 1
22 2
23 1
24 2
25 3
26 1
27 1
28 2
29 1
..
861 1
862 3
863 2
864 1
865 3
866 2
867 1
868 1
869 4
870 1
871 3
872 1
873 1
874 3
875 2
876 1
877 1
878 1
879 3
880 3
881 1
882 2
883 1
884 1
885 3
886 6
887 2
888 2
889 1
890 1
Name: Title, dtype: object
import numpy as np
from sklearn.feature_selection import SelectKBest,f_classif
import matplotlib.pyplot as plt
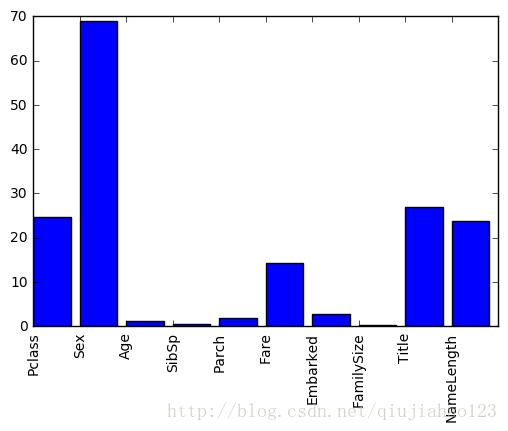
predictors = ["Pclass" ,"Sex" ,"Age" ,"SibSp" ,"Parch" ,"Fare" ,"Embarked" ,"FamilySize" ,"Title" ,"NameLength" ]
seletor = SelectKBest(f_classif,k=5 )
seletor.fit(titanic[predictors],titanic["Survived" ])
scores = -np.log10(seletor.pvalues_)
plt.bar(range(len(predictors)),scores)
plt.xticks(range(len(predictors)),predictors,rotation="vertical" )
plt.show()
predictors = ["Pclass" ,"Sex" ,"Fare" ,"Title" ]
alg = RandomForestClassifier(random_state=1 ,n_estimators=50 ,min_samples_split=4 ,min_samples_leaf=2 )
kf = cross_validation.KFold(titanic.shape[0 ],n_folds=3 ,random_state=1 )
scores = cross_validation.cross_val_score(alg,titanic[predictors],titanic["Survived" ],cv=kf)
print (scores.mean())0.814814814815
from sklearn.ensemble import GradientBoostingClassifier
import numpy as np
algorithms = [
[GradientBoostingClassifier(random_state=1 ,n_estimators=25 ,max_depth=3 ),["Pclass" ,"Sex" ,"Age" ,"Fare" ,"Embarked" ,"FamilySize" ,"Title" ]],
[LogisticRegression(random_state=1 ),["Pclass" ,"Sex" ,"Fare" ,"FamilySize" ,"Title" ,"Age" ,"Embarked" ]]
]
kf = KFold(titanic.shape[0 ],n_folds=3 ,random_state=1 )
predictions = []
for train,test in kf:
train_target = titanic["Survived" ].iloc[train]
full_test_predictions = []
for alg,predictors in algorithms:
alg.fit(titanic[predictors].iloc[train,:],train_target)
test_predictions = alg.predict_proba(titanic[predictors].iloc[test,:].astype(float))[:,1 ]
full_test_predictions.append(test_predictions)
test_predictions = (full_test_predictions[0 ] + full_test_predictions[1 ])/2
test_predictions[test_predictions<=.5 ]=0
test_predictions[test_predictions>.5 ] =1
predictions.append(test_predictions)
predictions = np.concatenate(predictions,axis=0 )
accuracy = sum(predictions[predictions == titanic["Survived" ]])/len(predictions)
print accuracy
0.821548821549
C:\Users\qiujiahao\Anaconda2\lib\site-packages\ipykernel\__main__.py:27: FutureWarning: in the future, boolean array-likes will be handled as a boolean array index























 5814
5814

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









