







 本文介绍了如何使用机器学习方法,通过Titanic数据集预测乘客的获救概率。文章详细讲述了数据预处理、特征选择(包括年龄、性别、登船港口等)、模型应用(线性回归、逻辑回归和随机森林)以及参数优化的过程。
本文介绍了如何使用机器学习方法,通过Titanic数据集预测乘客的获救概率。文章详细讲述了数据预处理、特征选择(包括年龄、性别、登船港口等)、模型应用(线性回归、逻辑回归和随机森林)以及参数优化的过程。
目录
机器学习项目实战(一)
Titanic数据集乘客获救预测
背景:
背景说明:泰坦尼克沉船是震惊世界的海难事件,1912年4月15日,在它的处女航中,撞上冰川后沉没。造成了超过1502人死亡,该事件也引起了全世界对于船舶安全法规的重视。在这场灾难中,有一些因素也导致了部分乘客的获救机率比较高,如老人,小孩,上流阶层,我们的目标是利用机器学习算法对获救乘客就行准确的预测。
数据预处理
# 导入第三方库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
# 全文忽略警告
import warnings
warnings.filterwarnings('ignore')
# 导入数据
df_train =pd.read_csv('sklearn/项目一:Titanic数据集乘客获救预测/train.csv')
df_test =pd.read_csv('sklearn/项目一:Titanic数据集乘客获救预测/test.csv')
# 查看数据组成情况
print(df_train.shape,df_test.shape)

该数据集由两部分组成:
训练集:891条 测试集:418条
# 查看数据
df_train.head()

# 查看数据字段类型
df_train.info()
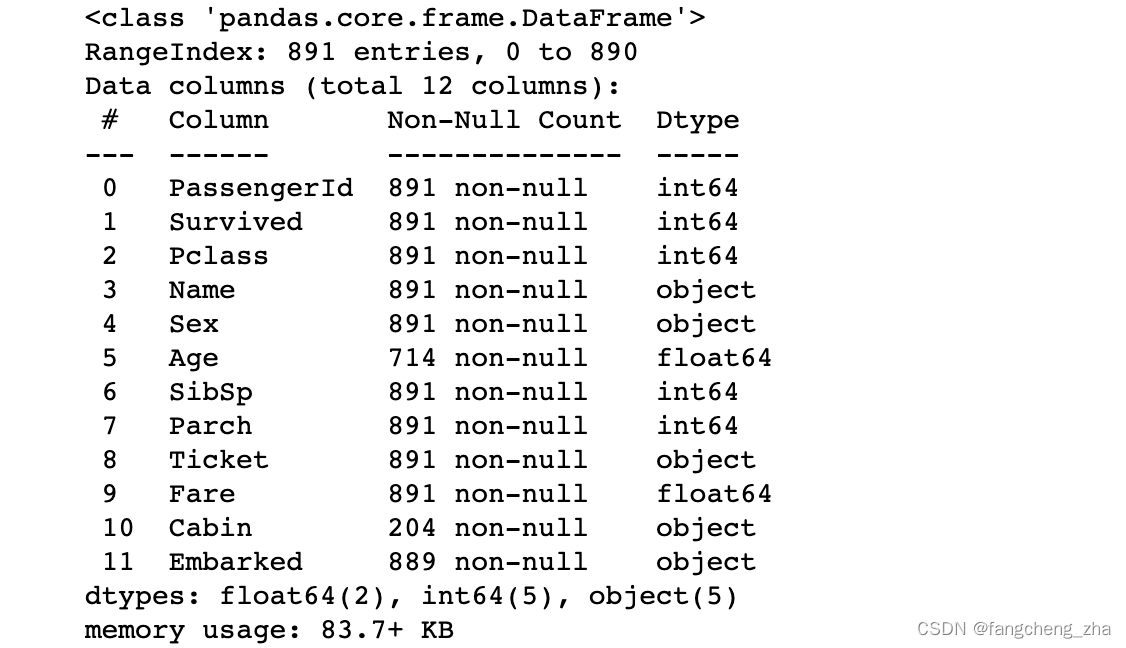
# 查看数据缺失情况
df_train.isnull().sum()
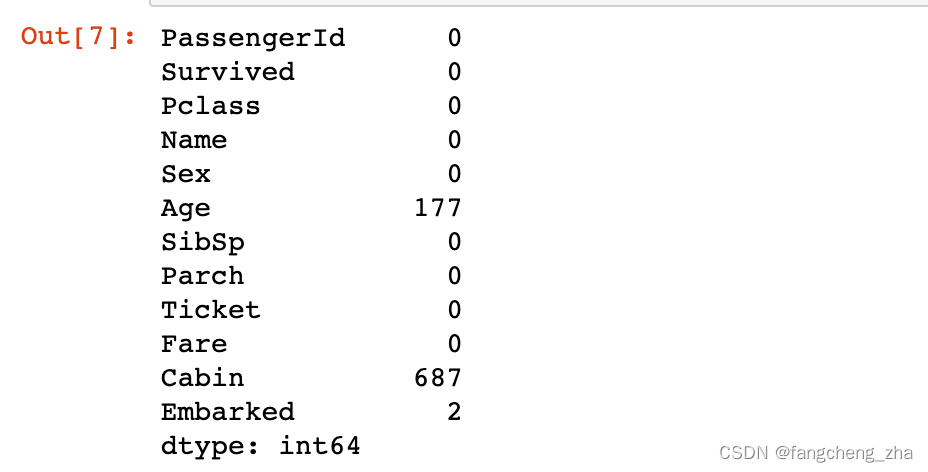
可以看出“Age”,“Cabin“,“Embarked”,三个特征存在缺失
# 查看数据描述
df_train.describe()
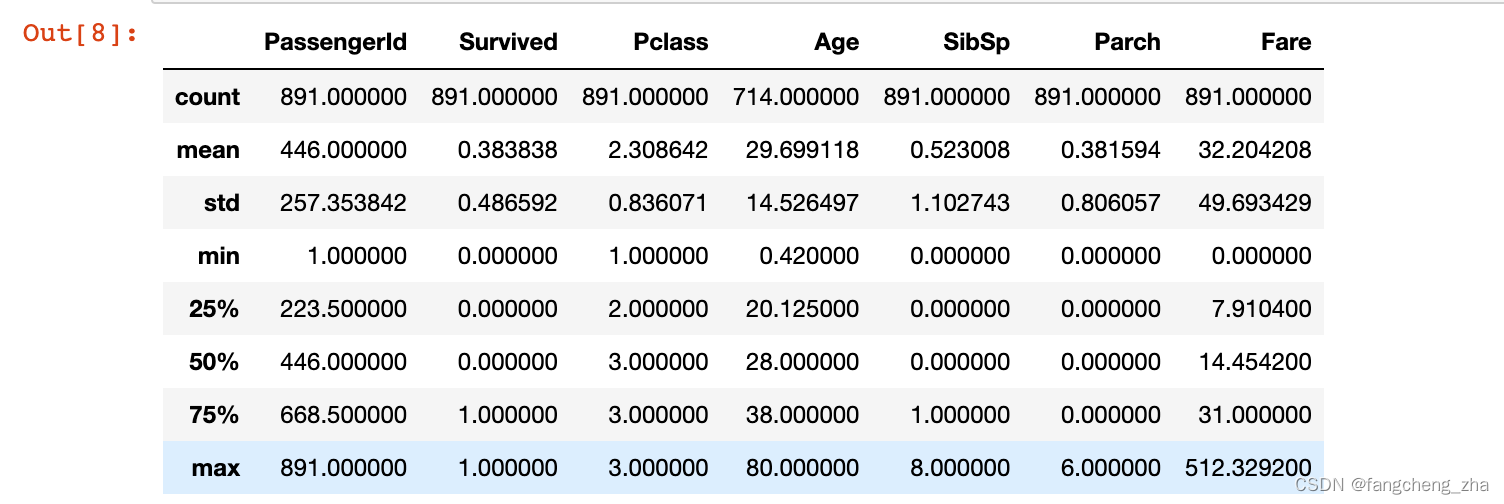
特征选取 不做复杂的特征工程,采用最快速的方法做一个预测。
数据空值处理
1.Cabin列缺失值数量较多,直接填充会对最终结果产生较大的误差影响,暂时不考虑该特征。 2.Age列对最终结果的影响较大,取Age的中位数对空值进行填充。 3.PassengerID为连续的序列值,对最终结果没有影响,不考虑该特征。
# 取Age的中位数对空值进行填充
df_train['Age'] = df_train['Age'].fillna(df_train['Age'].median())
df_train.info()
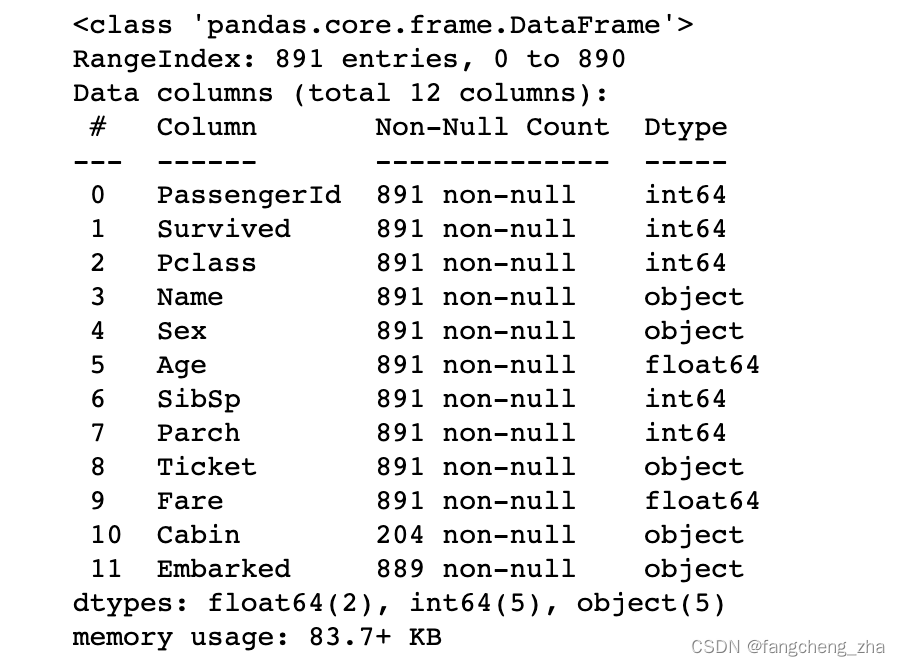
使用三个模型来对目标数据进行预测;分别是线性回归模型、逻辑回归模型以及随机森林模型
线性回归模型
# 导入第三方库
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import KFold
KFold 是sklearn 包中用于交叉验证的函数。 在机器学习中,将数据集A分为训练集(training set)B和测试集(test set)C,在样本量不充足的情况下,为了充分利用数据集对算法效果进行测试,将数据集A随机分为k个包,每次将其中一个包作为测试集,剩下k-1个包作为训练集进行训练。
# 选取简单的可用特征
features = ['Pclass','Age','SibSp','Parch','Fare']
LR = LinearRegression()
# 将样本分成三折交叉验证
kf = KFold(n_splits=3,shuffle=False)
predictions = []
for train_index,test_index in kf.split(df_train):
train_predictors = df_train[features].iloc[train_index,:]
train_target = df_train['Survived'].iloc[train_index]
LR.fit(train_predictors,train_target)
test_predictions = LR.predict(df_train[features].iloc[test_index,:])
predictions.append(test_predictions)
predictions=np.concatenate(predictions,axis=0)
predictions[predictions > 0.5] = 1
predictions[predictions <= 0.5] = 0
accuracy = sum(predictions == df_train['Survived'])/len(predictions)
print('accuracy:',accuracy)
accuracy: 0.7037037037037037
逻辑回归模型
from sklearn.model_selection import cross_val_score # 交叉验证函数
from sklearn.linear_model import LogisticRegression
Lr = LogisticRegression()
score = cross_val_score(Lr,df_train[features],df_train['Survived'],cv=3)
print(score.mean())
cross_val_score:交叉验证函数,用于评估模型性能,他可以将数据集分成K个子集,每个子集轮流作为测试集,其余自己作为训练及,最终返回k个测试集的得分,这个函数可以用于分类、回归等不同类型的模型估计。
增加"Sex","Embarked"特征
df_train.head()

sex_map = {'male':0,'female':1}
df_train['Sex'] = df_train['Sex'].map(sex_map)
df_train['Embarked'].value_counts()
df_train['Embarked'] = df_train['Embarked'].fillna('S')
embarked_map = {'S':0,'C':1,'Q':2}
df_train['Embarked'] = df_train['Embarked'].map(embarked_map)
df_train.head()

features = ['Pclass','Age','SibSp','Parch','Fare','Sex','Embarked']
score = cross_val_score(Lr,df_train[features],df_train['Survived'],cv=3)
print(score.mean())
从上述结果可以看出,增加新的’Sex’,'Embarked’特征,模型效果有一个极大的提升。
随机森林模型
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score
RFC = RandomForestClassifier(n_estimators = 10,min_samples_split = 2,min_samples_leaf = 1)
kf = KFold(n_splits = 3)
scores = cross_val_score(RFC,df_train[features],df_train['Survived'],cv = kf)
print(scores.mean())
使用网格搜索寻找最佳参数组合
from sklearn.model_selection import GridSearchCV
param_grid = {'n_estimators':[10,20,30,40,50,60,70,80,90,100],'max_depth':[2,3,4,5,6,7,8,9]}
grid = GridSearchCV(RFC,param_grid = param_grid,scoring = 'roc_auc',cv = 5)
grid.fit(df_train[features],df_train['Survived'])

print(grid.best_params_,grid.best_score_)
#选择最佳的模型
RFC = RandomForestClassifier(n_estimators = 20,max_depth = 6)
对测试集数据进行处理
df_test.head()
df_test.head()
# 对df_test的缺失数据集进行处理
df_test['Age'] = df_test['Age'].fillna(df_test['Age'].median())
df_test['Fare'] = df_test['Fare'].fillna(df_test['Fare'].max())
sex_map = {'male':0,'female':1}
df_test['Sex'] = df_test['Sex'].map(sex_map)
embarked_map = {'S':0,'C':1,'Q':2}
df_test['Embarked'] = df_test['Embarked'].map(embarked_map)
# 对RFC模型进行训练
RFC.fit(df_train[features],df_train['Survived'])
prediction = RFC.predict(df_test[features])
prediction[:10]
prediction
# 将预测的结果数组与PassengerId合并称为DataFrame形式
submission = pd.DataFrame({
'PassengerId':df_test['PassengerId'],
'Survived':prediction
})
submission



















 2846
2846

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











