







 本文介绍了一种无需编程背景也可实现的小红书数据抓取方法,通过JS注入获取加密参数,配合Python爬虫技术抓取笔记与评论数据。
本文介绍了一种无需编程背景也可实现的小红书数据抓取方法,通过JS注入获取加密参数,配合Python爬虫技术抓取笔记与评论数据。
【🏠作者主页】:吴秋霖
【💼作者介绍】:擅长爬虫与JS加密逆向分析!Python领域优质创作者、CSDN博客专家、阿里云博客专家、华为云享专家。一路走来长期坚守并致力于Python与爬虫领域研究与开发工作!
【🌟作者推荐】:对爬虫领域以及JS逆向分析感兴趣的朋友可以关注《爬虫JS逆向实战》《深耕爬虫领域》
未来作者会持续更新所用到、学到、看到的技术知识!包括但不限于:各类验证码突防、爬虫APP与JS逆向分析、RPA自动化、分布式爬虫、Python领域等相关文章
作者声明:文章仅供学习交流与参考!严禁用于任何商业与非法用途!否则由此产生的一切后果均与作者无关!如有侵权,请联系作者本人进行删除!
1. 写在前面
目前很多小伙伴可能或多或少都需要一些基础的笔记或者评论数据进行分析!有的可能想要通过一些关键词进行特定领域话题、笔记内容的搜索。有的则希望监测某篇笔记下面新增的评论内容或者某篇笔记下热度数据指标。从技术角度来说,在作者之前的文章中我们除了通过对x-s、x-s-common参数进行逆向分析还原外加密算法外,其实还可以通过JS注入免扣加密算法的RPC方案去获取到加密后的参数值,再通过请求获取到数据
但是,不管哪一种方案对于没有爬虫以及编程经验的人来说无疑是有一定难度与门槛的!
所以,在此前的一段时间内。作者也曾针对上面提到的两种方案分别都尝试进行了验证,比如设定好关键词又或是放置笔记链接来运行程序帮助我们获取到相关的数据:
- 关键词搜索
- 作品列表获取
- 笔记详情获取
- 评论内容获取
如果你是一名开发者且有爬虫及逆向的相关经验。可以参考作者之前所分享的文章,相关参数加密分析、Python与JS的纯算法、密钥信息如何定位都在文章内:x-s、x-s-common加密纯算法还原
当然,还有一种纯自动化的方案。对于一些仅有Py基础的小伙伴也是适用的,上手成本很低
2. 分析加密入口
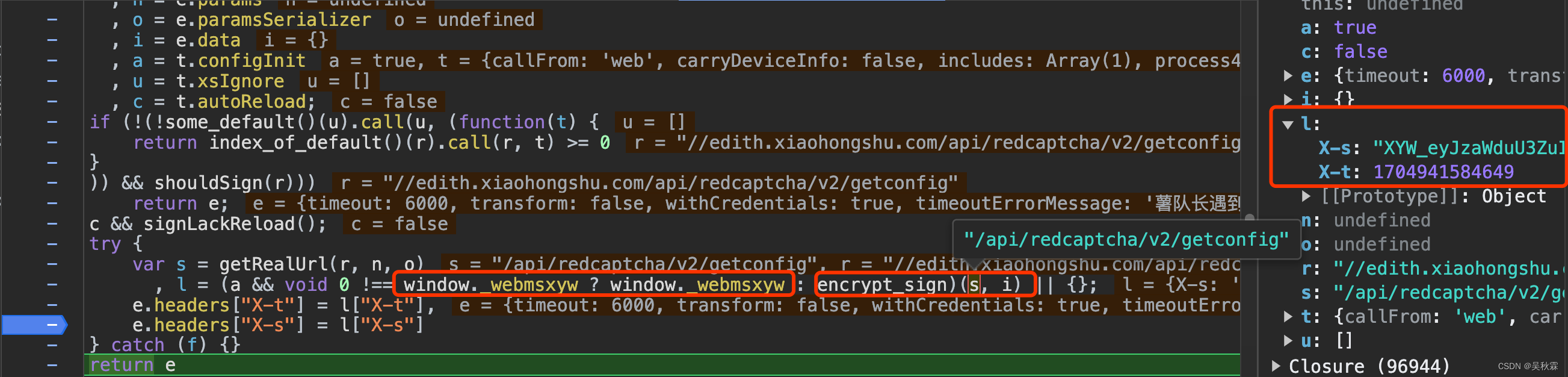
不管是RPC还是还原算法,其核心参数就是对x-s参数的的校验。这段密文是一个base64编码的,你可以拿到本地解密查看明文内容,如下所示:

RPC如何实现?首先需要先找到加密的入口,可以看到上图断点处l包含x-s跟x-t的返回,那么加密操作就在上面完成。看下面这行代码:
l = (a && void 0 !== window._webmsxyw ? window._webmsxyw : encrypt_sign)(s, i) || {};
window._webmsxyw函数内即加密逻辑,在自执行函数内部并添加在了window属性中
该函数接受两个参数,s是api接口的路径,i是请求提交的参数
3. 使用JS注入
这是一种简单的实现思路,提供大家进行参考!相对于纯自动化的效果肯定要略好,具体方案可以考虑使用Playwright或者pyppeteer等都可以实现。通过浏览器的JavaScript注入来获取到加密参数,实现方案Demo分别如下所示:
Playwright实现示例
import asyncio
from playwright.async_api import async_playwright
async def main():
async with async_playwright() as playwright:
browser = await playwright.chromium.launch(headless=True)
page = await browser.new_page()
# 注入stealth.min.js脚本
await page.add_init_script(path="stealth.min.js")
url = "" # 请求api
data = "" # 请求参数
# 执行JavaScript
encrypt_params = await page.evaluate('([url, data]) => window._webmsxyw(url, data)', [url, data])
local_storage = await page.evaluate('() => window.localStorage')
print(encrypt_params)
print(local_storage)
await browser.close()
asyncio.run(main())
pyppeteer实现示例
import asyncio
from pyppeteer import launch
async def main():
browser = await launch(headless=True)
page = await browser.newPage()
# 注入stealth.min.js脚本
stealth_script = open("stealth.min.js", "r").read()
await page.evaluateOnNewDocument(stealth_script)
url = "" # 请求api
data = "" # 请求参数
# 执行JavaScript
encrypt_params = await page.evaluate('([url, data]) => window._webmsxyw(url, data)', [url, data])
local_storage = await page.evaluate('() => window.localStorage')
print(encrypt_params)
print(local_storage)
await browser.close()
asyncio.get_event_loop().run_until_complete(main())
上面的stealth.min.js脚本是一位大佬开源的!注入的作用是为了防止被检测。不过你也可以选择使用一些已经做好反检测的框架或者方案进行。目前像笔记详情、评论内容都新增了xsec_token参数的校验。所以在搜索拿到结果后可以预先获取这个参数再传递到笔记详情与评论采集中,代码示例如下所示:
import time
import random
import requests
from typing import Dict
BASE_URL = '' # 网站地址
HEADER = {} # 请求头
def base36encode(number, digits='0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ'):
base36 = ""
while number:
number, i = divmod(number, 36)
base36 = digits[i] + base36
return base36.lower()
def generate_search_id():
timestamp = int(time.time() * 1000) << 64
random_value = int(random.uniform(0, 2147483646))
return base36encode(timestamp + random_value)
def request_api(method: str, uri: str, params: Dict = None, json: Dict = None) -> Dict:
url = f"{BASE_URL}{uri}"
response = requests.request(method, url, headers=HEADERS, params=params, json=json)
response.raise_for_status()
return response.json()
def get_keyword_note_result(keyword: str, page: int = 1, page_size: int = 20) -> Dict:
"""
根据关键词获取笔记信息。
:param keyword: 搜索关键词
:param page: 下拉翻页数
:page_size: 每一页最大数据量
:return: 搜索关键词详情
"""
uri = "/api/sns/web/v1/search/notes"
data = {
"keyword": keyword,
"page": page,
"page_size": page_size,
"search_id": generate_search_id(),
"sort": 'general', # 默认则是综合,time_descending最新、popularity_descending最热
"note_type": 0, # 默认则全部,其他筛选1是视频、2是图片
"image_formats": [
"jpg",
"webp",
"avif"
]
}
response = request_api("POST", uri, json=data)
def fetch_note_by_id(note_id: str, xsec_token: str) -> Dict:
"""
根据笔记ID获取详细信息。
:param note_id: 笔记ID
:param xsec_token: 验证Token
:return: 笔记详情
"""
payload = {
"source_note_id": note_id,
"image_formats": ["jpg", "webp", "avif"],
"extra": {"need_body_topic": "1"},
"xsec_source": "pc_feed",
"xsec_token": xsec_token,
}
endpoint = "/api/sns/web/v1/feed"
response = request_api("POST", endpoint, json=payload)
return response.get("items", [{}])[0].get("note_card", {})
def fetch_note_comments(note_id: str, cursor: str = "", xsec_token: str = "") -> Dict:
"""
获取笔记评论。
:param note_id: 笔记ID
:param cursor: 游标,用于分页
:param xsec_token: 验证Token
:return: 评论详情
"""
params = {
"note_id": note_id,
"cursor": cursor,
"top_comment_id": "",
"image_formats": "jpg,webp,avif",
"xsec_token": xsec_token,
}
endpoint = "/api/sns/web/v2/comment/page"
return request_api("GET", endpoint, params=params)
def fetch_sub_comments(note_id: str, root_comment_id: str, num: int = 30, cursor: str = "", xsec_token: str = "") -> Dict:
"""
获取子评论。
:param note_id: 笔记ID
:param root_comment_id: 根评论ID
:param num: 每页评论数量
:param cursor: 游标,用于分页
:param xsec_token: 验证Token
:return: 子评论详情
"""
params = {
"note_id": note_id,
"root_comment_id": root_comment_id,
"num": num,
"cursor": cursor,
"image_formats": "jpg,webp,avif",
"top_comment_id": "",
"xsec_token": xsec_token,
}
endpoint = "/api/sns/web/v2/comment/sub/page"
return request_api("GET", endpoint, params=params)
在此之前,其中很多细节上的处理这个都是最终工程化需要考虑的事情。比如采集的过程中频率的控制、资源的调度切换等等。本篇文章主要讲解的是通过非逆向分析的方式去解决加密参数问题!再携带加密参数对搜索、笔记、评论等接口发送请求快速获取结构化数据的实现过程
window.localStorage在之前加密分析的文章中已经详细介绍了,localStorage是一个在浏览器中存储键值对的API,通常用于持久化地存储数据,所需的b1参数就在其中
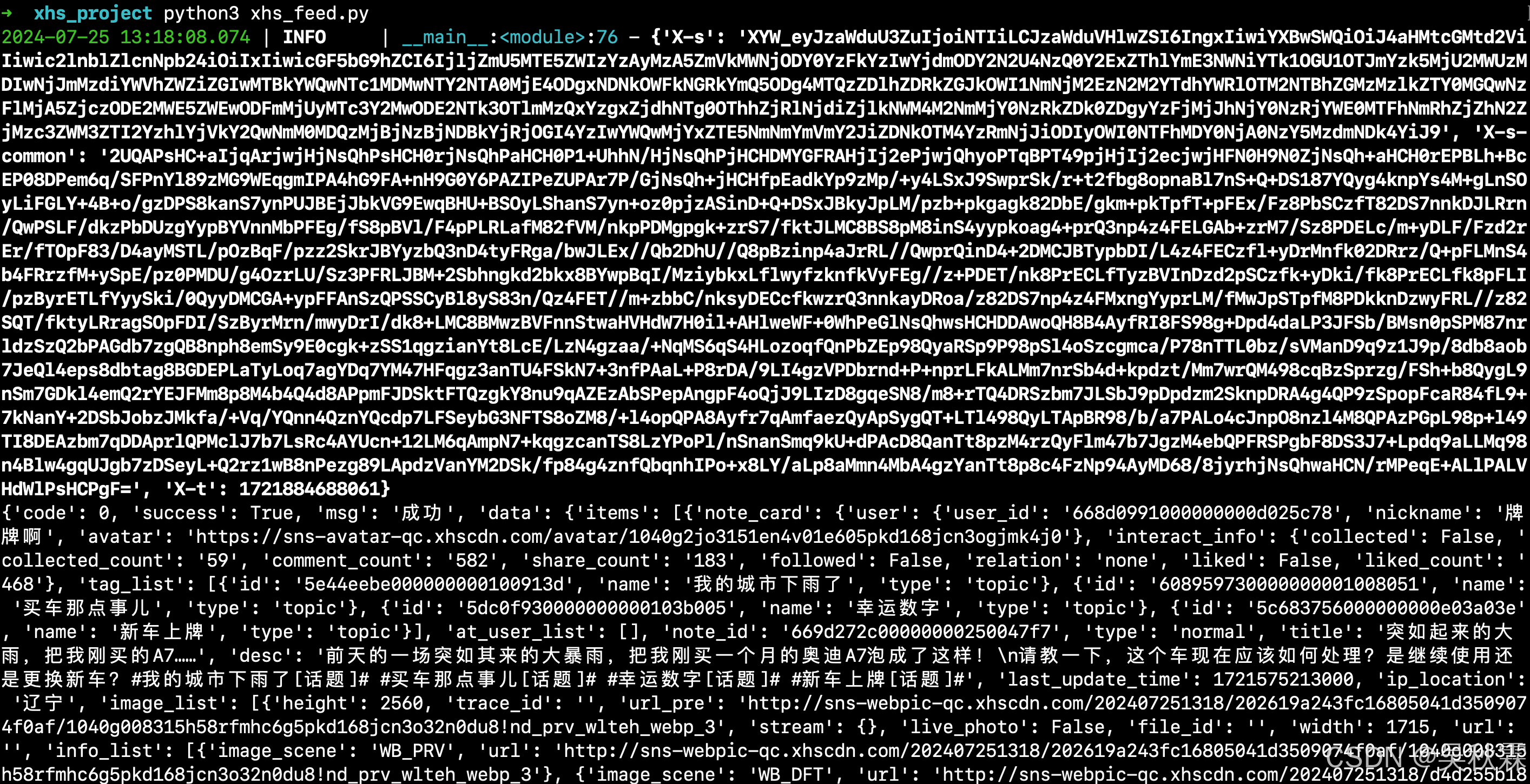
JS注入方式运行结果如下所示:

x-s跟x-t的加密参数通过注入的方式能够直接拿到,但是x-s-common的参数仍需要通过加密算法生成!但是这个参数目前大部分API并不校验,仍然以x-s参数为主
JS注入的方式对于有前端基础及经验的小伙伴,就很简单了。通过上面的方式获取到所有的加密参数后,接下来就是爬虫的工程化(下图是feed接口)
4. 爬虫工程化
以笔记搜索为例,下面对数据的抓取示例采用了上面作者提到的另一篇以还原加密算法的文章内算法测试的(非浏览器自动化或注入)。需要注意一下search_id是动态生成的!完整的爬虫代码实现如下所示:
import json
import time
import random
import execjs
import requests
def base36encode(number, digits='0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ'):
base36 = ""
while number:
number, i = divmod(number, 36)
base36 = digits[i] + base36
return base36.lower()
def generate_search_id():
timestamp = int(time.time() * 1000) << 64
random_value = int(random.uniform(0, 2147483646))
return base36encode(timestamp + random_value)
url = 'https://edith.xiaohongshu.com/api/sns/web/v1/search/notes'
api_endpoint = '/api/sns/web/v1/search/notes'
a1_value = '' # 自行获取
search_data = {
"keyword": "北京美食",
"page": 1,
"page_size": 20,
"search_id": generate_search_id(),
"sort": "general",
"note_type": 0
}
headers = {
'sec-ch-ua': 'Not_A Brand";v="8", "Chromium";v="120", "Google Chrome";v="120"',
'Content-Type': 'application/json;charset=UTF-8',
'sec-ch-ua-mobile': '?0',
'Referer': 'https://www.xiaohongshu.com/',
'sec-ch-ua-platform': 'macOS',
'Origin': 'https://www.xiaohongshu.com',
'Cookie': '', # 自行获取
'User-Agent': '' # 自行获取
}
with open('GenXsAndCommon.js', 'r', encoding='utf-8') as f:
js_script = f.read()
context = execjs.compile(js_script)
sign = context.call('get_xs_xsc', api_endpoint, search_data, a1_value)
headers['x-s'] = sign['X-s']
headers['x-t'] = str(sign['X-t'])
headers['X-s-common'] = sign['X-s-common']
response = requests.post(url, headers=headers, data=json.dumps(search_data, separators=(",", ":"), ensure_ascii=False).encode('utf-8'))
print(response.json())
最后,如果没有编程与爬虫经验的小伙伴!有研究、学习的需求也可以找作者领取开箱即用的完整项目源码进行学习!有兴趣的也可以根据文章所提供分享的思路自己进行研究与实现,没有太大难度!可以咨询作者给予必要的技术指导~
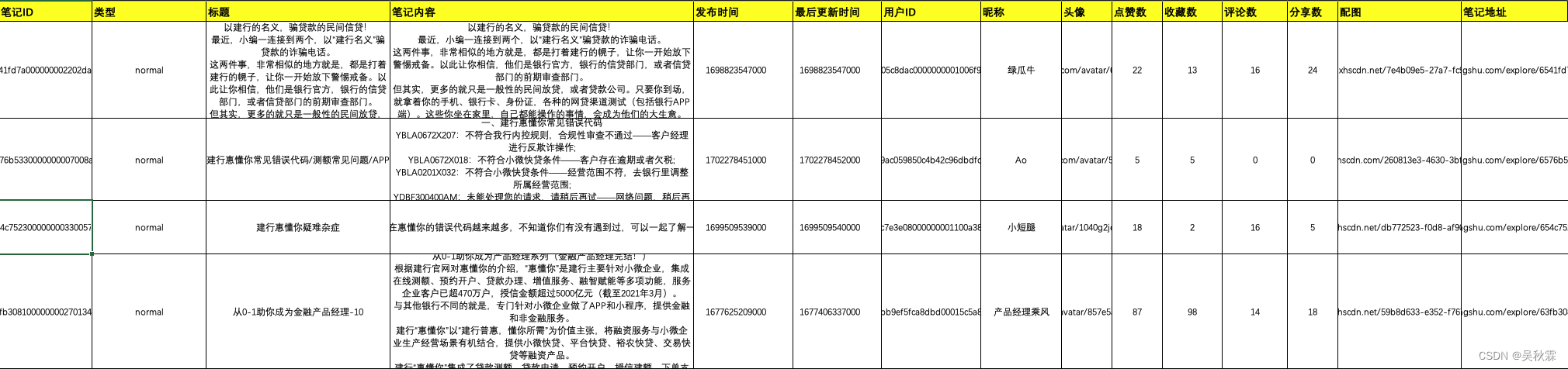
关于数据的获取,像笔记关键词搜索出来的所有笔记内容在抓取完成后均会自动存储到本地的Excel文件内,如下所示:
笔记所对应的所有评论内容在抓取完成后同样也会存储在本地的Excel文件内,如下所示:

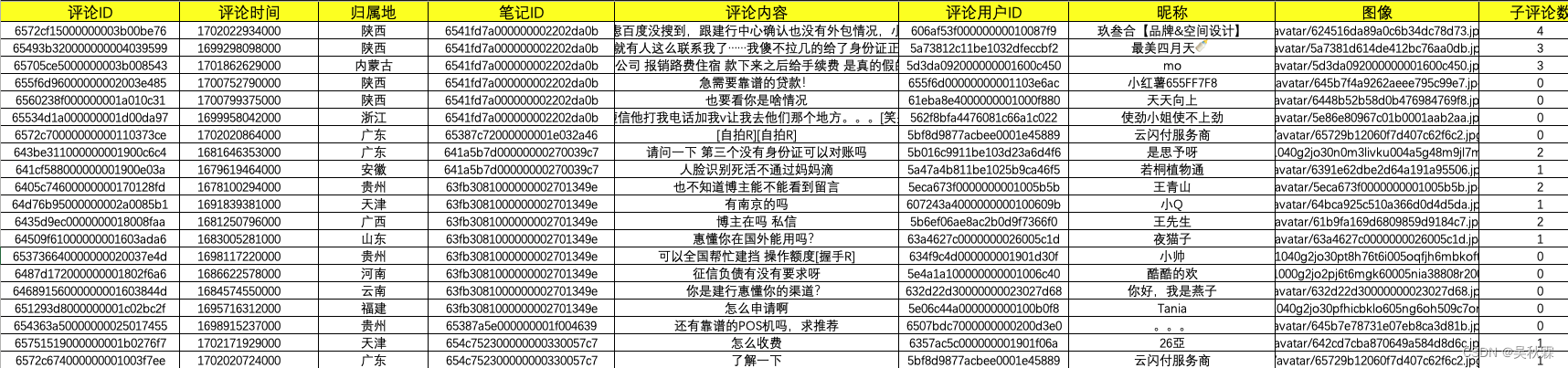
获取只需要笔记下面所有的全量一级、二级评论内容,可以直接去指定笔记ID然后获取,如下所示:

最后!互联网任何公开的数据源有获取数据的需求,可以适当的利用工具与技术来助力。但切记不要滥用,以免对任何第三份平台与网站造成压力与负担!请使用合理、合法、合规、合情的方式去满足自己的需求



















 1668
1668

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











