







 当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。# href 中最后的一个路径参数就是博主的id。# 开启三个线程并分配任务。
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。# href 中最后的一个路径参数就是博主的id。# 开启三个线程并分配任务。
if os.path.exists(path) and os.path.isdir(path):
if os.listdir(path):
return True
return False
下载资源
def download_resource(url, save_path):
response = requests.get(url, stream=True)
if response.status_code == 200:
with open(save_path, ‘wb’) as file:
for chunk in response.iter_content(1024):
file.write(chunk)
读入文件,判断作品数量然后进行任务分配:
读入文件
content = ‘’
with open(‘./xhs_works.txt’, mode=‘r’, encoding=‘utf-8’) as f:
content = json.load(f)
转换成 [[href, is_pictures],[href, is_pictures],…] 类型
每一维中分别是作品页的URL、作品类型
url_list = [list(pair) for pair in content.items()]
有多少个作品
length = len(url_list)
if length > 3:
ul = [url_list[0: int(length / 3) + 1], url_list[int(length / 3) + 1: int(length / 3) * 2 + 1],url_list[int(length / 3) * 2 + 1: length]]
# 开启三个线程并分配任务
for child_ul in ul:
thread = threading.Thread(target=thread_task, args=(child_ul,))
thread.start()
else:
thread_task(url_list)
若使用多线程,每一个线程处理自己被分配到的作品列表:
每一个线程遍历自己分配到的作品列表,进行逐项处理
def thread_task(ul):
for item in ul:
href = item[0]
is_pictures = (True if item[1] == 0 else False)
res = work_task(href, is_pictures)
if res == 0: # 被阻止正常访问
break
处理每一项作品:
处理每一项作品
def work_task(href, is_pictures):
# href 中最后的一个路径参数就是博主的id
work_id = href.split(‘/’)[-1]
# 判断是否已经下载过该作品
has_downloaded = check_download_or_not(work_id, is_pictures)
# 没有下载,则去下载
if not has_downloaded:
if not is_pictures:
res = deal_video(work_id)
else:
res = deal_pictures(work_id)
if res == 0:
return 0 # 无法正常访问
else:
print('当前作品已被下载')
return 2
return 1
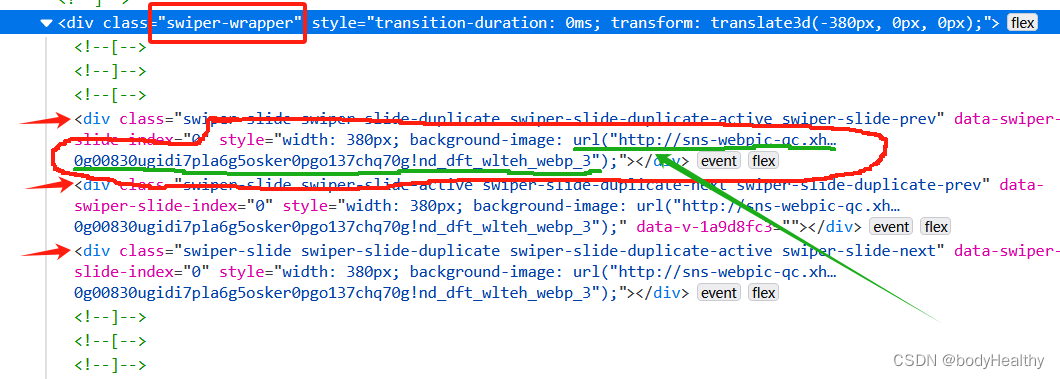
## 4、处理图文类型作品
对于图文类型,每一张图片都作为 div 元素的背景图片进行展示,图片对应的 URL 在 div 元素的 style 中。 可以先获取到 style 的内容,然后根据圆括号进行分隔,最后得到图片的地址。
这里拿到的图片是没有水印的。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2475
2475











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









