






 本文介绍了Java内存模型(JMM)、volatile关键字的工作原理,探讨了多线程中的工作内存和主内存概念,以及如何通过MESI协议确保缓存一致性。还讨论了指令重排序问题和懒汉模式中的半初始化问题,以及Java中内存屏障的具体实现。
本文介绍了Java内存模型(JMM)、volatile关键字的工作原理,探讨了多线程中的工作内存和主内存概念,以及如何通过MESI协议确保缓存一致性。还讨论了指令重排序问题和懒汉模式中的半初始化问题,以及Java中内存屏障的具体实现。
前言
对于多线程等等的各种操作,相比各位都了然于胸,现在我们来介绍一下更底层一点点的JMM内存模型,其实也是一个很简单的理想的内存模型
注意与JVM的内存模型区分
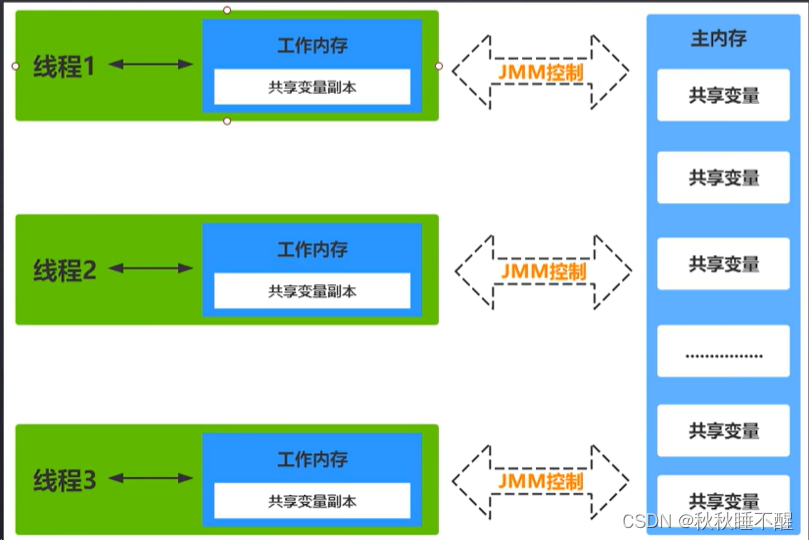
多线程内存模型主要是基于CPU缓存搭建起来的
这里就区分工作内存和主内存了
我们线程操作的其实是主内存的一个副本,多线程每个线程操作结束了之后需要刷回主内存
volatile关键字
我们知道volatile主要的两个功能就是
1.保证内存中的变量可见性
2.禁止指令重排序
下面我们来介绍一些关于volatile关键字以及高并发的内容
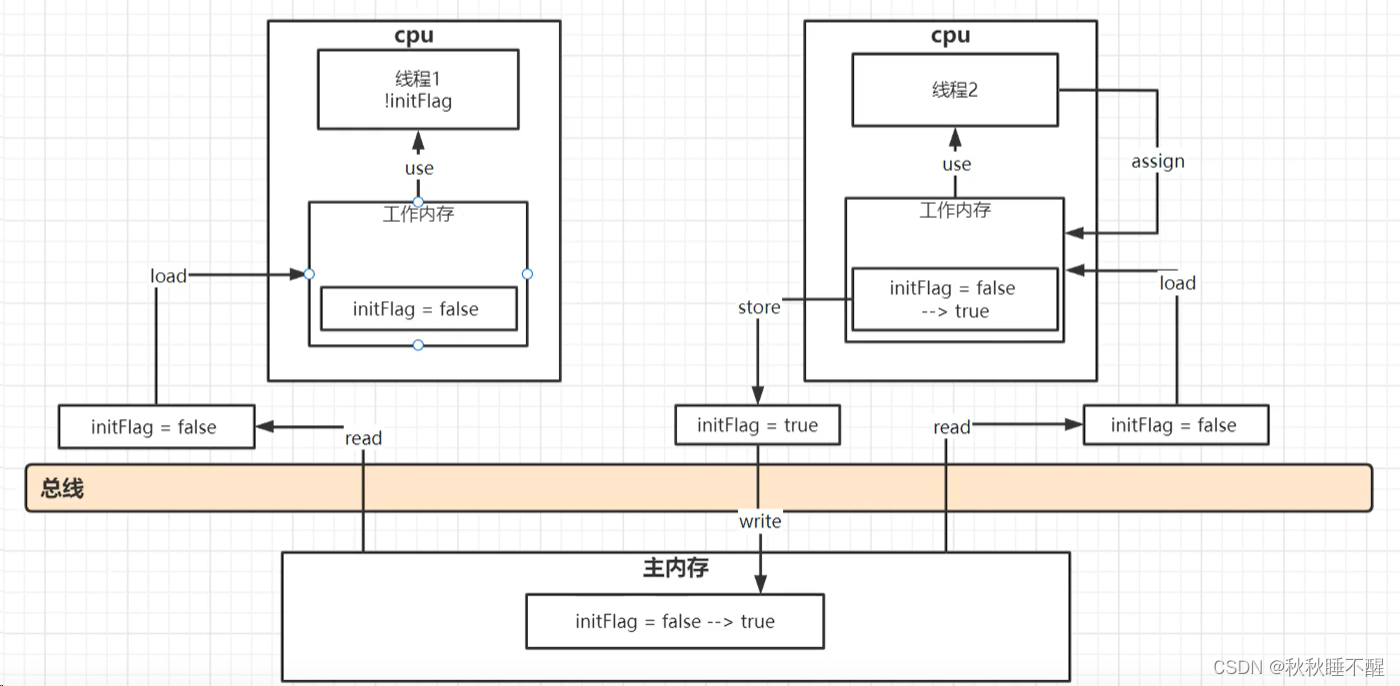
我们知道,如果两个线程同时操作一个变量,我们这里就称之为线程a和线程b,a线程假设操作了主内存的一个变量,另一个线程能感知到吗?
答案是不能,因为两者始终操作的是其工作内存中的变量副本而已.
如果这里我给共享的变量加入一个volatile关键字修饰,这里就b线程就能感知到工作内存中的变量变化了,这是为什么呢?
请听我慢慢解释
首先我们需要先了解一下经典的原子操作
然后我们来谈谈另一个线程是怎么感知到的
说到这里就不得不提我们的MESI(缓存一致性)协议了
这里就是线程a一修改主内存中的变量,其实这个修改是通过总线传输到主内存的
这里线程b就是通过总线嗅探机制,一直在监听总线,当他发现这里总线中有我的属性被修改了
这里我们的b线程对应的变量的属性就直接设置为I(无效),当下次线程b需要使用这个变量的时候哦,他就只能取主内存里面再去刷入工作内存了
那么我们的硬件协议又是怎么让缓存一致性协议生效的呢?
其本质就是在其底层的汇编代码前面加上了lock前缀
注意这里是修改完直接就同步回主内存,主打一个即时性


关于这里的指令重排序,我们也来谈一谈
为什么指令重排序
这里的指令重排序主要是为了加快程序性能而产生的
遵循 happens before 和 as is serial 原则
本质上就是在下面一条语句依赖于上面一条语句的时候
不会执行指令重排序,不影响依赖关系就随便排序
注:java 在执行代码之前会看看语法树前后有没有相互依赖
下面我展示部分原则

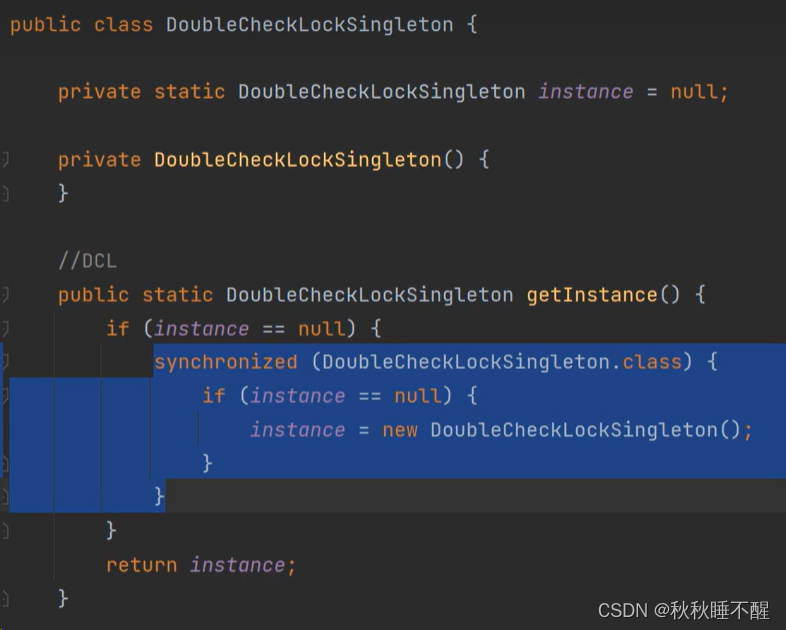
懒汉模式出现的对象半初始化问题
我们知道懒汉模式这里会使用双重校验锁
我拿出了其两行字节码指令
假设这里的putstatic在init之前
这里刚刚putstatic之后,cpu就调度到另一个线程了
这里判断已经不是空了,直接拿来使用,就会发生意想不到的问题
假设我这里a开了一个账户充6000块,然后直接去消费了
结果消费的时候发现账户的前不翼而飞了,所以这里的指令重排序问题是一个大的问题

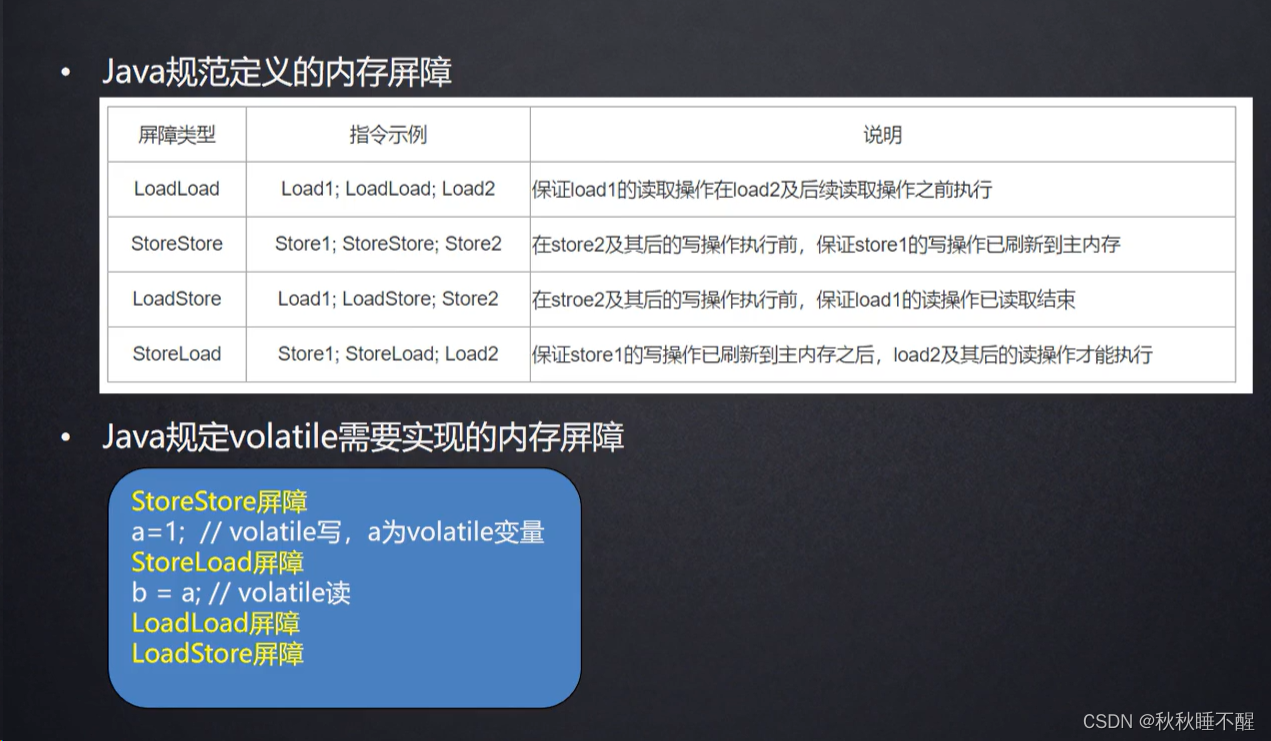
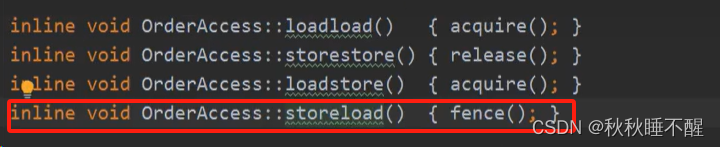
常见的几种内存屏障
我们都知道volatile关键字是底层实现其实是一些内存屏障来实现的
我这里贴出几种常见的内存屏障
然后我们可以查看一下Java具体是怎么实现的
我们以
openjdk8根路径jdk\src\hotspot\share\interpreter\zero路径下的bytecodeInterpreter.cpp文件中,处理putstatic指令的代码:先进行判断是否有volatile修饰的实例
然后判断是对于不同的修饰类型进行操作
CASE(_putstatic): { // .... 省略若干行 // Now store the result 现在要开始存储结果了 // ConstantPoolCacheEntry* cache; -- cache是常量池缓存实例 // cache->is_volatile() -- 判断是否有volatile访问标志修饰 int field_offset = cache->f2_as_index(); // ****重点判断逻辑**** if (cache->is_volatile()) { // volatile变量的赋值逻辑 if (tos_type == itos) { obj->release_int_field_put(field_offset, STACK_INT(-1)); } else if (tos_type == atos) {// 对象类型赋值 VERIFY_OOP(STACK_OBJECT(-1)); obj->release_obj_field_put(field_offset, STACK_OBJECT(-1)); OrderAccess::release_store(&BYTE_MAP_BASE[(uintptr_t)obj >> CardTableModRefBS::card_shift], 0); } else if (tos_type == btos) {// byte类型赋值 obj->release_byte_field_put(field_offset, STACK_INT(-1)); } else if (tos_type == ltos) {// long类型赋值 obj->release_long_field_put(field_offset, STACK_LONG(-1)); } else if (tos_type == ctos) {// char类型赋值 obj->release_char_field_put(field_offset, STACK_INT(-1)); } else if (tos_type == stos) {// short类型赋值 obj->release_short_field_put(field_offset, STACK_INT(-1)); } else if (tos_type == ftos) {// float类型赋值 obj->release_float_field_put(field_offset, STACK_FLOAT(-1)); } else {// double类型赋值 obj->release_double_field_put(field_offset, STACK_DOUBLE(-1)); } // *** 写完值后的storeload屏障 *** OrderAccess::storeload(); } else { // 非volatile变量的赋值逻辑 } }我们看到这里判断完的的storeload
然后我们介绍一下这个fence函数
这里先判断使用的显卡还是其他显卡
其实没有什么区别,主要是amd使用rsp,其他显卡使用的是esp,使用的寄存器不同
inline void OrderAccess::fence() { // always use locked addl since mfence is sometimes expensive // #ifdef AMD64 __asm__ volatile ("lock; addl $0,0(%%rsp)" : : : "cc", "memory"); #else __asm__ volatile ("lock; addl $0,0(%%esp)" : : : "cc", "memory"); #endif compiler_barrier(); }这个__asm__就是表示告诉编译器在这里插入汇编代码
volatile就是告诉编译器我这里插入的汇编代码原原本本的给我执行,不许重排序
我们发现这些名字前面都有一个lock就是会将这块内存区域的缓存锁定并写回到主内存中















 3296
3296

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









