









一上课就说作业的截止日期只有7天,想起原来该课程还是有作业的,不做的话可能达不到效果,要不等到课程中段了或者看完整个课后再写吧。。另外自己在想找个时间把凸优化和乔丹推荐的书单开始学习了。
Lecture 3
回顾上一讲,image classifier is a tough task但是最新的技术已经能又快又好地解决这个问题了,这些都发生在过去3年里,课程结束后你们就是这个领域的专家了!




今天的任务就是上面最后一张图关于loss function/optimization
举个例子:
使用下面这种策略衡量multi-class SVM的损失(为什么这样我也不太明白)

平均得到总的损失:

但是使用上述这种损失函数有一bug:(大概的意思就是如果存在W使得损失函数为0,那么W成比例放大也可以使得损失函数为0,和函数/几何间隔差不多)

具体可以看一个例子

解决的方法是加上正则项(话说这种解决方法与正统的SVM解决方法似乎不同,后者考虑的是使用几何间隔,并没有说什么正则项):

比如下面的例子,偏爱第二种W,给出的解释是因为第二种考虑了更多的input pixels
在讲softmax分类器的时候又有同学问到了此处的理解,Andrej解释道L1范数倾向稀疏,类似是一种特征选择的方法,马上就有同学追问那么下面的例子为什么不偏爱第一种W呢,既然它可以选择更少的特征,Andrej语塞。。他说这个同学说的确实有道理,关于正则化还有很多technical interperatation,这里他只是想让大家获得一些浅显的intuition,不打算深钻,有兴趣可以看learning theroy

刚才讲的是SVM,现在讲第二种分类器,softmax

计算一个损失函数的例子:

SVM和softmax有不同的损失函数,下面解释原因:

下面的例子(从上往下变化),SVM的margin总是为0,而softmax则会很高兴,因为softmax希望”正的很正,负的很负“

下面讲优化,,(感觉上面讲的不如CS229深刻。。)


方法一:随机搜索,其实就是guess and check,看哪个最好
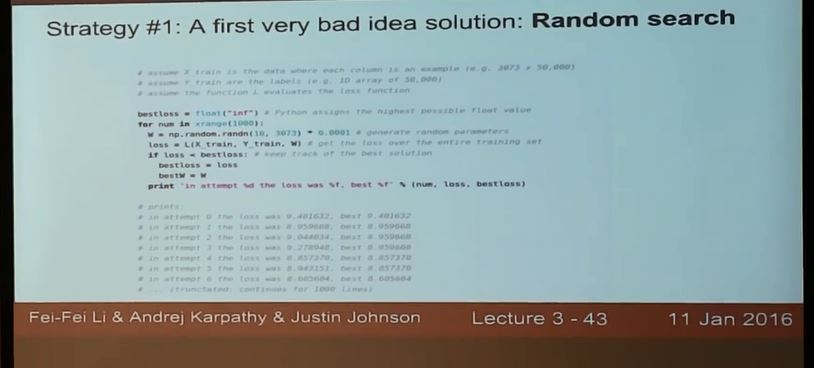
方法二:梯度法

实际中常使用解析梯度,然后用数值梯度去检验/gradient check

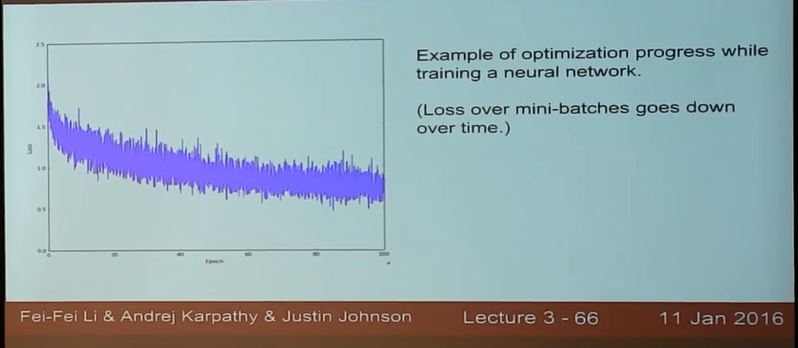
Mini-batch gradient descent is more efficient

比如用Mini-batch gradient descent 训练神经网络,总体损失下降,但是每一次都有噪声
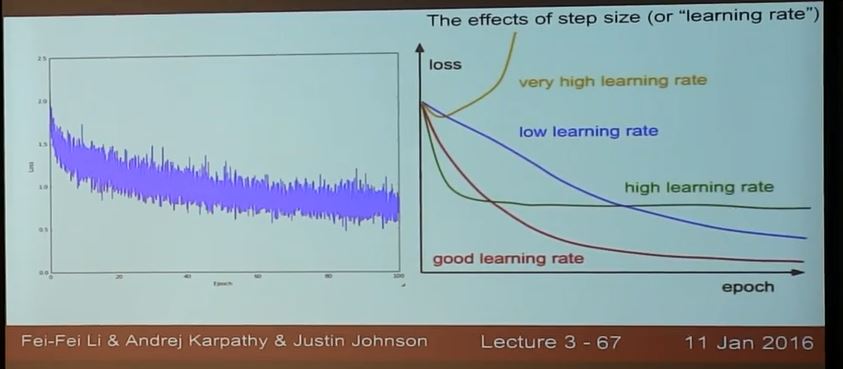
除此,learning rate太大太小也不行
还有更多“花哨”的更新方法:

后面讲到除了直接将raw image输入线性分类器,还可以做一些特征工程,将特征构成一个列向量代替raw image输入分类器:
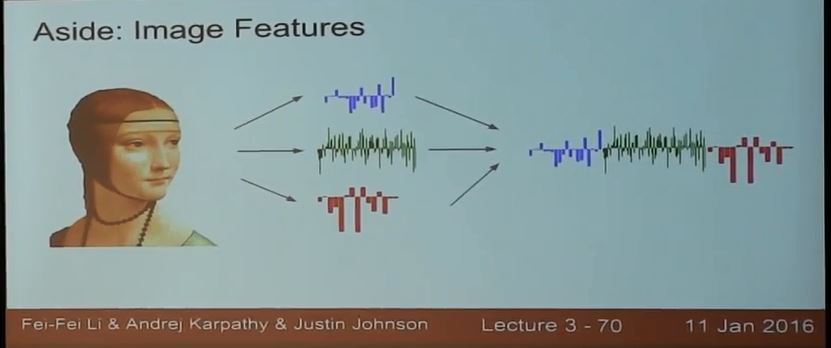
比如有颜色柱状图的方法;
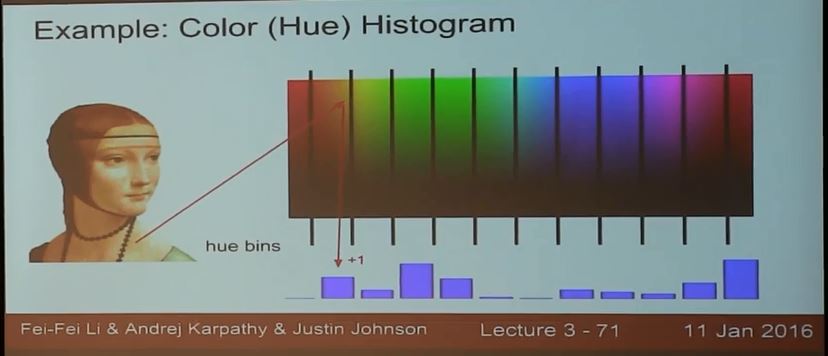
HOG/SIFT的方法;

bag of words;

作为与人工特征工程的对比,祭出了神经网络的方法:

下一讲:

本讲结束!















 1064
1064











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









