







语义分割可以划分到目标检测领域,不同的是,一般意义上目标检测只需要输出被检测物体的bounding box,而语义分割则需要输出一个mask,所以要求更高了。
从技术上说,语义分割归根结底就是对context information的建模。
研究意义
语义分割(Semantic Segmentation)的目标是给定一张图片,对于图片中的每一个像素做分类。例如下中给出的原始输入图片,语义分割算法对图片中的每一个像素分类,得到对应的结果。在分割结果中,不同颜色代表不同类别:如红色代表行人,蓝色代表汽车,绿色代表树,灰色代表建筑物等。语义分割问题在很多应用场景中都有着十分重要的作用(例如图片理解,自动驾驶等),所以近年来,该问题在学术界和工业界得到了广泛的关注。从大方面看,它是通往场景理解之路的high-level vision task。
Semantic segmentation is one of the high-level task that paves the way towards complete scene understanding.


研究现状
与许多其他vision task一样,深度学习的到来掀翻了流行的传统方法的统治,在精度(有时甚至还有效率)上开始吊打其他的方法。然而,由于发展日新月异,文献层出不穷,深度学习还不如传统机器学习方法体系成熟,也没有好的review能够帮人们分辨出那些里程碑的(或真正有影响力的)工作和比较次的方法。
下图是现在语义分割领域的常用数据集
(来自A Review on Deep Learning Techniques Applied to Semantic Segmentation-2017 [Paper])

再下图,是比较经典的基于深度学习的方法(然而我感觉一多半的都不认识,可能这些方法是从innovation角度列出的);

这里选择几个比较典型的方法进行介绍;
FCN(2014.11.14 arXiv v1)
FCN是深度学习进军语义分割领域的第一炮,它创新地将常用的卷积神经网络结构的全连接层卷积化了(其实全卷积的提法早在overfeat中就有了,好像googlenet还是vgg中也出现过),并且引入了deconvolution进行upsampling,从而可以满足语义分割任务end2end的学习,启发了后续的大量研究。下图显示了它的基本思想

除此,FCN还利用了skip layer的思想来融合浅层的信息

此后的FCN PAMI版本中,作者对训练的一些trick做了一些探讨。
ParseNet(2015.1.15 arXiv v1)
ParseNet和SSD(Single Shot MultiBox Detector)都出自Wei Liu之手。ParseNet的主要创新就是用到了global context information来提升语义分割的精度。
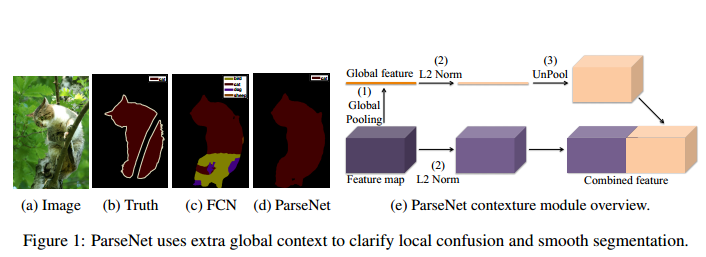
文章提到了early fusion,late fusion的概念,分别对应分类前融合,分类后融合,而且还讨论feature fusion前L2 norm的必要性问题。
DeconvNet
FCN之后,韩国的研究团队随后提出了DeconvNet,网络拓扑结构见下图

说实话,unpooling(利用先前pooling的indices)的思想一点也不新鲜,ZFNet的相关工作中早就有了;从上面的拓扑结构图来看,唯一一个不和谐,也是我觉得用真正用到deconvolution的地方就是从fc7的1x1到紧随其后的7x7,这也是整个网络唯一一个用到deconvolution来扩大resolution的地方,此后都是通过作者自定义的一个unpooling层来实现feature map的扩大。对应的如果再netscope中看的话,就是下面这样的

另外,作者考虑到FCN不能很好地handle scale,于是利用了一种instance-wise的训练方法
The trained network is applied to individual object proposals to obtain instance-wise segmentations, which are combined for the final semantic segmentation; it is free from scale issues found in FCN-based methods and identifies finer details of an object.
2017/8/26更:前两天听了北大申发龙博士做的CVPR2017语义分割方面工作的介绍,他说…韩国人的这篇DeconvNet说明了一件事,那就是反卷积在语义分割上完全没有用。(笑哭)
SegNet
剑桥大学的团队提出SegNet
项目主页:http://mi.eng.cam.ac.uk/projects/segnet/
网络拓扑结构:

这种网络结构乍一看和DecovNet非常相似,都是用了一种encoder+decoder的思路,但是细节上还是有不同的。SegNet相比DecovNet去掉了全连接层,这样一来,连先前DeconvNet中那个我觉得不和谐的地方(通过deconvolution使得feature map从fc7的1x1到7x7)都不见了,整个网络完全没有用到deconvolution来增大resolution,就像他的名字一样,也没有和deconvolution攀亲戚。整个结构衔接更加和谐,下图

去掉fc层之后,参数数目极大减少,计算速度大大提升。这个网络在精度和速度上面的均衡表现令人印象深刻。
在SegNet中,作者特意比较了他们的利用max-pooling indices进行upsampling的方法和普通的deconvolution来upsampling的方法,见下图

看完这个图,觉得比较得挺好的。给人一种感觉就是,SegNet大胆地承认了自己不是使用deconvolution的方法,而DeconvNet则名字上比实际上和deconvolution联系上更紧一些(前面已经说过了,我觉得DeconvNet只有fc7之后那一层有点deconvolution的意思)。
DeepLab
谷歌的DeepLab团队接连推出了DeepLab-v1和DeepLab-v2两个版本,在精度上更上一层楼。
DeepLab-v1的结构以VGG16作为base network,率先使用了dilation convolution(这很大程度上促成了后面dilated convnet的提出),并且将VGG16的第一层的kernel size从7减小到3或4,全连接层的通道数也减少了,从而实现了加速。值得一提的是,作者还独出心裁地将NIPS2011新提出的DenseCRF的成果应用进来,进行输出label map的进一步加工(也就是精细化预测),这也起到了不小的提升效果。
DeepLab-v2的结构进一步地考虑了multi-scale的信息,提出了ASPP的结构,从而能考虑多尺度信息,这使得分割的精度进一步提升,ASPP示意图如下

除此之外,作者还在DeepLab-v2中对训练的一些参数设置进行了探讨,比如发现使用多项式的学习策略比step和fix都要好,这也启发了后来商汤科技的PSPNet。
Deeplab-v3,可能是看到v2被PSPNet抢了风头,于是DeepLab-v3问世了,对标PSPNet。
主要地,作者使用了两种策略来试验multiple atrous rates:一种是“串联的结构”(atrous convolution in cascade);另一种则是“并联的结构”(atrous convolution in parallel);以此来handle语义分割中的mutliple scale问题。其中并联的结构主要是基于先前DeepLab-v2提出的ASPP(Atrous Spatial Pyramid Pooling)结构,并且受PSPNet和 ParseNet的启发,进一步融合了image-level global feature,提升了精度。而且,文章还论述了Multi-grid的问题,也就是如果dilation按照2,4,6,8类似的增长的话,会浪费许多image pixel,所以作者采用了多种数字组合来试验(咦~文中我怎么找不见了,这是在哪儿看见过来着?);另外,如果dilation太大的话,最后其实相当于只有中间的feature map pixel起了作用,是effective pixel,其他的地方都去卷积了padding的零元素了。文章以ResNet作为base network,使用了Batch Normalization和诸多trick,在没有使用CRF后处理的情况下能在PASCAL VOC2012上拿到第二名的好成绩。另外一个值得称道的地方是,文章作者分享了详细的工程最佳实践(best practice),让人十分受益。比如说作者发现Batch Normalization Layer对于训练很有必要(先前的DeepLab-v2没有BN layer),并且使用了bootstrapping的方法来着重训练那些标注较少的样本等。

Dilated ConvNets
受益于DeepLab中atrous convolution的思想,普林斯顿大学的Fisher Yu将这种思想进一步总结,提出了dilated convolution,让普通的卷积操作成为dilated convolution的特例。 Dilated convolution可以可以在不损失feature map分辨率的情况下指数级别地增加感受野,这使得更多的context information被考虑进去了,让语义分割的精度继续提升。

FC-DenseNet
再然后,由于DenseNet在cifar-10的分类任务上取得了很好的成绩,显示出是一种比较先进的网络结构,于是Yoshua Bengio一行人,将DenseNet改造之后应用于语义分割任务,提出了FC-DenseNet。网络结构如下

不过据作者描述,他们在CamVid dataset上面能够很快地收敛,但是在PASCAL VOC上却难以收敛,直到使用Adam optimizer来训练,结果是表现效果很差。
PSPNet(CVPR2017)
PSPNet是CUHK和商汤科技提出的一种语义分割系统,在ImageNet2016场景竞赛中拔得头筹。文章中使用了大量的工程技巧,比较令人印象深刻是他们使用了一个叫做PSP的结构,能够很好的multi-scale的信息,和global信息。这种好处是,可以考虑不同object的位置关系,比如说不至于让汽车出现在河里这种反常规的位置关系出现

RefineNet (CVPR2017)
文章来自阿德莱德大学沈春华老师他们组
这篇文章的trick或者网络的结构设计确实比较精妙,核心在于理解RefineNet的结构

现在RefineNet在VOC12上排位靠前
论文地址:https://arxiv.org/abs/1611.06612
Large Kernel Matters(CVPR2017)
这篇文章是清华和旷视科技(Face++,孙剑)合作的文章,文章强调大kernel很重要,但是不是plain large kernel,而是类似inception中的那种1xk然后接一个kx1的那种。这篇文章旨在解决语义分割中classification和localization的矛盾,因为它说先前的文章主要解决的是localization的问题,所以本篇文章就用large kernel来增大对classification的重视。

不过为啥是用1xk接上kx1的结构而不是平常的大kernel,也很难解释清楚,感觉就像是试出来的一样。
作者们还雄心勃勃地把ResNet中block的kernel也用自己的这种large kernel的设计(叫做GCN)替换掉,但是发现在分类上没有提升,GCN只在语义分割上有明显的作用,这终究还是一个难以解释的事情。
代码尚未开源
SDN(2017.08.04 arXiv v1)
这篇是现在VOC12上排名第二的算法,实际上应该是排名第一,因为第一名是DeepLabv3-JFT,原团队DeepLabv3拿了一个谷歌的超大的数据集JFT去pretrain了ResNet,然后在原有基础上刷到了第一。
SDN全名是Stacked Deconvolutional Network for Semantic Segmentation,来自自动化所卢汉清老师组,第一作者是付君师兄。基于SDN的模型,CASIA和京东的联合团队CASIA_IVA_JD拿到了Places2017 scene parsing竞赛的冠军。 并在ICCV2017的Joint Workshop of the COCO and Places Challenges上做了演讲。
模型拓扑:

用了stacked encoder-decoder的结构,然后借鉴了densenet的dense connection,FCN的skip connection,HED的hierarchical supervision(或者deeply supervision)来更好地优化网络。
Multi-Scale
以上提到的文章都只局限于自己已经阅读过的,而在阅读A Review on Deep Learning Techniques Applied to Semantic Segmentation-2017一文时,文中有关multi-scale的探讨很有必要做一下笔记。
有关multi-scale的意义或者说必要性,
文中提到了下图列出的四篇工作,详细的内容可以去阅读原文4.3.2

Feature Fusion
Feature Fusion部分也讲的很精彩,只是还有点没太搞懂late fusion和late fusion有什么区别(据ParseNet所言,FCN是late fusion,而自己是early fusion,这就更让我迷糊了)

比较有代表性的工作是W. Liu, A. Rabinovich, and A. C. Berg, “Parsenet: Looking wider to see better”
利用RNN进行context information建模的
代表性工作
Reseg: A recurrent neural network-based model for semantic segmentation,”
Recurrent Convolutional Neural Networks (rCNNs)
……
(对RNN不太关注,所以就不多说了)
存在的问题
- 主要存在的问题是精度和效率的trade off,有些方法虽然精度很好,但是网络过于复杂,离实时性差的太远;
- 然后就是一个全局信息和局部细节的矛盾。
- 还有一个reproducibility的问题,现在发的文章非常多,但是有的文章细节交代不够,而且后续的开源工作做得不好,导致人们复现起来十分困难,这一定程度上会阻碍语义分割的研究和发展
- 另外,怎么将各个物体之间的语义约束作为一种先验信息融合进入语义分割框架也是一个值得考虑的地方,因为现在的分割大多都是没有显式地考虑物体之间的语义约束。
未来的研究思路
- 3D数据,现在大多数的研究都是在二维的数据上开展的,ImageNet2018就要开始加入3D的数据,这说明3D语义分割是有研究的必要的
- 在视频语义分割任务中融合时间信息
- 点云数据的语义分割,这时常规的卷积神经网络就无法直接应用进来了,需要一些离散化的方法
- multi-scale 和 mutli-context信息的利用还存在很大的改进空间
- 网络加速以实现实时性
- 模型压缩以减小内存占用,因为想要真正的让研究投入应用,还要考虑设备的内存限制,而现在的有些网络虽然精度不错,但是非常耗内存
- multi-view信息融合
================================================================
2017/8/27 更新
Appended Review from the perspective of Automated Driving
(motivated by https://arxiv.org/abs/1707.02432)
以前的语义分割模型都是为generic images设计的,而不是针对自动驾驶,如果专为自动驾驶设计,那么可以融入更多的prior sturcture/information.
自动驾驶场景下的语义分割看重三点: accuracy, robustness, speed.
通用语义分割技术的几个应用场景:
- 机器人
- 医疗应用,比如医学图像分割
- 增强现实
- 自动驾驶(主要)
语义分割方法的分类:
- 传统方法
- 基于FCN的方法
- Structured Models
- Spatio-Temporal Models

传统方法,传统方法已经没人用了,所以就不提了,大概就是用随机森林等方法。
基于FCN的方法,有三个阶段(按时间看):
- patch-wise training:比较经典的是LeCun他们做的,使用Laplacian Pyramid分3个stages+图模型postprocess
- end-to-end learning:始于FCN
- multi-scale segmentation:FCN(skip connection),U-Net
Structured Models的方法,有
- 基于图模型,比如CRF的方法
- 使用RNN来建模context information的方法
Spatio-Temporal Models的方法,主要是用于视频语义分割,融合CNN和RNN(LSTM)的特点进行时空信息的建模。值得一提的是,最近发现一篇LeCun他们的文章,又在这个方向挖坑,Predicting Deeper into the Future of Semantic Segmentation,大致意思是用语义分割预测未来帧。因此,说不定视频的语义分割也是一个有前途的方向。
————————————————————————————————————-
下面这部分主要涉及自动驾驶方面的一些东西。
就具体的应用场景而言,自动驾驶可以为语义分割带来许多先验信息,比如说:路面总是在图像偏底部,路面上的标志线总是粗的,并且汇聚在图片的消失点,交通信号灯的颜色等。
Dense High Definition(HD) maps,不知怎么翻译,翻译成稠密高清地图吧。精确的目标识别难以达到,所以借用HD地图来改善,目前主要有两种类型的HD地图:
- Dense Semantic Point Cloud Maps:类似语义3D点云,这个是谷歌和TomTom采用的方法,昂贵复杂,对存储要求高。
- Landmark based Maps:相当于是上面的2D版本,是Mobileye and HERE 采用的方法。
Localization,定位。位置信息对于自动驾驶的重要性不言而喻,光有语义(分割)的信息而没有精确的位置(比如距离)信息是不行的。解决这个问题有三种方法:
- SfM
- 雷达传感器
- Joint In-the-Network Localization:其实就是在一个网络中同时进行语义分割和景深估计,这样子两个任务可能会协作加强,这也是未来值得研究的一个方向。
Challenge
未来的,自动驾驶方面的挑战,某种程度上也是一般语义分割的挑战:
- 嵌入式设备的计算复杂度:现在的语义分割速度在嵌入式GPU板子上,处理高清图还未及实时,解决的方法就是两条,一是研发更高算力的GPU,二是研究更加efficient的算法。
- 对大型语义分割数据集的需求:语义分割的函数复杂度很高,需要类似甚至超过ImageNet量级的数据集进行训练
- Learning Challenges
- 类别不均衡:比如行人比天空的标注要少,会造成忽视小物体;解决办法,一是使用weighted loss function,二是使用mask predictions on detected bounding boxes of these small objects,比如Instance-Sensitive FCN
- 未见物体:处理训练集中未见的物体,比如想象路上出现了一只考拉熊,那么softmax分类器还是会把它分成某种已经物体;解决办法可以参考Bayesian Segnet衡量分类的不确定性。
- 简化输出:大意是简化语义分割结果的输出,尤其是在纹理非常丰富的场景中,希望输出的结果能简化。
- Instance级别的语义分割:有时候一些场景,比如想要跟踪行人,需要不仅仅是类别信息,还要identity的信息,所以会需要用到instance-level的语义分割,参考的文献仍然如Instance-Sensitive FCN。
- 目标导向的语义分割:语义分割终究是一个太宽泛的方向,具体在自动驾驶上,有些物体比如天空就无需多精确地分割出来,所以说,要考虑到具体的应用,做定制化的语义分割。
- 变化多端的物体:比如说行人的姿态结构就可以变化多样,那么用一些更加复杂的网络比起plain network可能能更好地处理这些复杂物体,参考文献如:Not all pixels are equal: Difficulty-aware semantic segmentation via deep layer cascade
- Corner Case Mining:临界/极端情况挖掘,由于物体间高度耦合,很难挖掘一些临界场景,可以用Synthetic sequences来设计出这些场景。
另辟蹊径
其实就是替代性的自动驾驶解决方案!
- Multi-task Learning,比如同时进行光流估计和语义分割https://arxiv.org/abs/1607.07716
- End-to-end learning,端到端的学习,就是不要搞那么多花哨的语义分割和目标检测的模块,精确的目标检测并非安全的自动驾驶所必需的,这也更符合人类开车的直觉。谁会一边开车一边对车前方的各种物体做检测识别呢,在乎的是只要别撞上我就行了。端到端学习的好处是不需要那么多annotation,驾驶的信息只来自于Controller Area Network (CAN) signals,输出的也只有brake,steering,acceleration,比起语义分割的简单多了。Uber就把未来押在这个方向上了。参考End to end learning for self-driving cars,和LeCun他们的Off-road obstacle avoidance through end-to-end learning。
- Modular End to End learning,这里比上面多了一个modular,代表在e2e的基础上增加了辅助损失函数来保证safety和interpret ability,这种结构往往优于单纯的e2e。比如Fisher Yu他们的End-to-end learning of driving models from large-scale video datasets
示意图如下:


————————————————————————————————————-
语义分割社区常用的一些工程最佳实践:
- 用3x3卷积核,类似VGG中一样,这样可以保护feature map分辨率
- 强烈推荐dilated convolution
- 为了达到实时,使用浅层网络,以寻找accuracy和efficiency之间的trade-off
- Batch Normalization,加速收敛很有用。
- 输入图片的分辨率会影响分割效果,比如分辨率比较大的时候,小物体(如行人)就比较好分割;使用random crop来缓解类别不均衡的问题
- skip connection,这在许多语义分割网络中都用到了,比如FCN和U-Net等,效果会好但是会耗显存。
————————————————————————————————————-
收获:对语义分割的技术概况,自动驾驶的相关技术有了更多的理解和把握;但是,以上仍然是一个比较泛的review,具体的研究突破点依然要从小方向上去寻求。
================================================================















 6682
6682











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









