







使用ResNet50训练Market1501
0x00参考
⭐️郑哲东博士的GitHub
从零开始行人重识别-知乎
全篇对于上手person ReId 具有重要意义
环境:
torch_version=1.13.0+cu117
python_version=3.8.13
torch_version=1.10.2+cu102
python_version=3.6.13
没有的包pip install安装就好了,
修改pip源为清华源pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
需要GPU,纯CPU应该不够
0x01准备数据集
Market-1501很多找找都能下到
首先使用prepare.py处理数据集,自己下载的数据集文件位置记得改进去
运行完会生成一个pytorch文件
跑完之后,在pytorch的每个子文件夹中,图像都是按ID来排列的。
对于Market这个数据集,图像文件名就是它的ID/label
0x02搭建模型ResNet50
model.py中已经改好需要变动的地方:
Market中的类别数是751,原来使用的ImageNet的类别数是1000.
具体来看model.py的改动:
(continue…)
(win10)笔记本跑的报错
cannot import name ‘PY3‘ from ‘torch._six‘百度查的说是torch和torchvision版本不匹配,但此前运行别的项目都没这问题
解决办法:重装版本匹配的torch和torchvision,此句可行pip install --user --upgrade torch==1.10.0 torchvision==0.11.1 -i https://pypi.tuna.tsinghua.edu.cn/simple
写的很乱,总之就是CUDA和pytorch,torchvision版本都要兼容,官网可查

训练
(caiman).../Person_reID_baseline_pytorch-master$ python train.py --gpu_ids 0 --name ft_ResNet50 --train_all --batchsize 32 --data_dir ../data/Market1501/pytorch
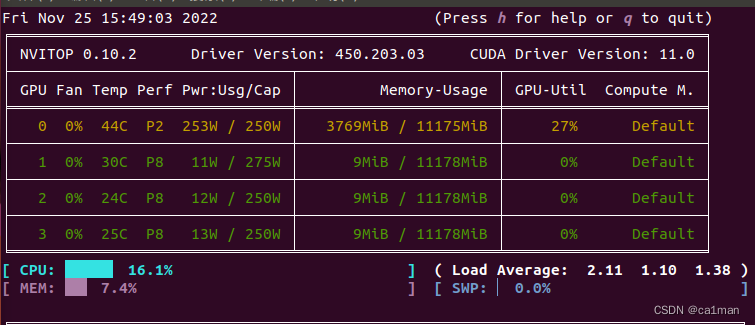
14:50终于开始跑
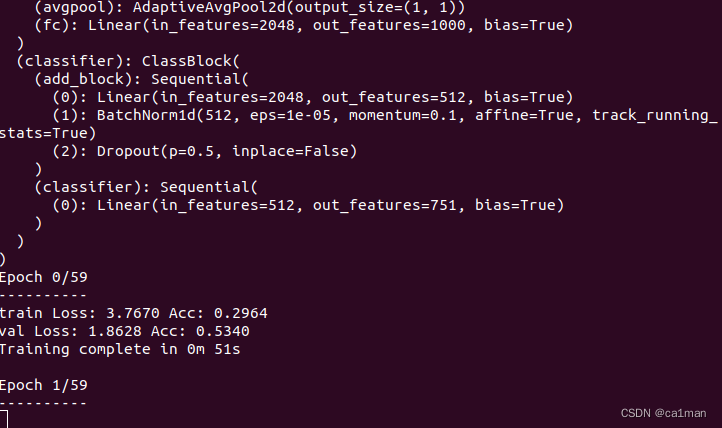
可以看到GPU利用率也很好
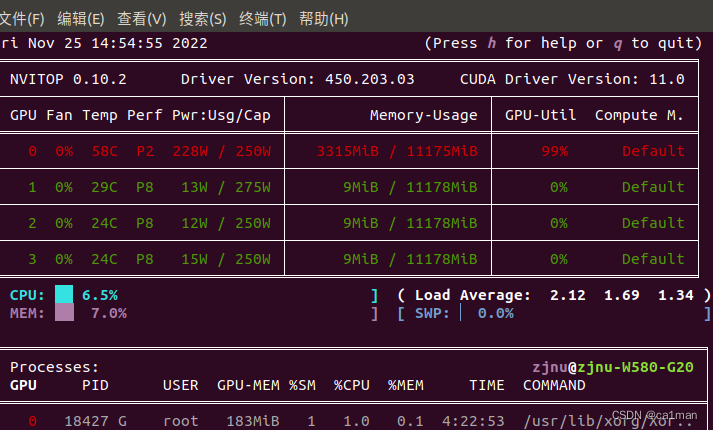
昨天做的上不去,一开始以为是训练数据太少,今天才知道装的pytorch和CUDA版本不匹配,还是不能太依赖别人的环境,重建了一个虚拟环境费点时间但是问题有源可寻
查看CUDA是否可用:print(torch.cuda.is_available())
查看CUDA版本:nvcc -V
50分钟训练完
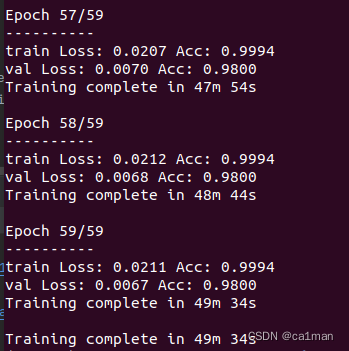
train_acc=99.94%
验证集的准确率到98%
0x03test
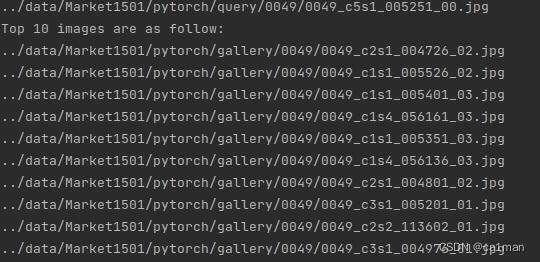
1.载入刚刚训练的模型来抽取每张图片的视觉特征
执行命令:
python test.py --gpu_ids 0 --name ft_ResNet50 --test_dir ../data/Market1501/pytorch --batchsize 32 --which_epoch 59
运行结果截图(part)
2. 用抽取的特征去匹配图像
运行evaluate_gpu.py
python evaluate_gpu.py

0x04可视化结果
值得注意的是demo.py中的14行dataset的位置根据个人的调整
运行命令
python demo.py --query_index 777
或者pycharm直接运行也行,前提是path都改成自己的了,前面几个操作我都在命令行现给的自己放data的路径
运行结果:
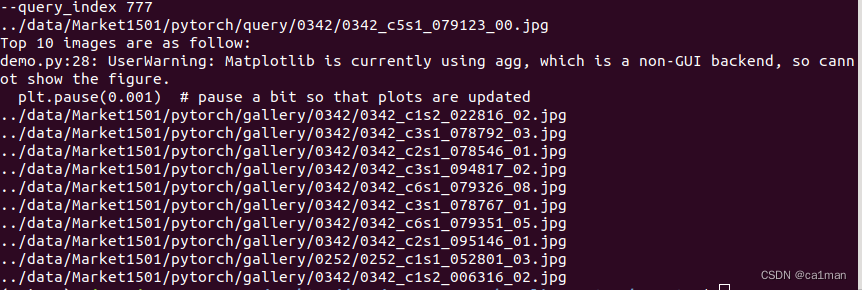
嘢,不能显示UserWarning: Matplotlib is currently using agg, which is a non-GUI backend, so cannot show the figureagg是一个没有图形显示界面的终端
看到第8行
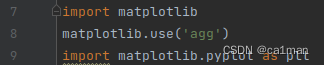
那把agg改成TKagg试试,TKAGG是有图形界面显示的终端,
修改之后能可视化了,但是看到一下top10就结束了,
查看代码,保存了结果在当前目录下,可以改一下保存路径
这是我的fig.savefig("../data/show.png")
在最后加句plt.waitforbuttonpress()可以停留运行结果不直接结束直到按键盘
运行结果:

python demo.py --query_index 123

Triplet Loss
1、同样的目录结构和数据集准备prepare.py
2、创建一个文件夹mkdir model
3、训练
python train_new.py --gpu_ids 2 --name ft_ResNet50 --train_all --batchsize 32 --data_dir ../data/Market1501/pytorch
会出现训练结束但是显存没有释放的情况
我都直接kill掉进程,🆘如果是组里共用的服务器可不能随便kill
使用2号GPU(即第三块GPU)对market1501的所有图像进行训练,保存模型名为’ft_ResNet50’,
batchsize=32,epoch=70
没有使用trick。
因为我的机器上有三张卡,所以我想将训练改为多GPU并行运算,但是一直报错,百度到的方法无用,还是等之后再多懂一些再改

训练占用内存比之前的大得多(3倍)

train Loss: 0.0004 Reg: 0.0000 Acc: 0.9961 MeanMargin: 0.5842
caiman'blog Please indicate the source when using
Training complete in 279m 45s
不知道为什么训练时间要4个半多小时
4、测试
1)抽取每张图片feature
python test.py --gpu_ids 1 --name ft_ResNet50 --test_dir ../data/Market1501/pytorch --which_epoch 59
2)用抽取的特征去匹配图像
Person-reID-triplet-loss-master$ python evaluate_gpu.py
训练时间长两倍但是效果一般,甚至略差于前者,可能和这个loss函数的特点有关,并不适用与此,值得分析…
DenseNet121
重新训练前者脚本一直报错torch.nn没有模块,估计是版本错误
不想变动caiman环境,所以换到gt环境torch_version=1.13.0+cu117,python=3.9
1、训练
python train.py --name ft_net_dense --use_dense --train_all

忘记换卡训练了,写博客好卡
2、提取特征进行匹配
python test.py --gpu_ids 2 --name ft_net_dense --test_dir ../data/Market1501/pytorch --batchsize 32 --which_epoch 59
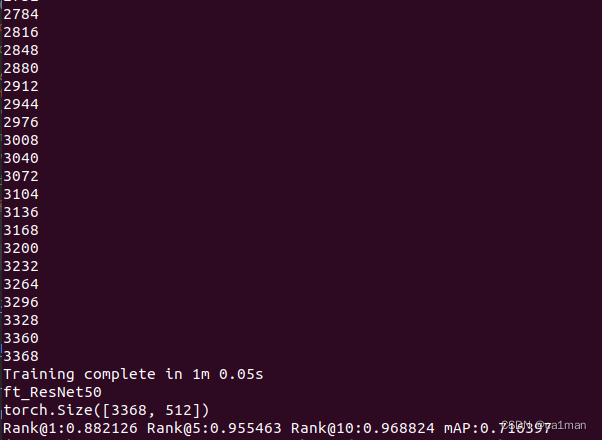
Training complete in 1m 2.90s
ft_net_dense
torch.Size([3368, 512])
Rank@1:0.888361 Rank@5:0.953979 Rank@10:0.971200 mAP:0.724890
PCB(多卡并行训练)
第一次尝试换多卡训练的时候,也是知道什么问题,但是改不好
再尝试再改又是另一种情况了,
计算机就是酱酱酿酿,常学常新🅰️
看了深度学习和行人重识别浙江大学罗浩博士,再次重新尝试修改程序为多卡训练:
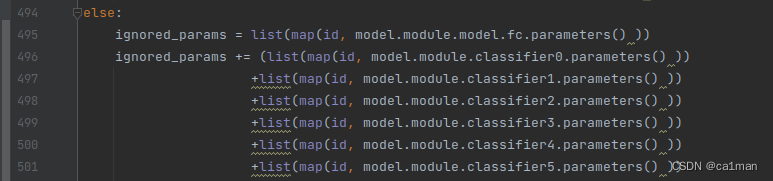
一句话,使用pytorch并行库之后,
调用参数从model.parameters()都要改成model.module.parameters()

python train.py --name PCB --PCB --train_all --lr 0.02
每20epoch降低0.01学习率,60轮,batch size=32
原来一张卡训练完是130分钟
train Loss: 0.1798 Acc: 0.9994
val Loss: 0.0384 Acc: 0.9800
Training complete in 129m 45s
三张卡是89分钟
train Loss: 0.2067 Acc: 0.9994
val Loss: 0.0157 Acc: 0.9800
Training complete in 88m 53
python test.py --name PCB --batchsize 32 --which_epoch 59
测试的时候还是有很多问题,尝试很多方案,比如载入model之前也用上DataParallel()包装model;去掉字典中的module,报错是没有key’state_dict’解决Error(s) in loading state_dict for *** :
但是有的方法好像通了之后,报错RuntimeError: Cannot insert a Tensor that requires grad as a constant. Consider making it a parameter or input, or detaching the gradient
改别人的代码就是麻烦,有空再来写吧,直接用别人的代码的话,单卡跑着先😢需要学习的还多得很...
😃转载请注明出处:
[ca1man_实验记录1ReID](https://blog.csdn.net/bocaiaichila/article/details/128031789)



















 241
241

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











