









 特征平台旨在解决AI模型开发中数据准备的难题,如算法与大数据技术栈的脱节、跨部门协作困难和特征工程的挑战。它提供了一种机制,使数据科学家和算法工程师能更有效地访问、服务和保证特征的准确性和一致性。Feast、OpenMLDB和Feathr是开源的特征平台代表,分别有各自的优缺点。特征平台的发展与MLOps趋势紧密相关,成为机器学习生命周期中不可或缺的部分。
特征平台旨在解决AI模型开发中数据准备的难题,如算法与大数据技术栈的脱节、跨部门协作困难和特征工程的挑战。它提供了一种机制,使数据科学家和算法工程师能更有效地访问、服务和保证特征的准确性和一致性。Feast、OpenMLDB和Feathr是开源的特征平台代表,分别有各自的优缺点。特征平台的发展与MLOps趋势紧密相关,成为机器学习生命周期中不可或缺的部分。
1. 特征平台背景
众所周知,AI算法模型的开发与落地,大致可以划分以下三个阶段:
- 数据准备
- 模型训练
- 模型部署
其中,模型训练的本质是大规模数据计算得到模型,行内黑话“炼丹”;而模型部署则类似于传统软件工程中的在线服务部署。
数据准备阶段往往是工作量最大的也是较为困难的阶段, 究其原因:
-
算法与大数据的脱节
算法一般而言需要的数据量较大,因此需依托于大数据平台并使用大数据的相关技术, 但是算法开发人员往往对大数据的技术栈并不熟悉(算法同学不熟悉Hadoop、Hive、Spark、Java、Scala);同时大数据的同学也对算法技术栈和工作也不熟悉(有Spark ML,但大数据开发用的不多);
-
大数据与算法跨部门协作困难
大数据与算法可能是两个部门或者团队,因此有部门墙的存在,跨部门协同难,需要协调资源;并且有建设目标的差异,算法同学的需求优先级并不一定高, 有时候需要算法同学亲自上手;
-
特征工程的困难
“Coming up with features is difficult, time-consuming, requires expert knowledge. ‘Applied machine learning’ is basically feature engineering.”
"”解决特征问题是极其困难、耗时以及要求专业知识。应用机器学习(Applied machine learning) 基本上是特征工程。”
—— 吴恩达
数据科学家需要花接近 80% 的时间在特征工程上(很困难、耗时的过程,同时要求 **领域知识(Domain Knowledge)**和数学计算)
因此需要提供一个桥梁打通大数据与算法模型之前的沟壑, 解决上述的困难。于是,2017年 Uber 提出 “Feature Store” 的概念,试图解决这些困难。
Feast: Bridging ML Models and Data
2. Feature Store定义
“Feature Store” 中文没有标准的翻译, 可以翻译为:“特征商店”、“特征平台”,但是不适合翻译为:特征存储(特征向量数据库)。 在国内,如果非要使用“中台”饭圈文化进行理解的话, 翻译为 “特征中台” 我觉得可能更有助于大家的理解。 目前国内翻译为特征平台更为流行和贴切,因此下文都称“特征平台”。那么到底什么是特征平台,有哪些特点呢?
2.1 特征平台需求层次
关于「马斯洛需求层次理论」
(图注:马斯洛的需求层次金字塔,底层代表基本需求。 来源)
生理需求:是生存所必需的,例如空气、水、食物、住处等。不满足这个需求,人类身体将无法正常工作。只有满足了这一最重要的需求,才会考虑其它需求。
安全需求:在生理需求被满足的前提下,需要保障安全,包括人身安全、健康、经济安全、就业、法律秩序、社会稳定等。这一需求通常由家庭、社会和政府满足。
社交需求:感到社会群体对自己的认可和接受。这类群体包括同事、教友、职业机构、体育俱乐部、在线社区等,也包括家庭、朋友和导师。
尊严需求:基于能力和成就。较低层次的尊严需求来自他人,包括他人的尊重认可和在其他人中的声誉。较高层次的尊严需求来自自己,包括对自己的尊重和内在的成就感。
自我实现需求:最高层的需求,是个人潜力的完全实现。对自我实现的需求因人而异。有的人希望成为完美父母,而有的人强烈希望在经济上、学术上、体育上取得成功。人们通过发明、艺术、写作等方式表达这种需求。
同样,特征平台会首先满足最必要和急迫的需求(包括特征读取和特征服务),再去考虑高阶需求。
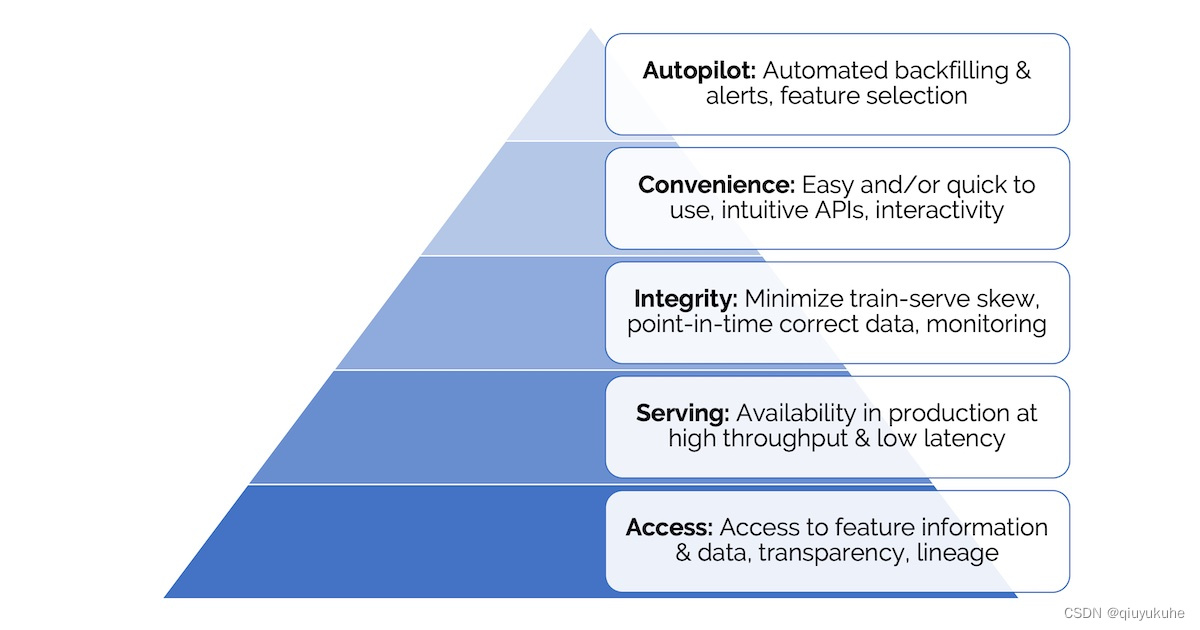
(图注:特征平台需求层次)
最底层是访问(access)的需求。 这一层需求包括特征可读取、特征转换逻辑透明和特征血缘可溯。它们使得特征能被发现、分享和复用,减少重复。
从前,算法工程师进行机器学习开发时,60%的时间都花在编写特征转换逻辑上。—— Airbnb
其次是服务(serving)的需求。 这一层的核心需求是为线上服务提供高吞吐、低延迟的特征读取能力,而无需通过 SQL 去数据仓库读取。其它需求还包括:与已有的离线特征存储集成,使得特征能够从离线特征存储同步到在线特征存储(例如 Redis);实时的特征转换等。
通常,数据工程师会将数据科学家实现的特征重新实现为可以在生产环境运行的特征管道。这个重复实现的过程会让项目推迟数月交付,让跨团队合作极为复杂。—— GoJek
两个底层需求被满足后,我们诉诸准确(integrity)需求。最常见的需求是最小化 train-serve skew,确保特征在训练和服务环境下是一致的。另一个常见需求是 point-in-time correctness(又称 time-travel),以确保历史特征和标签被用于训练和评估时不存在 data leaks。
训练通常是离线的,而服务通常是实时的。保证训练和服务环境下的数据一致性极为重要。—— Uber
再往上,是便利的需求。特征平台需要足够简单好入手,例如提供简单直观的接口、易交互、易 debug 等,才能让大家采纳和受益。
记住,我们是个平台组。我们要搭建工具把提供给用户,让他们能够自己动手丰衣足食。—— Uber
最后是自治(autopilot)的需求。包括自动回填特征、对特征的分布进行监控和报警等。我知道有些公司有做这一层的事情,但我没怎么读到相关材料。
特征回填是训练集迭代最主要的瓶颈。解决这一问题能极大地加速数据科学家的工作流。—— Airbnb
并非所有团队都有全部五层需求,对大部分团队而言,满足第一、二层和部分第三层的需求就很受益了。不同团队对于每一层需求的程度要求也不同。在线场景少的团队相比每秒需要处理几百万请求的的 DoorDash 团队,当然更少关心特征服务的需求;如果模型和特征每天更新多次,则更少需要关心 point-in-time correctness。
在逐层了解对特征平台的需求后,让我们来看看不同的公司是如何实现这些需求的。
对「创新者窘境」的借鉴
特征平台需求层次借鉴了「 创新者窘境」所介绍的产品演进模型。
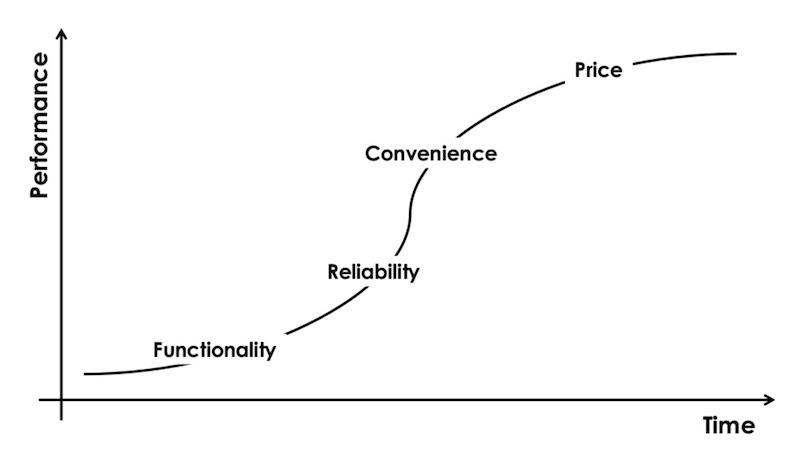
(图注:竞争的演进,从功能、可靠、便利到价格)
功能:当市场上没有一个产品满足功能方面的需求,竞争的基础在于功能。这款产品能否做到竞品做不到的事情?
可靠:当超过两个产品能满足功能的需求,消费者会选择更可靠的产品。这款产品质量是否稳定?
便利:当多个产品能满足可靠的需求,消费者会选择更便利的产品。这款产品是否容易使用?
价格:最终,当多个产品都能满足便利的需求时,竞争的基础转移到价格上。这款产品是否更便宜?
2.2 访问:发现、去重和复用
如果特征难以访问,以下情况会发生:
- 不同团队反复实现同一个特征,导致同一特征可能有多达 10 个版本。
- 部署多个相近的特征管道,浪费计算和存储资源。
- 因为同一特征有多个版本,不同模型会使用不同版本的特征,很难得到一致的结果。
- 迭代变慢。
表达同一业务概念的特征被多个团队反复开发,已有工作无法复用。—— GoJek
为了解决这一问题,GoJek 搭建 Feast 作为数据工程师、数据科学家和算法工程师合作的接口。数据工程师和数据科学家创建特征,并提交给特征平台。随后,算法工程师消费特征,而无需自己创建。
(Feast 扮演了团队间沟通的接口)
Uber 也采用了相似的做法,通过搭建 Palette 特征平台,鼓励不同部门分享和复用 Palette 中的特征。这种做法最小化了重复工作,让机器学习的的结果更加一致,加速机器学习的进程。
特征的可发现性使得特征易于发现和使用。在这个层次上,特征平台基本上是个包含很多特征的存储,和数据仓库的区别不大。把两者区分开的是特征平台还能满足特征下一层次的服务需求。
2.3 服务:在实时环境使用特征
我们常用批数据离线训练模型,然而在线模型服务需要实时读取这些特征。这难住了很多团队——应该如何为在线模型服务高吞吐、低延迟地提供(serve)这些特征?
我们在开发模型的过程中发现:很多用于训练的特征,并无法在生产环境中获取。—— Monzo Bank
Monzo Bank 能从离线分析环境(用于模型训练)中获取特征,但无法从生产环境(用于模型服务)中获取特征。Monzo Bank 采用了一个轻量的解决方案,将离线分析存储(BigQuery)中的特征同步至在线存储(Cassandra)。
- 首先,在离线分析环境的 SQL 建表语句中加入标签。这些表的更新频率在小时或天级别。
- 特征平台中的 Go 服务检查特征表 schema 的正确性,例如必需的
subject_type和subject_id列是否存在。 - 有个 cron job 监听特征表的更新,将数据变动从 BigQuery 经过 Google Cloud Storage 的中转同步至 Cassandra。
Uber 的 Palette 采取了类似的双存储设计。离线存储(Hive)保存特征快照,用于训练。在线存储(Cassandra)实时提供同样的特征。特征由 Flink 生成,写入 Cassandra。两个存储之间会进行特征同步:添加到 Hive 的特征会被复制到 Cassandra,添加到 Cassandra 的特征会被 ETL 到 Hive。
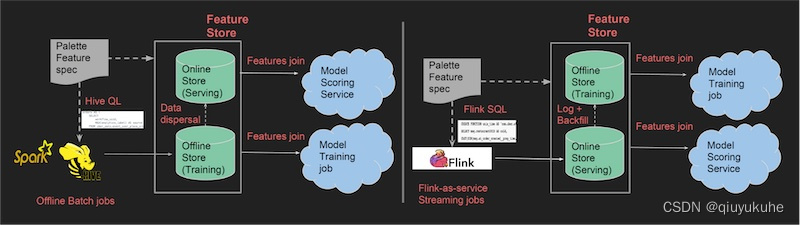
(图注:创建批特征(左边)和实时特征(右边),并在存储间同步。来源)
DoorDash 搭建了超大规模的特征平台,将特征服务做到极致,满足以下需求:
- 支持在可持久、可伸缩的存储中保存十亿级别条数的特征。DoorDash 有百万级别的特征实体(entity)和十亿级别的特征。
- 支持百万级别 QPS(Queries per second)。特征平台有多个使用场景,其中包括餐厅排序。这一场景使用大量特征,每秒做出超过一百万次预测。综合来看,特征平台的 QPS 超过一千万。
- 支持非实时特征每日一次的快速批更新,和实时特征(例如餐厅过去 20 分钟的平均送餐时长)一天内不断的更新。
DoorDash 在评估了 Redis、Cassandra、CockroachDB、ScyllaDB 和 YugabyteDB 后,选择了 Redis。这篇好文介绍了 DoorDash 的评估过程和针对 Redis 做的后续优化。
2.4 准确:创建正确的在线和离线特征
在满足服务的需求后,我们来看准确需求。准确性解决的主要痛点是:
- 难以创建 point-in-time correct 的特征,用于模拟生产环境。做不对的话,会导致 data leaks。
- 训练和服务环境特征的不一致,导致模型上线后表现欠佳。
为了解决第一个痛点,Netflix 实现了分布式 time-travel。它给离线和在线数据建立快照,快照内容包含成员类型、设备、当天时间等。

(图注:从离线和在线的微服务创建快照。来源)
然而,为每一个 context 都建立快照的成本很高。因此,Netflix 对观看模式、设备类型、设备使用时长、地区等离线特征进行分层抽样,这些样本很好地代表了用于模型训练和评估的数据的分布。抽样通过 Spark 完成,快照存储在 S3 中。
Netflix 也会对在线特征建立快照。数据产生自数百个微服务,数据包括观看历史、个性化观看列表、评分预测等。数据由 Spark 通过 Prana 并行获取,制成快照,以 Parquet 格式存储在 S3 上。
为了解决 train-serve skew 这第二个痛点,GoJek 用 Apache Beam 实现数据处理管道,消费来自批和流数据源(例如 BigQuery 和 Kafka)的数据,注入离线和在线存储(例如 BigQuery 和 Redis),并提供统一的接口来读取历史和实时数据。这种做法避免了因在生产环境重写特征管道而引入 train-serve skew。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GElRfPEZ-1675599050200)(特征平台概况.assets/gojek-feast.jpeg)]](https://i-blog.csdnimg.cn/blog_migrate/4b52b20d3857ad2231b5f6c6c17e1f69.jpeg)
(图注:GoJek 基于 Apache Beam 的特征注入。来源)
Netflix 则通过共享的特征编码器(encoder)解决这一痛点。尽管他们在离线(Spark)和在线环境实现了不同的特征生成管道,但不同管道共用特征编码器(即同样的类、库和数据格式)。这也保证了特征生成过程在训练和服务环境的一致性。
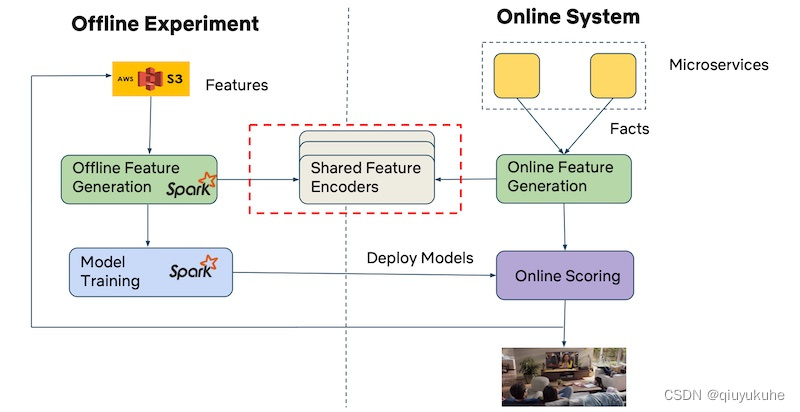
(图注:Netflix 的离线和在线特征生成使用同一个编码器。来源)
我们在前文介绍过 Uber 如何保持离线(Hive)和在线(Cassandra)特征存储的数据同步。任意一个存储的新特征都会被复制到另一个存储,确保训练和服务环境中数据的一致性。
为确保特征的准确,还需引入监控,回答以下问题:
- 特征最近一次更新是什么时候?
- schema 正确吗?数据分布发生了偏移吗?
- 特征服务达到了吞吐和延迟的要求吗?
Airbnb Zipline UI 向数据科学家展示特征的分布、特征和标签之间的相关性、聚类分析(尚不清楚基于什么做聚类分析)。类似地,Uber Data Quality Monitor 通过以下方法给用户展示每日数据质量分数和异常报警:
- 首先,搜集特征的指标,例如数值特征的均值、中位数、最大值、最小值,以及类别特征的唯一值个数和缺失值个数。
- 其次,基于指标建立多维时间序列,使用主成分分析(PCA)选取出要保留的主成分。
- 最后,使用主成分建立时间序列。如果当前测量值和上一步的预测值不匹配,则将该特征标记为异常。
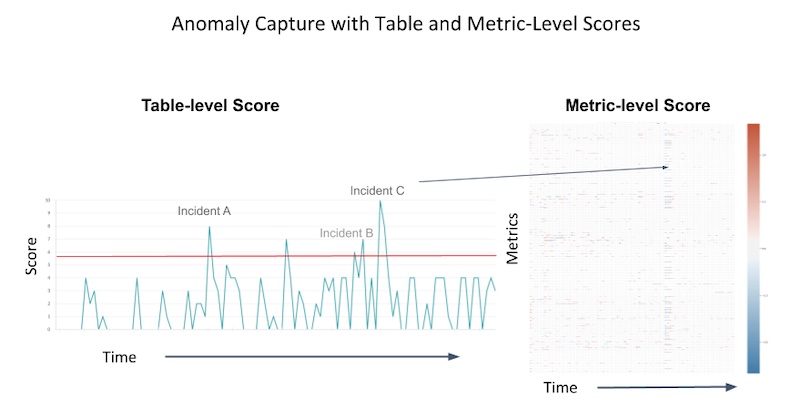
(图注:数据质量随时间的变化,以及当事故发生时。来源)
2.5 便利:尽量简单
当前,关于特征平台的便利需求,讨论并不多。但显然,好用的工具和平台非常重要(想想 PyTorch 和 Tensorflow 的对比)。
我找到的最好的例子来自 GoJek。GoJek 实现提供了统一的 Python、Java 和 Go SDKs,让用户可以在不同语言中几乎无区别地使用 get_batch_features() 和 get_online_features() 接口,简化从离线存储和在线存储中获取特征的过程。
customer_features = ['credit_score', 'balance', 'total_purchases', 'last_active']
historical_features_df = feast.get_historical_features(customer_ids, customer_features)
model = ml.fit(historical_features_df) # pseudo code
online_features = feast.get_online_features(customer_ids, customer_features)
prediction = model.predict(online_features)
此外,Netflix 实现了简单的接口,让数据科学家能够容易地创建 point-in-time correct 和特征和标签。下面的例子展示如何读取电影 OUTATIME 的观看历史快照。
val snapshot = new SnapshotDataManager(sqlContext)
.withTimestamp(1445470140000L)
.withContextID(OUTATIME)
.getViewingHistory
基于该快照,用户只需提供以下内容,即可进行 time-travel,创建用于训练和评估的特征:
- 上下文:模型在何地何时被如何使用,例如国家、设备、成员档案、电影、时间等,其中时间非常关键。
- 物品:要评分或排序的物品,例如电影、推荐名单、搜索项等。
- 标签:监督学习的目标,例如点击、已看、观看分钟数等。无监督学习不需要这些内容。
- 特征编码器:如何将上下文和物品组合起来创建特征,例如国家-电影、用户 ID-电影等。
2.6 自治:尽量自动
最顶层是自治需求。自治可以降低开发难度和运维成本,否则数据科学家需要花时间进行枯燥的手动操作。目前,有些公司分享了相关经验,但自治在业界还不普遍。
Airbnb 发现数据回填成为数据科学家迭代模型实验的瓶颈。因此,Zipline 支持自动特征回填。数据科学家可以在简单的 UI 上定义新特征,指定开始和结束日期,以及回填任务的并行进程个数,随后这些特征就会通过 Airflow 管道添加到到已有的训练特征集中。
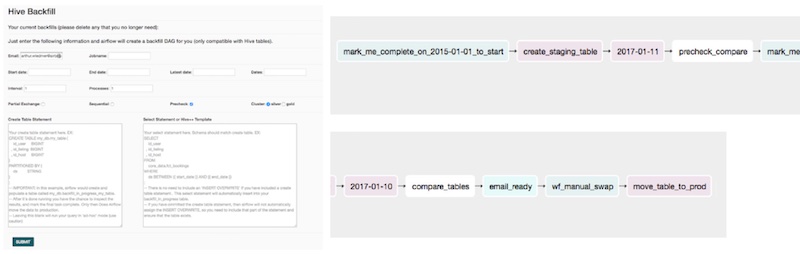
(图注:Airbnb 特征回填 UI,和它所创建的 Airflow DAG。来源)
下面是自治方面的其它实践:
- Netflix Metacat 提供了特征表的成本和存储空间指标,便于删除不用的特征表,节约成本。
- Uber Data Quality Monitor 进行自动的异常检测,基于数据质量指标和每日数据质量分数进行通知。
- Uber 实验支持自动特征选择。用户只需提供要预测的标签,Palette 就能推荐出与标签有关的特征。
对于中小企业一般关注前三项:访问、服务、准确就足够了, 只有较大特别复杂的场景对后面两项关注比较多。例如,目前在我司的算法应用场景对特征平台的访问、服务、准确这三项就较为关注。
注意:特征平台不适合所有的场景, 按需取舍
3. 特征平台架构
特征平台在机器学习生命周期扮演的角色:
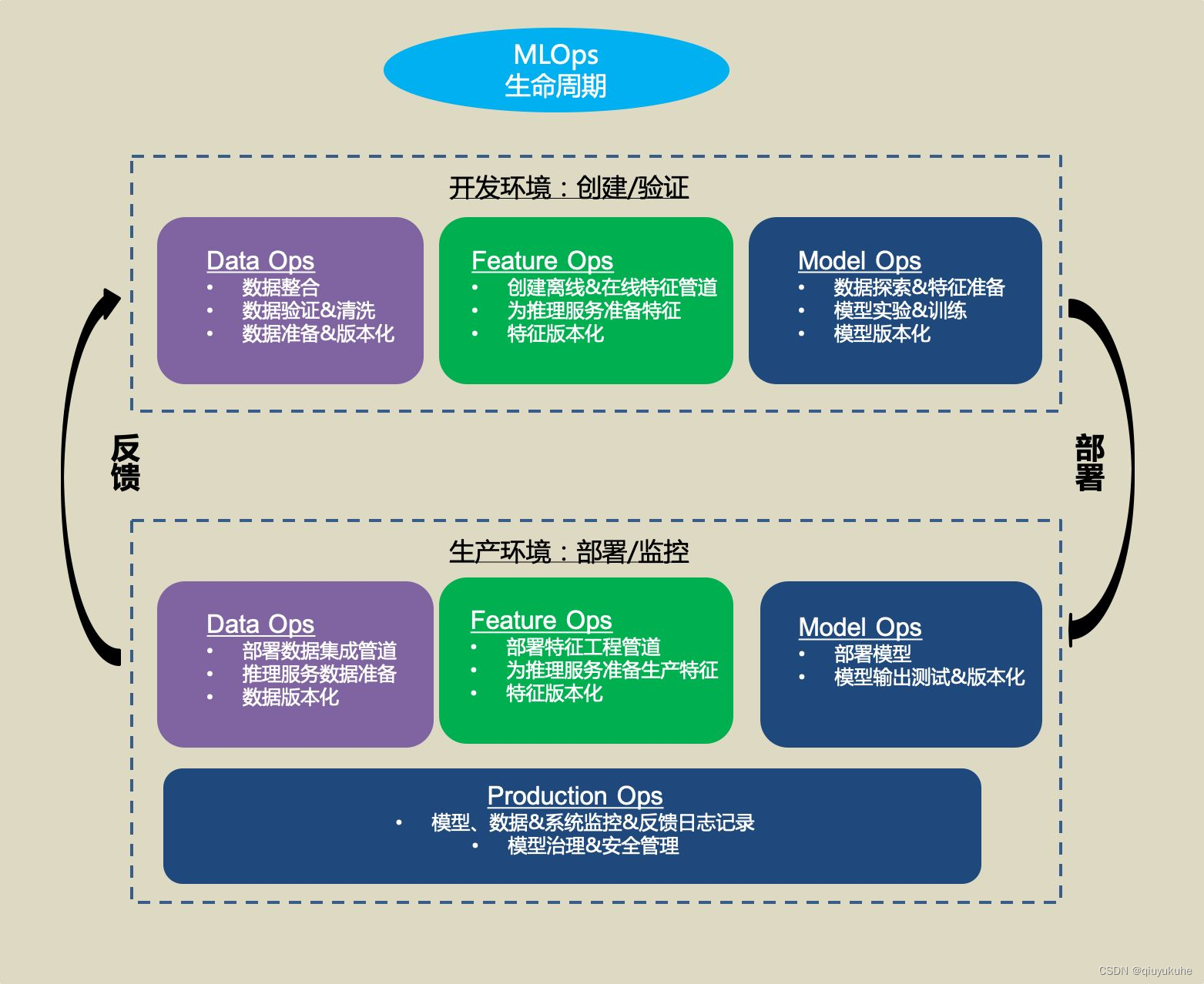
特征平台的技术架构
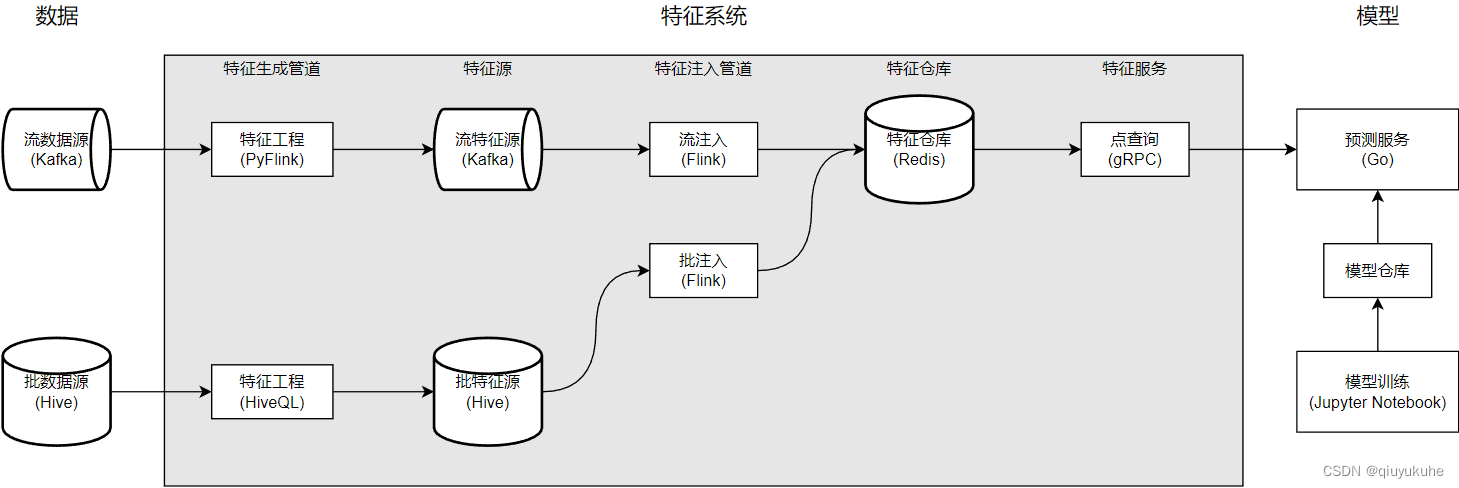
可以看出Redis作为特征仓库进行广泛使用。以特征平台这个架构为例,如果把特征认为是公司的数据资产(特征完全符合数据资产的定义), Redis也是可以作为数据资产的存储组件(一次在公司的数据资产大数据技术架构评审时, 阿里的专家老师对把Redis作为数据资产存储组件之一进行了挑战和质疑)
4. 特征平台发展历史
特征发展史:
-
2017年 Uber 提出feature store的概念
-
2018年12月 logical clocks公司开源Hopsworks项目
-
2019年1月 go-jek公司开源Feast项目
-
2020年至今多个大厂发布商业产品
-
2021年6月 4Paradigm开源OpenMLDB
-
2022年4月 LinkedIn开源Feathr
Datanami 引用 Tecton.ai 联合创始人的话,称 2021 年为特征平台之年,2021年之后特征平台就如雨后春笋一样的冒出来了。上述的特征只有一家来自中国, 那就是4Paradigm(第四范式)开源的OpenMLDB, “碰巧”开源的时间也是2021年。
5. 特征平台技术选型
以下是目前已知的特征平台列表:
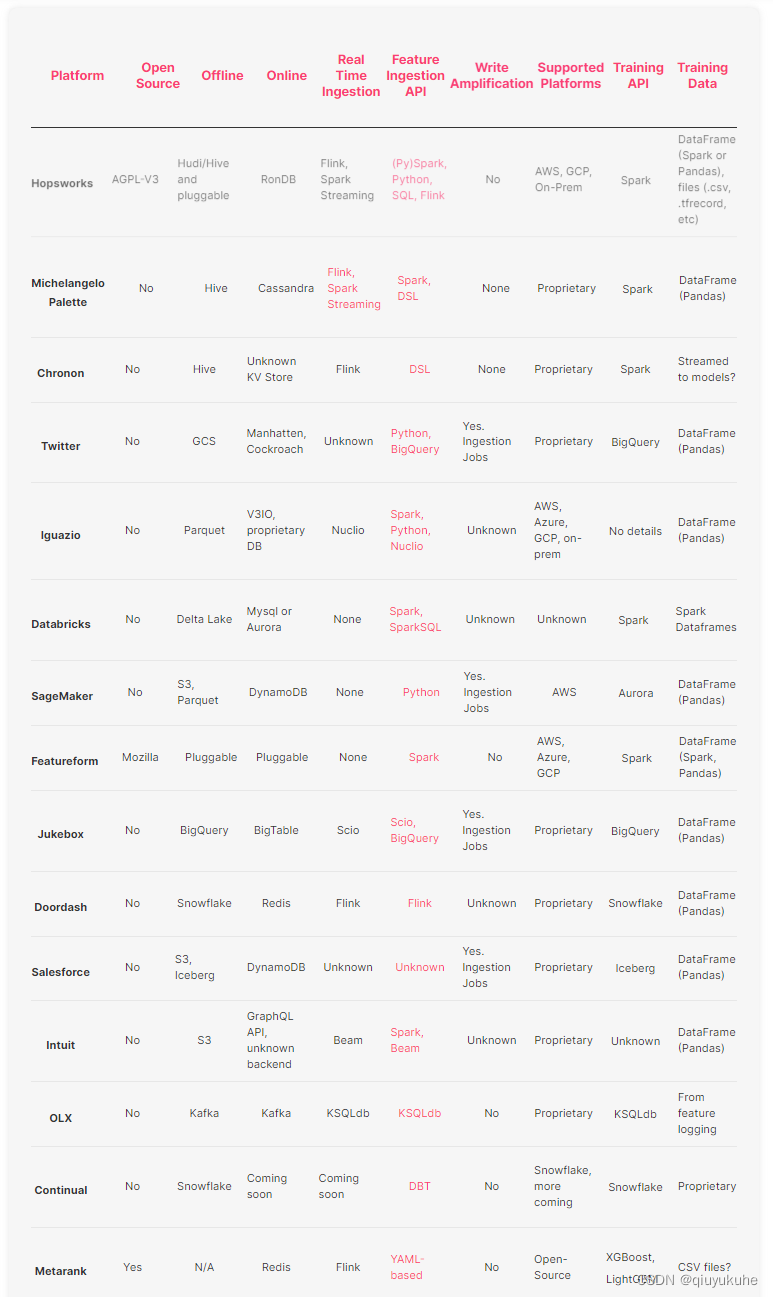
来源
我们重点介绍开源特征平台。
5.1 Feast (Feature Store)
2019年,GO-JEK(一家SaaS解决方案公司)开源Feast——Feast(特征存储)是一个可定制的业务数据系统,它重新利用现有的基础设施来管理和服务于机器学习特征的实时模型。
技术架构:
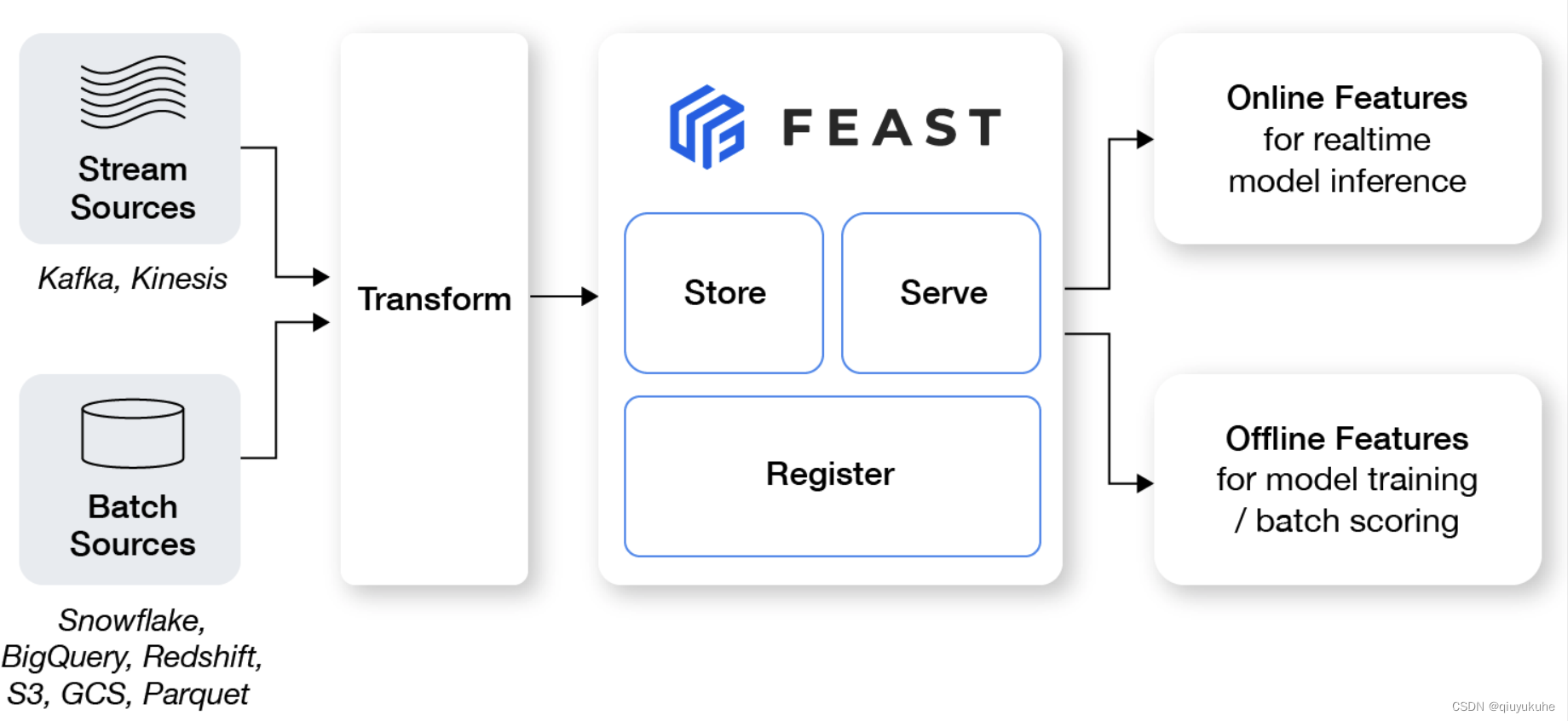
用户:

优点:支持批和流的特征,功能较为完善(官网Roadmap),生态也较为完善,社区较为活跃,版本发布也较快,Github上近4K Star。设计简单,轻量级,使用Python 开发对算法人员更友好;
缺点:1.但是有些插件是非官方贡献的, 稳定性与兼容性需测试;2. 没有中文文档。
5.2 OpenMLDB
国内的第四范式在219年开源的, OpenMLDB 是一个开源机器学习数据库,产品定位:线上线下一致的生产级特征计算平台。
技术架构:
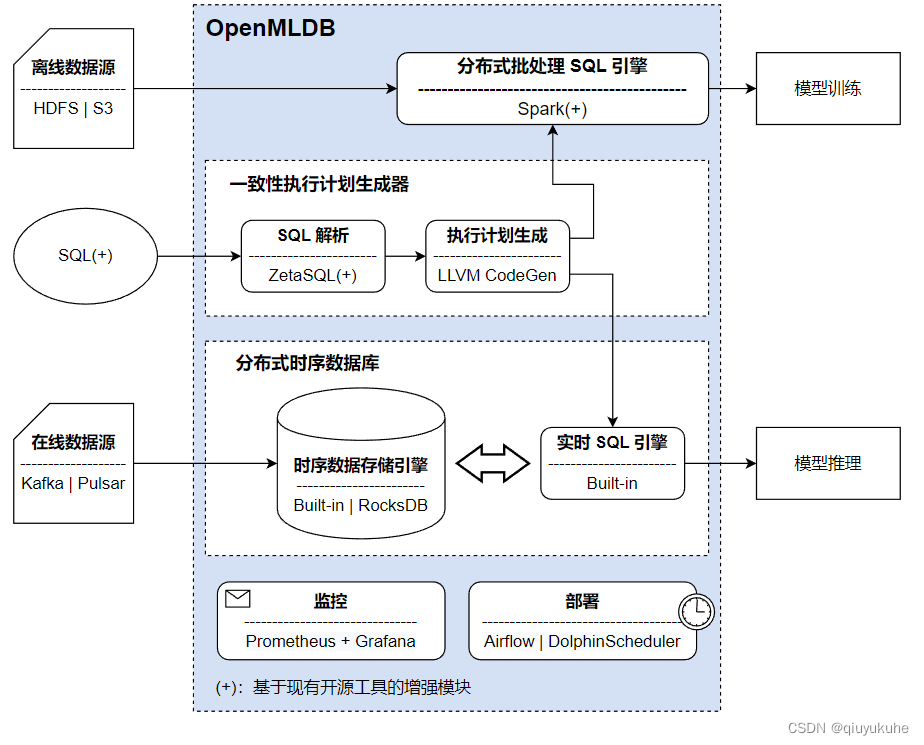
最新的0.7版本计算引擎基于Spark 3.2 二开,核心技术有论文支持,并获奖。
四大核心特性
- 线上线下一致性: 离线和实时特征计算引擎使用统一的执行计划生成器,线上线下计算一致性得到了天然的保证。
- 毫秒级超低延迟的实时 SQL 引擎:线上实时 SQL 引擎基于完全自研的高性能时序数据库,对于实时特征计算可以达到毫秒级别的延迟,性能远超流行商业内存数据库(可参考 VLDB 2021 上的论文),充分满足高并发、低延迟的实时计算性能需求。
- 基于 SQL 定义特征: 基于 SQL 进行特征定义和管理,并且针对特征计算,对标准 SQL 进行了增强,引入了诸如
LAST JOIN和WINDOW UNION等定制化语法和功能扩充。 - 生产级特性: 为大规模企业应用而设计,整合诸多生产级特性,包括分布式存储和计算、灾备恢复、高可用、可无缝扩缩容、可平滑升级、可监控、异构内存架构支持等。
有中文文档, 这点对国内的用户较为友好。
缺点:
- 开发语言较为复杂:
主要使用C++ 对于算法同学来说二开和bug的解决, 有点一定的门槛。
- OpenMLDB控制权在第四范式手里面, 未来有一定的不确定性(如果贡献给Apach之类社区的就好了, 不能道德绑架);
- 数据来源主要支持Hive、Kafka等 有点单薄;
4.使用SQL对特征工程的支持有点单薄
5.3 Feathr
Feathr 定位为:企业级高性能特征平台, 由LinkedIn 领英在2022年 4 月份开源,于2022年 9 月份捐献给 LF Data & AI 社区。
技术架构图:
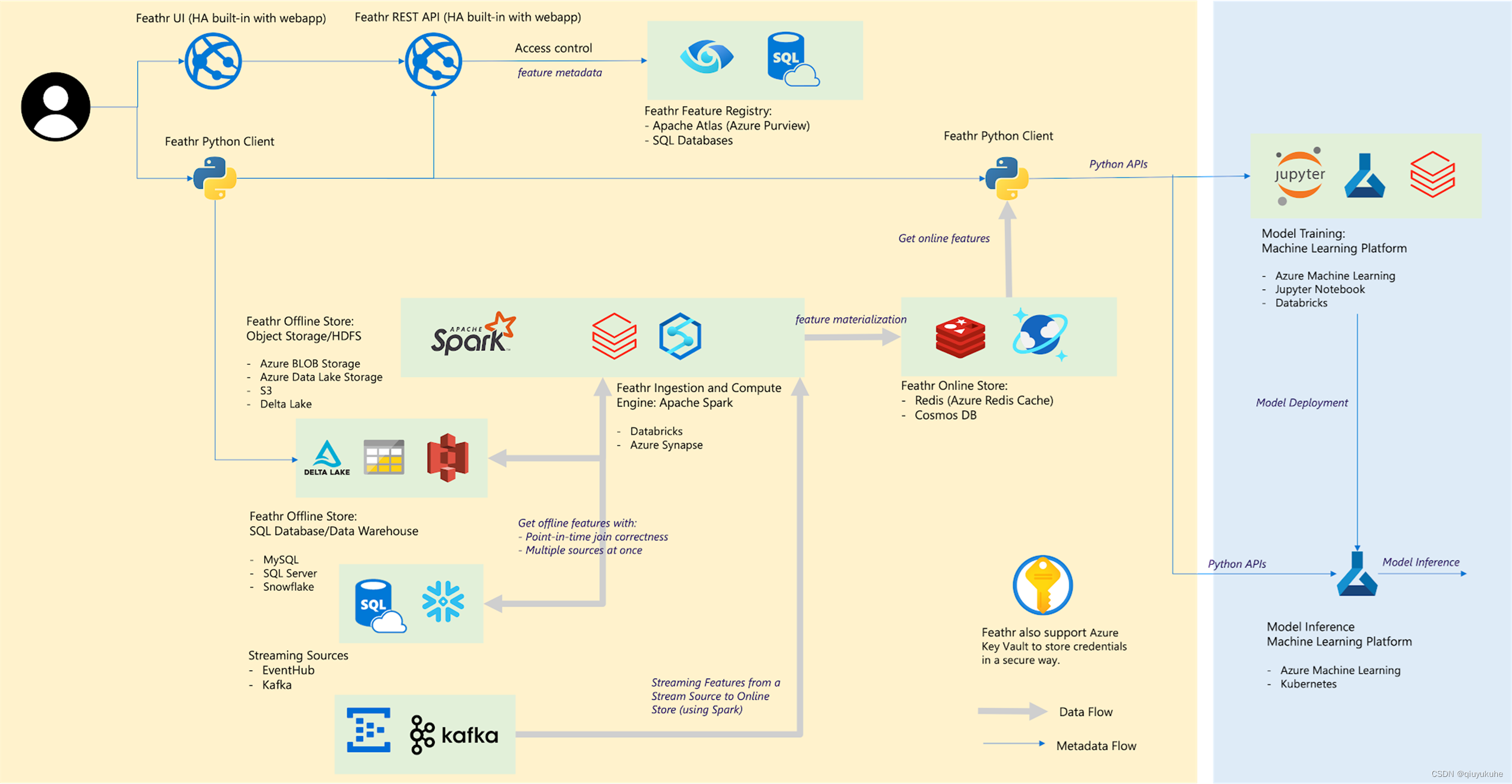
优点:1. 已捐献给社区,由社区维护预期发展会更好;2. Feathr UI 来进行特征的探索和发现;3. 企业级的特性,例如基于角色的访问权限控制(RBAC);
缺点:1. 功能尚不完善,Roadmap还有许多未实现;2. 开源时间不久,用户较少;
综述:这三个开源的特征平台各有优缺点, 如果你熟悉C++,OpenMLDB是可能最值得试一试,它有中文文档并使用SQL定义对开发友好; 如果不是很熟悉C++, Feast、Feathr 、OpenMLDB都值得一试,他们的技术实现差异较大,可以结合您所在的公司的大数据平和、算法平台,综合考虑选择最贴合需求的工具。
近年来,MLOps的概念被提出之后,MLOps也取得了较大的发展,特征平台作为MLOps最核心的能力之一, 也被大家越来越重视和发展。国外出现了较多的商业公司做MLOps,也取得了不错的融资, 但是国内目前还较少这样的商业公司。2021年被称作特征平台的元年, 但是也要清楚认识到一些特征平台还不足够成熟,需要大家更多的关注和共同的参与才能不断的完善。
6.社区与资料
Feature Stores: A Hierarchy of Needs
星策社区

















 614
614

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









