






布隆过滤器简介
布隆过滤器(BloomFilter)是1970年由布隆提出的一种空间空间效率很高的随机数据结构,它利用位数组很简洁地表示一个集合,并判断一个元素是否属于这个集合。使用布隆过滤器,存在第一类出错(Falsepositive),但是不会存在第二类错误(Falsenegative),因此,布隆过滤器拥有100%的召回率。也就是说,布隆过滤器能够准确判断一个元素不在集合内,但只能判断一个元素可能在集合内。因此,BloomFilter不适合“零错误”的应用场合。在能够容忍低错误的应用场合下,BloomFilter通过极少的错误换取了存储空间的极大节省。我们可以向布隆过滤器里添加元素,但是不能从中移除元素(普通布隆过滤器,增强的布隆过滤器是可以移除元素的)。随着布隆过滤器中元素的增加,犯第一类错误的可能性也随之增大。直观的说,bloom算法类似一个hash set,用来判断某个元素(key)是否在某个集合中。和一般的hash set不同的是,这个算法无需存储key的值,对于每个key,只需要k个比特位,每个存储一个标志,用来判断key是否在集合中。
算法:
1. 首先需要k个hash函数,每个函数可以把key散列成为1个整数
2. 初始化时,需要一个长度为n比特的数组,每个比特位初始化为0
3. 某个key加入集合时,用k个hash函数计算出k个散列值,并把数组中对应的比特位置为1
4. 判断某个key是否在集合时,用k个hash函数计算出k个散列值,并查询数组中对应的比特位,如果所有的比特位都是1,认为在集合中。
优点:不需要存储key,节省空间
缺点:
1. 算法判断key在集合中时,有一定的概率key其实不在集合中2. 无法删除
典型的应用场景:某些存储系统的设计中,会存在空查询缺陷:当查询一个不存在的key时,需要访问慢设备,导致效率低下。
比如一个前端页面的缓存系统,可能这样设计:先查询某个页面在本地是否存在,如果存在就直接返回,如果不存在,就从后端获取。但是当频繁从缓存系统查询一个页面时,缓存系统将会频繁请求后端,把压力导入后端。

(Bloom Filter)是由布隆(Burton Howard Bloom)在1970年提出的。它实际上是由一个很长的二进制向量和一系列随机映射函数组成,布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率(假正例False positives,即Bloom Filter报告某一元素存在于某集合中,但是实际上该元素并不在集合中)和删除困难,但是没有识别错误的情形(即假反例False negatives,如果某个元素确实没有在该集合中,那么Bloom Filter 是不会报告该元素存在于集合中的,所以不会漏报)。
哈希表通过一个一个Hash函数将一个元素映射成一个位阵列(Bit Array)中的一个点。这样一来,我们只要看看这个点是不是 1 就知道可以集合中有没有它了。这就是布隆过滤器的基本思想。Hash面临的问题就是冲突。假设 Hash 函数是良好的,如果我们的位阵列长度为 m 个点,那么如果我们想将冲突率降低到例如 1%, 这个散列表就只能容纳 m/100 个元素。显然这就不叫空间有效了(Space-efficient)。解决方法也简单,就是使用多个 Hash,如果它们有一个说元素不在集合中,那肯定就不在。如果它们都说在,虽然也有一定可能性它们在说谎,不过直觉上判断这种事情的概率是比较低的。
优点
相比于其它的数据结构,布隆过滤器在空间和时间方面都有巨大的优势。布隆过滤器存储空间和插入/查询时间都是常数。另外, Hash 函数相互之间没有关系,方便由硬件并行实现。布隆过滤器不需要存储元素本身,在某些对保密要求非常严格的场合有优势。
布隆过滤器可以表示全集,其它任何数据结构都不能;
k 和 m 相同,使用同一组 Hash 函数的两个布隆过滤器的交并差运算可以使用位操作进行。
缺点
但是布隆过滤器的缺点和优点一样明显。误算率(False Positive)是其中之一。随着存入的元素数量增加,误算率随之增加。但是如果元素数量太少,则使用散列表足矣。
另外,一般情况下不能从布隆过滤器中删除元素. 我们很容易想到把位列阵变成整数数组,每插入一个元素相应的计数器加1, 这样删除元素时将计数器减掉就可以了。然而要保证安全的删除元素并非如此简单。首先我们必须保证删除的元素的确在布隆过滤器里面. 这一点单凭这个过滤器是无法保证的。另外计数器回绕也会造成问题。
False positives 概率推导
假设 Hash 函数以等概率条件选择并设置 Bit Array 中的某一位,m 是该位数组的大小,k 是 Hash 函数的个数,那么位数组中某一特定的位在进行元素插入时的 Hash 操作中没有被置位的概率是:

那么在所有 k 次 Hash 操作后该位都没有被置 "1" 的概率是:

如果我们插入了 n 个元素,那么某一位仍然为 "0" 的概率是:

因而该位为 "1"的概率是:

现在检测某一元素是否在该集合中。标明某个元素是否在集合中所需的 k 个位置都按照如上的方法设置为 "1",但是该方法可能会使算法错误的认为某一原本不在集合中的元素却被检测为在该集合中(False Positives),该概率由以下公式确定:

其实上述结果是在假定由每个 Hash 计算出需要设置的位(bit) 的位置是相互独立为前提计算出来的,不难看出,随着 m (位数组大小)的增加,假正例(False Positives)的概率会下降,同时随着插入元素个数 n 的增加,False Positives的概率又会上升,对于给定的m,n,如何选择Hash函数个数 k 由以下公式确定:

此时False Positives的概率为:

而对于给定的False Positives概率 p,如何选择最优的位数组大小 m 呢,

上式表明,位数组的大小最好与插入元素的个数成线性关系,对于给定的 m,n,k,假正例概率最大为:

Mitzenmacher and Upfal证明无假设情况下的误判率的期望值相同。
最优的哈希函数个数
既然布隆过滤器将集合映射到位数组中,那么选多少个hash函数才是错误率最低的情况。这里有两个互斥的理由:如果哈希函数的个数多,那么在对一个不属于集合的元素进行查询时得到0的概率就大;但另一方面,如果哈希函数的个数少,那么位数组中的0就多。为了得到最优的哈希函数个数,我们需要根据上一小节中的错误率公式进行计算。
误判率
两边取自然对数,
,只要g取最小值,p就能取到最小值。由于p=e^(-nk/m),我们可以将g改写为
根据对称法则可以得到当p=1/2时,也就是k=ln2*(m/n)时,g取得最小值,在这种情况下,最小的错误率p=(1/2)^k≈(0.6185)^(m/n)。p=1/2对应着位数组中0和1各半。换句话说,想保持错误率低,最好让位数组有一半还空着。
位数组的大小
在给定n(集合中元素的个数)和错误率(最优函数个数k的的错误率)的情况下,位数组M的大小计算,在最优k的情况下
化简为
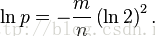
得到
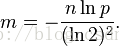
这意味着在错误率为p的情况下,布隆过滤器的长度为m才能容纳n个元素(以上计算基于n,m->∞)。
布隆过滤器中元素个数的估算
Swamidass & Baldi (2007)给出了布隆过滤器元素个数估算的方法(详细证明方式参考论文)
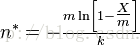
其中,n*表示布隆过滤元素个数的估算值,m表示布隆过滤器的大小,k表示哈希函数的个数,X表示布隆过滤器位值位1的个数。
布隆过滤器的并和交
布隆过滤器可以用来估算两个集合之间的并合交。一下给出两个集合之间并的计算方式:
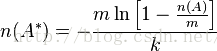
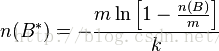
A和B之间的并集的个数为:
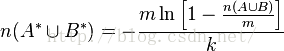
所以A*与B*之间的交集的个数为:
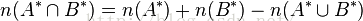
布隆过滤的特性
布隆过滤器能够容纳任意多的元素(误判率会增加),总是能向布隆过滤器中添加元素,不会报错(OutMemory等);
布隆过滤器可以很方便的通过计算机的or \and操作计算两个集合元素之间的交集(intersection)和并集(union),但是同样影响布隆过滤的准确性。















 5682
5682

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









