






一、背景
语音交友直播间 Web 端使用 WebRTC (Web Real-Time Communications) 实现多路音频流传输的播放。但由于云服务等原因,看播端我们需要改成 HTTP-FLV 或 HLS 协议的媒体服务。并实现
移动端页面多路音频流同时播放
获取多路音频的可视化数据
实现以上 2 个需求在 PC 端不是难点,有成熟的技术方案。最简单的多个 <video> 标签 + HLS 即可实现。但在移动端,特别是 iOS 有较大的限制。
二、调研
iOS、移动版 Safari 音频的限制
移动版 Safari 带来的最大的局限之一是一次只能播放一个单音频流。移动版 Safari 中的 HTML5 媒体元素都是单例的,所以一次只能播放一个 HTML5 音频(和 HTML5 视频)流。iOS 为移动版 Safari 提供了单一 HTML5 媒体(音频和视频)容器。如果想要在播放一个音频流的同时播放另一个音频流,那么就会从容器中删除前一个音频流,新的音频流将会在前一个音频流的位置上被实例化。
flv.js 和 hls.js
flv.js 和 hls.js 是开源的 2 款 JavaScript 类库。分别支持在浏览器播放 HTTP-FLV 和 HLS 协议的媒体服务。基于 Media Source Extensions API(MSE)实现。

Web Audio API
Web Audio API 提供了在 Web 上控制音频的一个非常有效通用的系统,允许开发者来自选音频源,对音频添加特效,使音频可视化,添加空间效果 (如平移)。所以我们使用 Web Audio API 开发个播放器。
三、实践
流程:
对音频流解封装
提取音频数据并 decode
合并多路音频数据并播放
获取音频的可视化数据
数据流程图

以下只介绍 HTTP-FLV (编码为 H.264 + AAC) 的直播流播放器研发。
解析音频前,需要知道的知识点
数字音频
计算机以数字方式将音频信息存储成一系列零和一。在数字存储中,原始波形被分成各个称为采样的快照。此过程通常称为数字化或采样音频,但有时称为模数转换。
数字化音频质量可以用三个基本参数来衡量,即采样率(sample rate)、采样位数(采样精度)和通道数(channel)。
采样率
采样率表示音频信号每秒的数字快照数。该速率决定了音频文件的频率范围。采样率越高,数字波形的形状越接近原始模拟波形。低采样率会限制可录制的频率范围,这可导致录音表现原始声音的效果不佳。

A. 使原始声波扭曲的低采样率。B. 完全重现原始声波的高采样率。
为了重现给定频率,采样率必须至少是该频率的两倍。例如,CD 的采样率为每秒 44,100 个采样,因此可重现最高为 22,050 Hz 的频率,此频率刚好超过人类的听力极限 20,000 Hz。
以下是数字音频最常用的采样率: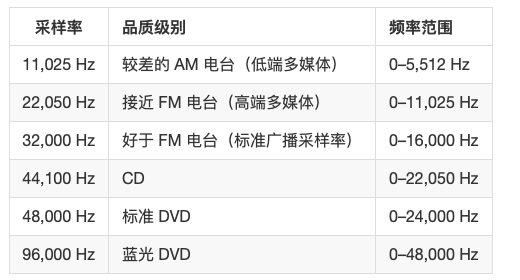
采样位数
采样位数决定动态范围。采样声波时,为每个采样指定最接近原始声波振幅的振幅值。较高的采样位数可提供更多可能的振幅值,产生更大的动态范围、更低的噪声基准和更高的保真度。


采样位数越高,提供的动态范围越大。
通道数(channel)
分为单声道 mono;立体声 stereo。当然还存在更多的通道数。举个列子,声道多,效果好,两个声道,说明只有左右两边有声音传过来, 四声道,说明前后左右都有声音传过来
不经过压缩,声音数据量的计算公式为:
数据量(字节/秒)=(
采样频率(Hz)× 采样位数(bit)× 通道数)/ 8
获取 arrayBuffer
通过 fetch 流式 IO 去拉取数据。Fetch API 通过 Response 的属性 body 提供了一个具体的 ReadableStream 对象。
fetch(url).then(response => {
const reader = response.body.getReader();
reader.read().then(function process(result) {
if (result.done) return;
// ...
return reader.read().then(process);
}).then(() => {
console.log('done!');当数据被全部读完前,每次我们只获取一个 chunk,这个 chunk 是无法直接播放音频的。所以我们需要进一步对每个 chunk 解封装。提取音频数据。
解封装(demux)
FLV 包括文件头(File Header)和文件体(File Body)两部分,其中文件体由一系列的 Tag 组成。这里只介绍 AAC 编码的 Tag 格式。

FLV header

FLV Body

FLV Tag Header
 Timestamp 和 TimestampExtended 组成了这个 TAG 包数据的 PTS 信息。
Timestamp 和 TimestampExtended 组成了这个 TAG 包数据的 PTS 信息。
PTS = Timestamp | TimestampExtended << 24。
FLV Tag body(Audio Header)

FLV Tag body(AAC Audio data)

FLV Tag body(Audio Specific Config)

到这,已经看到了我们要的音频数据。在 FLV 的文件中,一般情况下 AAC sequence header 这种包只出现 1 次,而且是第一个 audio tag。Decode AAC 音频,需要在每帧 AAC ES 流前边添加 7 个字节 ADST (Audio Data Transport Stream) 头,ADST 是解码器通用的格式,也就是说 AAC 的纯 ES 流要打包成 ADST 格式的 AAC 文件。打包 ADST 的时候,需要 samplingFrequencyIndex ,samplingFrequencyIndex 在 AudioSpecificConfig 中。这样,我们就把 FLV 文件中的音频信息及数据获取出来。
Elementary Streams(ES)是直接从编码器出来的数据流,可以是编码过的视频数据流(H.264, MJPEG 等),音频数据流(AAC),或其他编码数据流的统称。
打包 ADST,我们需要了解下 ADST Header。
ADTS Sequence(AAC)


一般情况下 ADTS 的头信息都是 7 个字节,分为 2 部分:
adtsfixedheader();


adtsvariableheader();


通过对 ADTS 格式的了解,我们很容易就能把 AAC 打包成 ADTS。只需得到封装格式里面关于音频采样率、声道数、元数据长度、AAC 格式类型等信息。然后在每个 AAC 原始流前面加上个 ADTS 头。
ADTS 的头信息有 7 个字节,都可以从 AudioSpecificConfig 中获取
const packet = new Uint8Array(7);
packet[0] = 0xff
packet[1] = 0xf0
packet[1] |= (0 << 3)
packet[1] |= (0 << 1)
packet[1] |= 1
packet[2] = (audioObjectType - 1) << 6
packet[2] |= (samplingFrequencyIndex & 0x0f) << 2
packet[2] |= (0 << 1)
packet[2] |= (channelConfiguration & 0x04) >> 2
packet[3] = (channelConfiguration & 0x03) << 6
packet[3] |= (0 << 5)
packet[3] |= (0 << 4)
packet[3] |= (0 << 3)
packet[3] |= (0 << 2)
packet[3] |= (packetLen & 0x1800) >> 11
packet[4] = (packetLen & 0x7f8) >> 3
packet[5] = (packetLen & 0x7) << 5
packet[5] |= 0x1f
packet[6] = 0xfc生成 ADTS + ES 的数据后。我们就可以对 AAC 数据进行解码生成 AudioBuffer
AudioContext
AudioContext 接口表示由音频模块连接而成的音频处理图,每个模块对应一个 AudioNode。
AudioContext 可以控制它所包含的节点的创建,以及音频处理、解码操作的执行。做任何事情之前都要先创建 AudioContext 对象,因为一切都发生在这个环境之中。
AudioContext.createBufferSource() 创建一个 AudioBufferSourceNode 对象, 他可以通 AudioBuffer 对象来播放和处理包含在内的音频数据。
AudioContext.createChannelMerger()方法,会创建一个 ChannelMergerNode,后者可以把多个音频流的通道整合到一个音频流。
AudioBuffer 可以用 AudioContext 接口的 decodeAudioData() 方法解码 AAC 数据( ADTS + ES) 获得。
ctx.decodeAudioData(ADTS.buffer).then(process);
const audioBufferSourceNode = ctx.createBufferSource();
const merger = ctx.createChannelMerger(2);
audioBufferSourceNode.buffer = buffer;
audioBufferSourceNode.connect(merger)merger.connect(ctx.destination)audioBufferSourceNode.start(this.startTime);
音频可视化

时域(time domain)是描述数学函数或物理信号对时间的关系。体现的是一段音频的音量变化,它的 X 轴单位是时间。
频域(frequency domain)是指在对函数或信号进行分析时,分析其和频率有关部分,而不是和时间有关的部分。体现的是在某一固定时刻各个频率的音量高低,它的 X 轴单位是频率。
让音频信号以图像的方式绘制,最基本的就是响应整个信号的音量和幅度。可以根据这些特征制作一个基本的动画。如果想要为低音和高音创建不同的动画,或者使用自定义频率范围来设置绘图的不同部分。可以利用 Fast Fourier Transform (快速傅里叶变换)。
FFT 可以分析波形并提供有关其不同频率的数据。因此,在音频轨道上运行 FFT 分析后,可以获得完整频谱和每个频率范围幅度的详细报告。虽然涉及 FFT,但利用 AnalyserNode可以简单实现。
AnalyserNode
AnalyserNode 赋予了节点可以提供实时频率及时间域分析的信息。它使一个 AudioNode 通过音频流不做修改的从输入到输出, 但允许你获取生成的数据, 处理它并创建音频可视化.
AnalyzerNode 只有一个输入和输出. 即使未连接输出它也会工作.

需要用到它的几个属性和方法
AnalyserNode.fftSize
一个无符号长整型的值, 表示(信号)样本的窗口大小。当执行快速傅里叶变换时,这些(信号)样本被用来获取频域数据。fftSize 属性的值必须是从 32 到 32768 范围内的 2 的非零幂; 其默认值为 2048.
frequencyBinCount
固定为AnalyserNode接口中ffSize值的一半。该属性通常用于可视化的数据值的数量。
getByteFrequencyData
将当前频率数据复制到传入的 Uint8Array(无符号字节数组)中。
音频可视化实现
const analyser = ctx.createAnalyser();
analyser.fftSize = const bufferLengthAlt = analyser.frequencyBinCount;
const dataArrayAlt = new Uint8Array(bufferLengthAlt);
analyser.getByteFrequencyData(dataArrayAlt);获取到的频谱数据数组 audioArray,我们只需要按照一定规则把数组数据绘制在 canvas 上。然后利用 requestAnimationFrame 进行循环绘制。

四、优化
Javascript 是单线程的,页面中的 Javascript 有大量计算的话,很容易阻塞页面的动画或者交互响应。HTML5 中的 Web Worker 就使 Javascript 的多线程编程成为可能。所以我们判断环境是否支持 web worker, 然后使用开启 worker。buffer 的下载和 demux 都是在 worker 中完成。三个线程之间通过 postMessage 通信,在传送流数据时使用 Transferable 对象,只传递引用,而非拷贝数据,提高性能。
五、参考
1. wikipedia
https://en.wikipedia.org
2.Adobe Flash Video File Format Specification Version10.1
http://download.macromedia.com/f4v/video_file_format_spec_v10_1.pdf
3.Digitizingaudio
https://helpx.adobe.com/audition/using/digitizing-audio.html
4. ISO-14496-15 AVC file format
5. ISO/IEC 14496-3
6.WebAudioAPI
https://developer.mozilla.org/en-US/docs/Web/API/Web_Audio_API
















 227
227











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









