







HashMap存储的数据存放在内存中,提高HashMap数据寻址速度是重点要解决的问题,所以HashMap底层的存储结构非常关键,如果使用数组存储,时间复杂度为O(1),使用链表存储,时间复杂度为O(n),如果使用二叉树存储,时间复杂度为O(lg(n))。所以HashMap优先使用数组存储,如果出现hash碰撞,采用链表存储,如果链表长度大于8,寻址速度明显下降,进一步采用红黑树存储,将寻址效率提高。
如果下图为HashMap存储
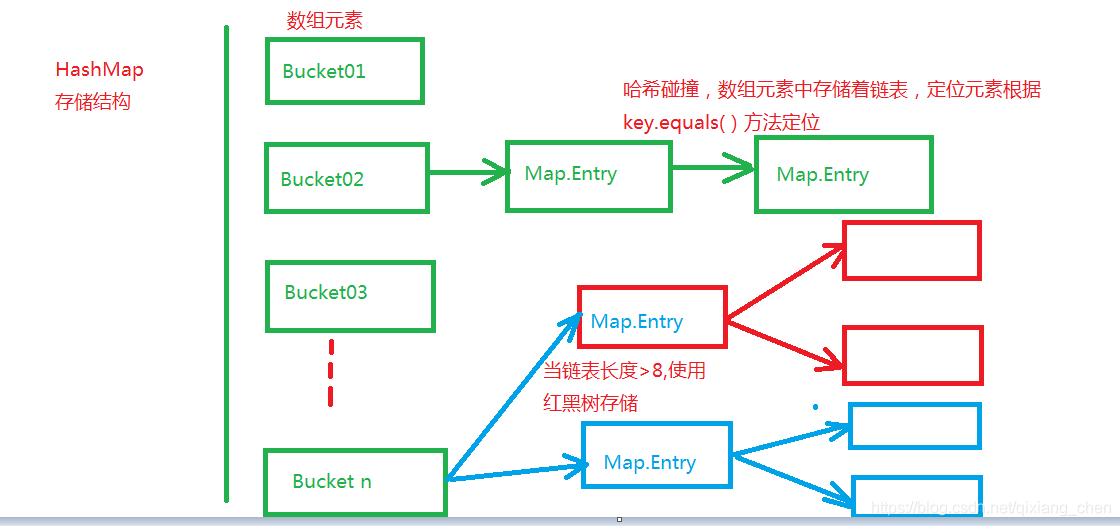
元素分配Hash桶
向HashMap中put(key,value)数据时,首先计算Key的哈希值,将Hash值%16计算出Hash桶序号n(0-16之间),将元素存放在n号hash桶,存放的数据时Map.Entry包括Key值和Value值
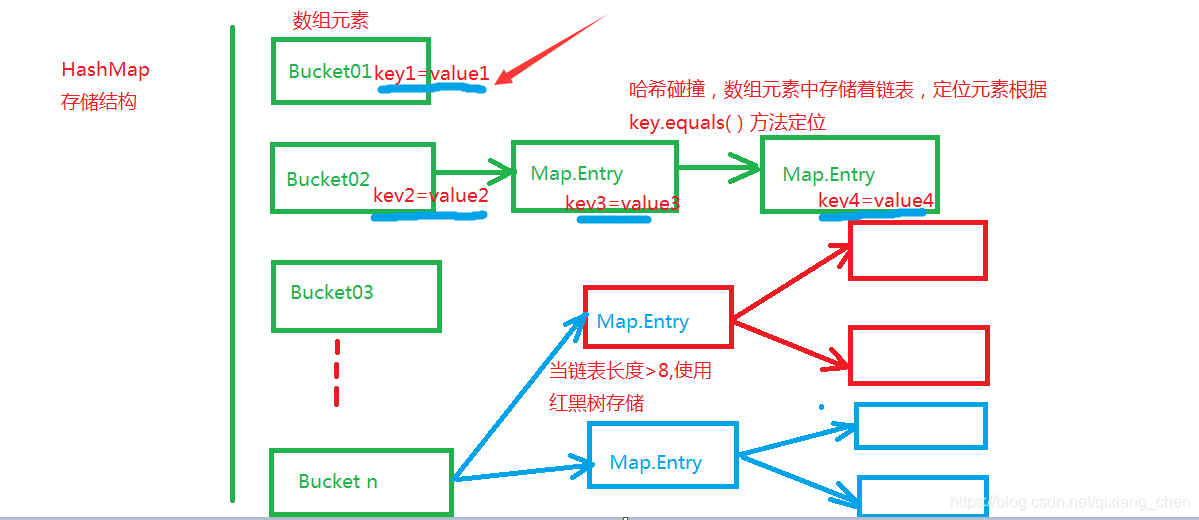
当存放两个元素获取Hash并且Mod 16得到Hash桶编号相同时,出现Hash碰撞,hash桶使用链表存储这两个对象,使用HashMap.get(key)获取这两个对象时,需要两步实现,首先得到它们对应的Hash桶号,在根据Key与链表中的Key1=Value1比较key.equale(key1),找出对应元素,这样需要递归遍历列表中的元素,执行效率降低。
当链表长度大于8时,HashMap将链表存储转化为红黑树存储,红黑树遍历每次可以减少一个分支,效率比链表高,其时间复杂度为O(lg(n))。
HashMap扩容
HashMap使用数组存储,默认长度为16,加载因子为0.75,当HashMap的Hash桶数量的75%被分配使用时,HashMap扩容为原来的两倍。扩容时原来数组地址放弃,重新分配地址空间,并将原来对应的数据复制过来。此过程为rehashing,JDK1.7在多线程环境下HashMap扩容可以导致无限循环,因为扩容过程中会新数组会和原来的数组有指针引用关系。在JDK1.8中在多线程环境下HashMap扩容可以导致数据丢失。
Key类型选定
存放到HashMap中的Key的类型,最好选择HashCode方法返回hashcode固定值,防止hashcode变化,比如String类型重写了HashCode方法,只要字符串不变化,hashCode值唯一。














 2445
2445











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









