






目录
向量数据库简介
向量数据库是一种专门设计用于存储、管理和检索高维向量数据的数据库系统。其核心功能在于通过数学空间中的向量表示非结构化数据(如文本、图像、音频、视频),并基于相似性度量实现高效检索。与传统关系型数据库依赖精确匹配或固定字段查询不同,向量数据库利用嵌入技术将数据转化为高维向量,从而捕捉语义或上下文关联性。
这类数据库的核心技术包括近似最近邻(ANN)搜索算法,如IVFFlat、HNSW等,能够在海量数据中快速定位与查询向量最接近的结果。其应用场景涵盖图像识别、推荐系统、自然语言处理以及生成式人工智能(如检索增强生成RAG),通过连接嵌入模型与大语言模型,提升AI应用的准确性和响应速度。
从技术架构来看,向量数据库支持多种索引方式,具备分布式处理能力,可扩展至PB级数据规模。其优势体现在三个方面:一是高效处理非结构化数据,通过向量化实现复杂特征的数学表达;二是支持低延迟的语义相似性搜索,突破传统关键字匹配的局限;三是优化AI模型性能,例如在对话系统中管理长期记忆,或为模型提供领域知识库。随着人工智能技术的普及,向量数据库已成为构建智能应用的关键基础设施。
主流向量数据库
以下为部分当前主流向量数据库及其技术特点与适用场景:
| 向量数据库 | 技术特点 | 适用场景 |
| Milvus | 支持分布式架构与PB级数据扩展,提供IVFFlat、HNSW等多种索引算法,具备动态数据更新和实时检索能力。通过近似最近邻(ANN)搜索优化,平衡精度与查询效率。 | 适用于大规模AI应用场景,如推荐系统、多模态检索(图像/视频/文本)、RAG(检索增强生成)技术中的知识库增强,以及需要低延迟高并发的实时分析场景。 |
| FAISS | 由Meta开源的轻量级向量检索库,支持CPU/GPU加速,提供基于聚类的索引和量化压缩技术,内存占用低但需手动管理数据持久化。 | 适合作为嵌入式组件集成至现有系统,如中小规模图像相似性搜索、学术研究中的快速原型验证,或需要定制化索引策略的场景。 |
| 扩展型数据库 (如Elasticsearch、PostgreSQL pgvector) | 在传统数据库基础上扩展向量检索功能,兼容结构化与非结构化数据的混合查询。例如,Elasticsearch的dense_vector字段支持结合关键词与向量相似性检索。 | 适用于已使用成熟数据库体系的企业,需在业务系统中逐步引入向量能力,如电商平台的商品多维度推荐、日志分析中异常模式检测等。 |
| 云原生向量数据库(如Pinecone、Zilliz Cloud) | 全托管服务,提供自动扩缩容、多租户隔离和预训练模型集成,降低运维复杂度。支持Serverless架构按需计费。 | 适合资源有限的中小型企业快速部署生成式AI应用,如智能客服的语义匹配、私有化知识库的构建与维护。 |
除上述之外,还有一个易用性和新手友好性较高的——Chroma 向量数据库。
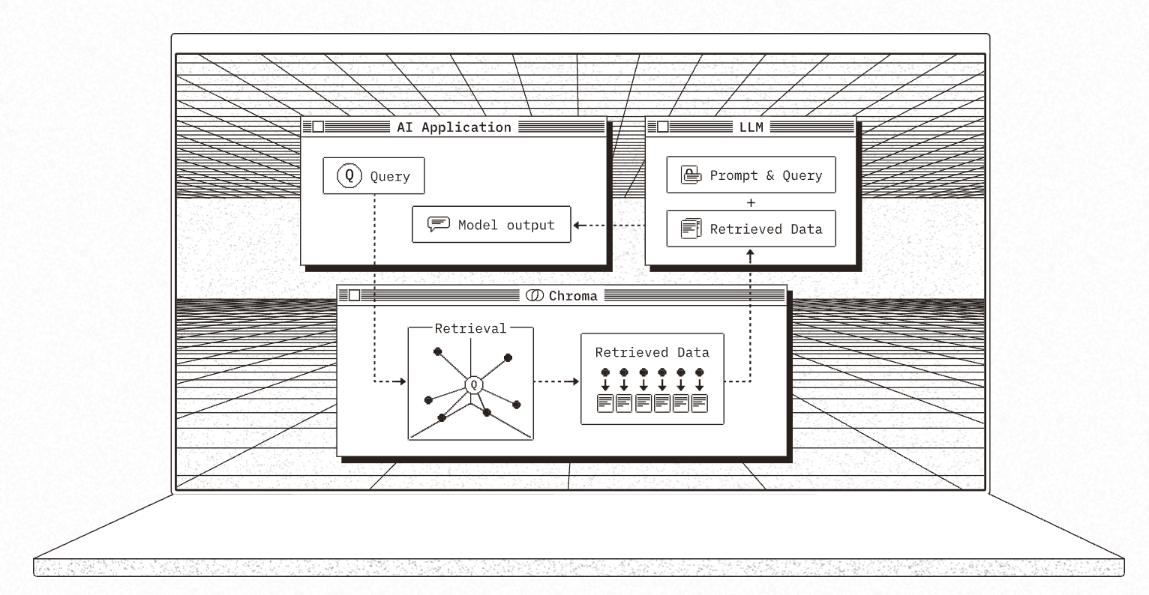
Chroma作为轻量级向量数据库,其核心优势在于快速部署和极简的API设计,开发者仅需数行代码即可完成安装和基础向量操作,无需依赖分布式架构或复杂配置。其内置的本地存储模式和Python原生集成特性,尤其适合中小规模数据场景的快速原型验证。
本项目的向量数据库选型采用 Chroma ,现在我们就来尝试构建一个 Chroma 向量数据库。
Chroma 向量数据库构建与使用
首先在python终端下载安装 chromadb :
pip install chromadb然后我们需要确定向量数据库中将要存储的文本段落,我们把之前进行文档加载与分割的代码部分(详见创新实训第(三)篇)封装成一个chunking函数,将文件路径作为参数,这样可以对传入的文件路径下的文件进行分块,最终返回分块段落即可。
现在我们就可以调用该chunking函数,传入想要分块的文档路径,将分块后的文档作为将要存储进向量数据库的文本段落记录下来:
paragraphs = chunking("../../WitSpider/数据集/OrChiD.json")然后我们导入chromadb,大概需要导入以下两行:
import chromadb
from chromadb.config import Settings接下来创建一个向量数据库连接对象 Connector 类:
class VectorDBConnector:
def __init__(self, connection_name, embedding_function):
'''初始化方法'''
# 持久化存储
chroma_client = chromadb.PersistentClient(path="./chroma") # path的值即存储路径的值可以自行指定
# 创建一个collection
self.collection = chroma_client.get_or_create_collection(name=connection_name)
self.embedding_function = embedding_function
def addDE(self, doc):
'''添加原始文档与对应的向量'''
self.collection.add(
embeddings=self.embedding_function(doc), # 文档对应的向量(使用自己绑定的向量模型,不设置也可,Chroma有内置向量模型)
documents=doc, # 原始文档
ids=[f"id{i}" for i in range(len(doc))] # 文档索引id
)
def search(self, query, top_n): # query为查询问题/内容,top_n为查询返回最相似的段落个数
'''检索方法'''
results = self.collection.query(
query_embeddings=self.embedding_function(query), # 问题文本向量化
n_results=top_n # 返回个数
)
return results接下来我们创建一个向量数据库对象,并向其中添加文档,可以通过一个简单的query进行search检索测试并将结果分段落打印输出,查看检索答案是否与问题相似,代码如下:
# 创建向量数据库对象,名字为test,向量化函数为之前写好的m3e-base模型的向量化函数
vectorDB = VectorDBConnector("test", get_embedding)
# 添加刚刚已经分块完毕的 paragraphs 文档
vectorDB.addDE(paragraphs)
test_query = "爱需要克制吗"
results = vectorDB.search(test_query, 2)
for para in results['documents'][0]:
print(para+"\n")常见报错汇总
尝试运行,报了很多错,在此做一个总结:
huggingface_hub.errors.HFValidationError: Repo id must use alphanumeric chars or '-', '_', '.', '--' and '..' are forbidden, '-' and '.' cannot start or end the name, max length is 96: '../m3e-base'.
这个错误是由于传递给Hugging Face模型的路径不符合仓库ID命名规范导致的。我使用了相对路径“../m3e-base”作为模型路径,而Hugging Face的仓库ID命名规则要求为:
- 只能包含字母数字、-、_、.
- 不能以.或-开头/结尾
- 最大长度96字符
- 不能包含..这样的上级目录符号
因此将该相对路径改为绝对路径即可。
ValueError: expected sequence of length 292 at dim 1 (got 235)
ValueError: Unable to create tensor, you should probably activate truncation and/or padding with 'padding=True' 'truncation=True' to have batched tensors with the same length. Perhaps your features (`input_ids` in this case) have excessive nesting (inputs type `list` where type `int` is expected).
这个错误是由于输入的文本块长度不一致(之前定义的文本分割函数是根据标点符号进行文本分割,每个句子长短不一),在将不同长度的文本转换为张量时出现维度不匹配的情况,最终导致张量创建失败。
因此,我们在处理多个不同长度的文本时,可以启用填充(padding)和截断(truncation)来统一文本长度,解决方案代码如下:
# 修改前的代码示例
inputs = tokenizer(text, return_tensors="pt")
# 修改后的正确代码示例
inputs = tokenizer(
text,
padding=True, # 自动填充到最长序列
truncation=True, # 自动截断到模型最大长度
return_tensors="pt", # 返回PyTorch张量
max_length=512 # 显式设置最大长度(可选)
)通过以上调整,我们可以确保:
- 所有输入文本被规范到相同长度
- 长文本会被自动截断到模型支持的最大长度
- 短文本会被填充到批次最大长度
- 输出张量维度统一,便于后续模型处理
RuntimeError: [enforce fail at alloc_cpu.cpp:116] data. DefaultCPUAllocator: not enough memory: you tried to allocate 135648509952 bytes.
这个内存错误表明尝试分配的135GB内存超出了系统可用内存,这是处理大文本数据时常见的问题。这时我们就需要减小批处理量,采取分批处理方式,解决方案代码如下:
# 修改前的直接处理
embeddings = model(**inputs).last_hidden_state[:, 0]
# 修改后的分批处理
batch_size = 8 # 根据内存调整
embeddings = []
for i in range(0, len(inputs.input_ids), batch_size):
batch = {
"input_ids": inputs.input_ids[i:i+batch_size],
"attention_mask": inputs.attention_mask[i:i+batch_size]
}
with torch.no_grad():
outputs = model(**batch)
embeddings.append(outputs.last_hidden_state[:, 0])
embeddings = torch.cat(embeddings)如果程序运行之后一直没有任何反应,没有任何报错,也没有任何输出,可能是由于输入的文本块数量过多(之前在篇(三)中输出文本总分割块数为86243),因此我们只取前500块进行测试:
vectorDB.addDE(paragraphs[:500]) # 只加入paragraphs前500块ValueError: Expected embeddings to be a list of floats or ints, a list of lists, a numpy array, or a list of numpy arrays, got tensor([[ 1.6857, 0.9095, -0.0560, ..., -1.3708, -1.2209, -0.7678],
[ 1.3623, 1.0387, -0.1714, ..., -0.9567, -1.4641, -0.6724],
[ 1.1292, 0.6356, -0.4984, ..., -1.0800, -1.2410, -0.8665],
...,
[ 0.6906, 0.6040, 0.7937, ..., -1.1300, -0.4843, -0.6601],
[ 0.3712, 0.8886, 0.6301, ..., -0.5632, -0.2854, -0.3434],
[ 0.8227, 0.9933, 0.8821, ..., -1.2070, -0.3160, -0.4926]]) in add.
这个错误是因为在向ChromaDB添加数据时,提供的embeddings格式不正确。错误信息显示传递的是PyTorch的tensor对象,但ChromaDB要求embeddings必须是以下格式之一:
- 浮点数/整数的列表
- 列表的列表
- numpy数组
- numpy数组的列表
因此在将embeddings添加到ChromaDB之前,需要将PyTorch tensor转换为Python列表或numpy数组。以下是修改建议:
# 修改前的代码(假设)
embeddings = model(texts) # 这里返回PyTorch tensor
# 修改后的代码
embeddings = model(texts).detach().cpu().numpy().tolist() # 转换为Python列表
# 或
embeddings = model(texts).detach().cpu().numpy() # 转换为numpy数组
# 然后调用add方法
self.collection.add(
documents=documents,
embeddings=embeddings, # 现在格式正确了
ids=ids
)关键修改点:
- .detach():将tensor从计算图中分离(如果不需要梯度)
- .cpu():如果tensor在GPU上需要先转到CPU
- .numpy():转换为numpy数组
- .tolist()(可选):如果希望最终格式是Python列表
运行结果
解决了上述问题之后,现在再来运行,运行结果如下:

成功地检索到了两段与问题最相关的文本!

















 2823
2823

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









