







前言
本篇介绍笔者在获取毕设数据中通过爬虫手段获取电影网的海报以及电影简介进行
版权声明:本文所提及的相关技术仅仅供开发者学习交流使用,不涉及商业用途.
一、背景
毕设所需实现的电影推荐功能,涉及文本数据挖掘,图像识别,其中文本数据来源于电影介绍,图像识别对应电影海报;遂提出目标如下
- 选择合适的电影数据展示网站
- 获取电影海报
- 获取电影简介
二、数据获取
1.网址选取
这里选取某电影网站作为本次爬虫获取数据的目标网站,具体网址下方源码配置文件
2.查看网页结构

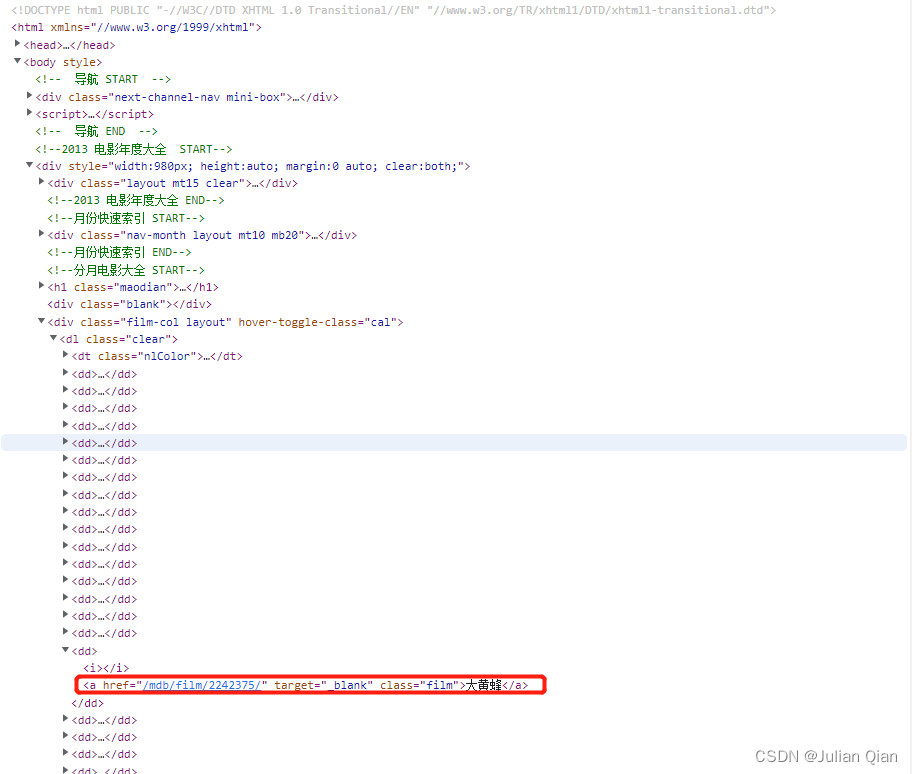
这里可以看到每一个电影选项就是一个链接,可以通过链接请求一个网页
点击链接进入相关网页,查看电影海报和电影简介
电影海报

电影简介
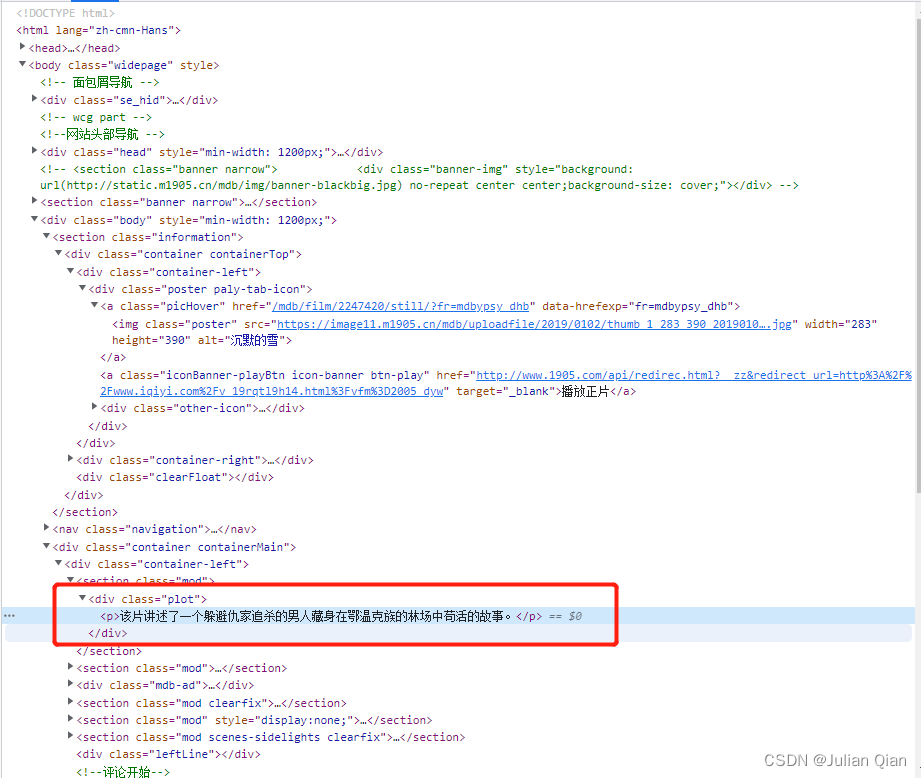
看到这里就比较明了,图片可以通过img对应的url直接请求下来,电影文字介绍可以通过获取整个网页的HTML文件,而后解析对应class的div得到里面的文字
3.代码实现
根据指定Url,获取网页文本内容
def getFilmHTMLText(url,code='utf-8'):
try:
#加上头部信息后可避免有时候抓取为空的情况
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'}
r=requests.get(url,timeout=30,headers=headers)
r.raise_for_status()
r.encoding=code
return r.text
except:
return ""
获取海报
def getThePicture(url,month,countInMonth,fileLoadPath,picText):
print(url)
#解析具体每个电影的页面获取其海报
#爬取完图片后睡眠5s
html=getFilmHTMLText(url)
soup=BeautifulSoup(html,'html.parser')
img=soup.find_all('img',{"class":"poster"})
print(picText)
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'}
r=requests.get(img[0].attrs['src'],timeout=30,headers=headers)
r.raise_for_status()
filePath=fileLoadPath+str(month)+'月\\'+str(picText)+'.jpg'
print(filePath)
with open(filePath,'wb') as f:
f.write(r.content)
except:
print("出现异常!")
time.sleep(5)
获取电影介绍文字
def getFileDescription(url,month,picText):
print(url)
# 解析具体每个电影的页面获取其海报
# 爬取完图片后睡眠5s
html = getFilmHTMLText(url)
soup = BeautifulSoup(html, 'html.parser')
div = soup.find_all('div', {"class": "plot"})
# print(div)
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'}
des=div[0].contents[1].text
# 将评论写入csv文件
writeToCsvFile(reptile_configuration.save_description_csv_path,picText,des)
except:
print("出现异常!")
time.sleep(5)
控制流程
def getTheFilm(filmURL):
html=getFilmHTMLText(filmURL)
soup=BeautifulSoup(html,'html.parser')
dl=soup.find_all('dl',{"class":"clear"})
count=1
for f in dl:
x=f.find_all('a',{"class":"film"})
print("月份" + str(count))
countInMounth=0
for pic in x:
#https://www.1905.com
#get the concrete film's url
print(type(pic))
# print(pic.text)
url="https://www.1905.com"+pic.attrs['href']
getFileDescription(url,count,pic.text)
countInMounth+=1
count+=1
print("下载数据完成!")
配置文件,主要存放你要存放海报的路径,和存放相关电影简介的路径
# 存储爬取电影的一些配置信息
China_movie_reptile_website= "https://www.1905.com/mdb/film/calendaryear/"
Douban_natural_movie_website= "https://search.douban.com/movie/subject_search?search_text=%E8%87%AA%E7%84%B6%E7%BA%AA%E5%BD%95%E7%89%87&cat=1002&start=0"
save_file_dir_path="D:\\2023\\Movie\\"
save_file_dir_path_2018="D:\\XXX\\2018\\"
save_description_csv_path="XXXX\\description.csv"
4.最终效果
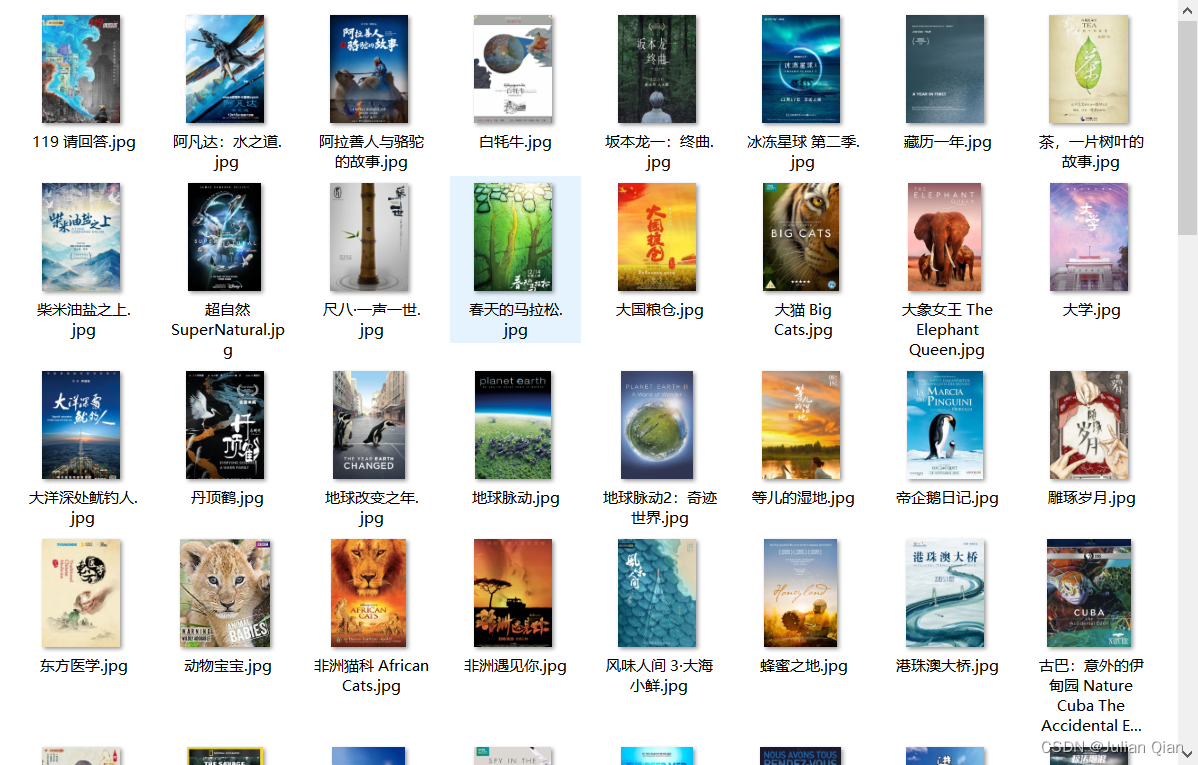
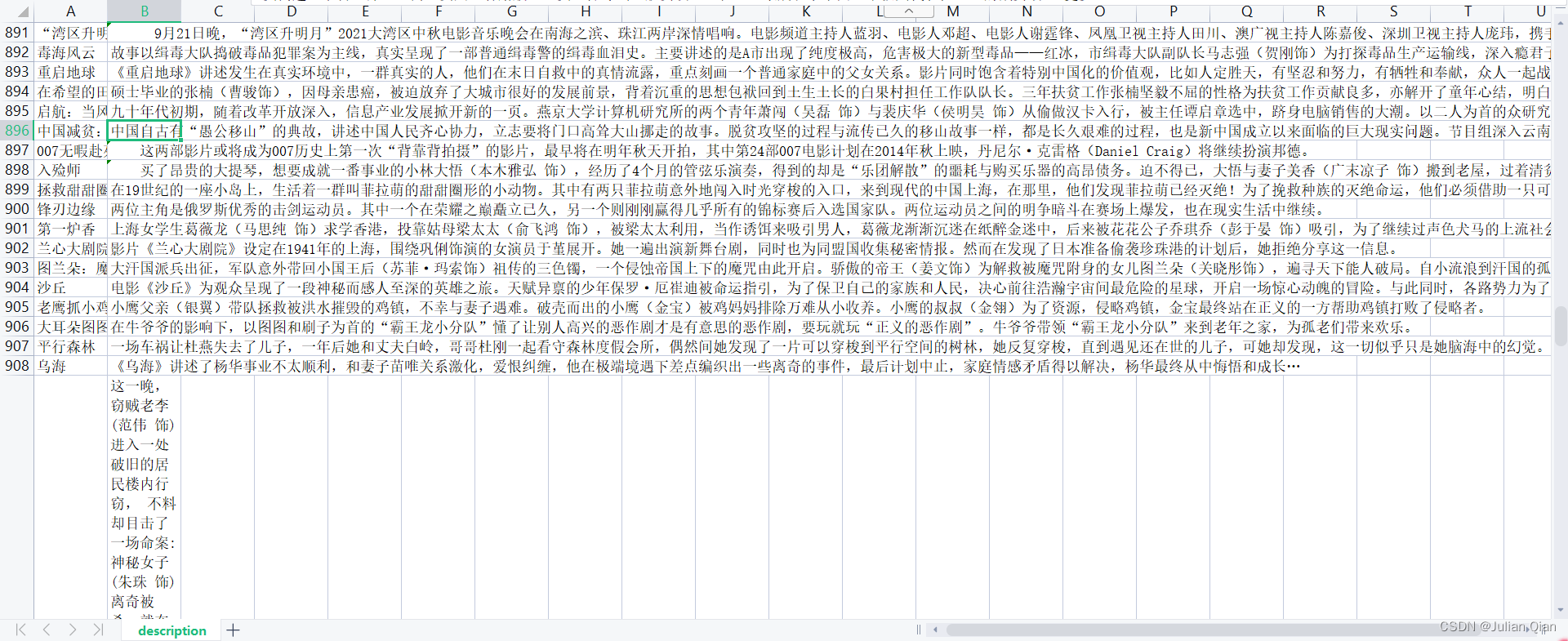
5.完整代码
如果能帮助到你的话,给个Star趴
需要注意的是,某网站网页代码为静态代码,这给爬取数据提供了很大的便利,针对动态生成的网页,需要采用另外的手段进行爬取,有相关资料的uu可以commit,感谢


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









