







Continuous weight balancing
文章信息
题目:Continuous weight balancing
发表:ICLR, 2021
作者:Daniel J. Wu, Avoy Datta
动机
当前的不平衡回归研究实际上都是在如下场景下进行:训练集中的样本的目标y的分布是不平衡的,而目标域/测试集中的数据分布是平衡的,所以研究的目的是:从不平衡的数据集中训练出一个unbiased model。
这篇文章实际上考虑了一种更加General的场景:即目标域的分布也是不平衡的,并且不平衡的含义更加广泛,可以是目标值也可以是数据集中的特征。
方法
方法非常的简单,大致分为4步, 如下图所示:
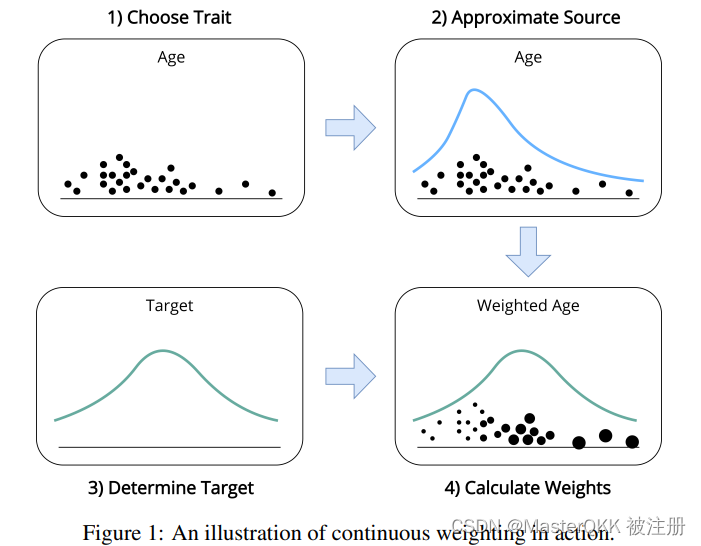
Step 1: 选择合适合适weight traint,
如何理解Weight trait, 它实际上是一个加权所要依据的一个连续变量,该变量可以是目标变量,也可以是特征变量。总之,特刻画了数据集中的一个特征,后续加权会基于该特性进行。
Step 2: 估计源域的分布
估计方法采用的和密度估计Kernel Density estimation (KDE), 这是一种非参数密度估计方法, 其定义如下:
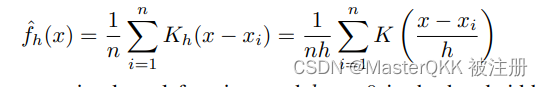
Step 3: 估计目标域的分布
估计方法与上一步类似,
Step 4: 估计权重
就是Step 3 和Step 2估计的密度的比值

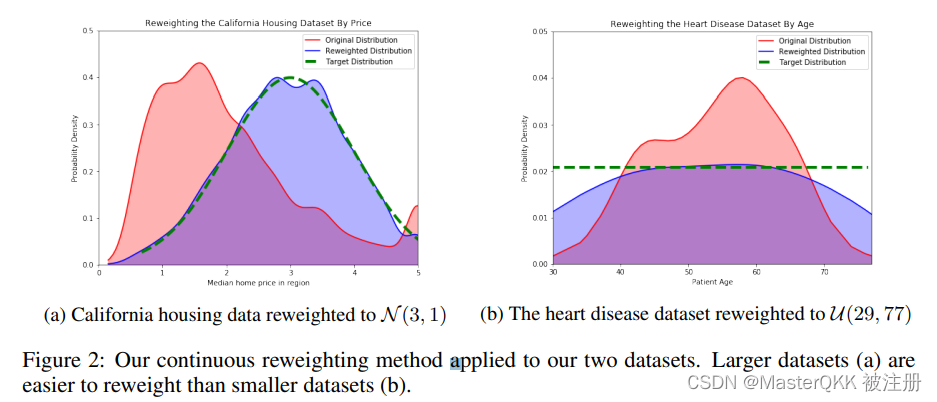
通过上述样本权重确定方法,可以把任意不平衡的数据集转换到与任意指定目标域数据集相匹配。
下图展示了两个采用上述办法把源域转换到目标域的Demo,
思考
1.太简单了,没有深度,论文中实验部分很少;
2.关开头于不平衡的分析那块感觉挺有意思,不平衡可以是目标,也可以是数据集中的某个特征,而当前的不平衡研究主要都是针对目标的不平衡。 但是这篇文章并没有带来新的东西,期待后续能有更加深入,迎合的研究工作。
References
1.Wu D J, Datta A. Continuous weight balancing[J]. arXiv preprint arXiv:2103.16591, 2021.















 2981
2981











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











