







学号:sa×××310 姓名:××涛
环境:Opensuse 12.2 gcc4.7.1
1.gdb常用调试命令
要用gdb调试的话,编译命令需要添加-g参数,例如
gcc -g main.c -o mainb linenum 在第 linenum行打断点
l 显示源代码;
Ctrl-d 退出gdb
where 显示当前程序运行位置
print /d $eax 十进制地方式打印$eax 值,/x是十六进制,/t是二进制
n 下一行
layout split 把当前Terminal分割成两半,上面显示源码及汇编,下面可以输入调试命令,效果如下:
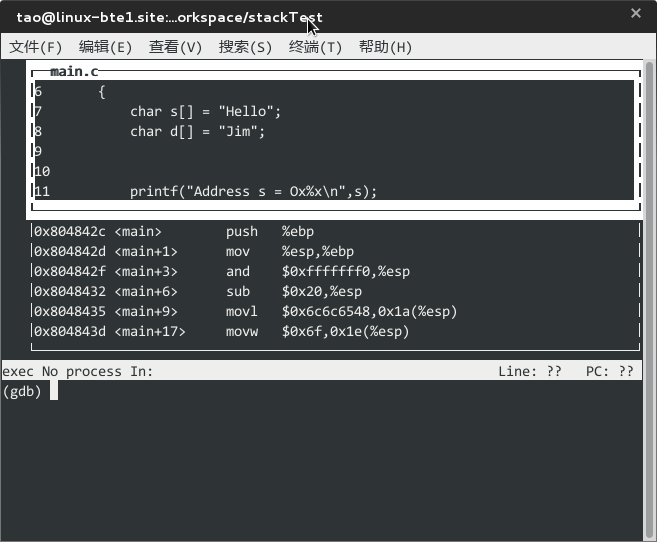
2.Example.c程序分析
程序代码:
#include <stdio.h>
int g(int x)
{
return x+3;
}
int f(int x)
{
return g(x);
}
int main(void)
{
printf("Hello\n");
return f(8)+1;
}将源代码编译为二进制文件又需要经过以下四个步骤:预处理(cpp) → 编译(gcc或g++) → 汇编(as) → 链接(ld) ;括号中表示每个阶段所使用的程序,它们分别属于 GCC 和 Binutils 软件包。
用gcc的编译参数和生成的对应文件。
2.1预编译
gcc -E Example.c -o Example.cpp生成的cpp文件内容如下:
...
...
...
//a lot of extern statement
extern char *ctermid (char *__s) __attribute__ ((__nothrow__ , __leaf__));
# 910 "/usr/include/stdio.h" 3 4
extern void flockfile (FILE *__stream) __attribute__ ((__nothrow__ , __leaf__));
extern int ftrylockfile (FILE *__stream) __attribute__ ((__nothrow__ , __leaf__)) ;
extern void funlockfile (FILE *__stream) __attribute__ ((__nothrow__ , __leaf__));
# 940 "/usr/include/stdio.h" 3 4
# 2 "Example.c" 2
int g(int x)
{
return x+3;
}
int f(int x)
{
return g(x);
}
int main(void)
{
return f(8)+1;
}
主要代码基本没有变化,添加了很多extern声明。
分析
预编译的主要作用如下:
●将源文件中以”include”格式包含的文件复制到编译的源文件中。
●用实际值替换用“#define”定义的字符串。
●根据“#if”后面的条件决定需要编译的代码。
在该阶段,编译器将C源代码中的包含的头文件stdio.h编译进来,生成扩展的c程序。当对一个源文件进行编译时, 系统将自动引用预处理程序对源程序中的预处理部分作处理, 处理完毕自动进入对源程序的编译。
2.2编译
执行编译的结果是得到汇编代码。
gcc -S Example.c -o Example.s生成.s文件内容如下:
.file "Example.c"
.text
.globl g
.type g, @function
g:
.LFB0:
.cfi_startproc
pushl %ebp ;ebp寄存器内容压栈
.cfi_def_cfa_offset 8
.cfi_offset 5, -8
movl %esp, %ebp ;esp值赋给ebp,设置函数的栈基址。
.cfi_def_cfa_register 5
movl 8(%ebp), %eax ;将ebp+8所指向内存的内容存至eax
addl $3, %eax ;将3与eax中的数值相加,结果存至eax中
popl %ebp ;ebp中的内容出栈
.cfi_restore 5
.cfi_def_cfa 4, 4
ret
.cfi_endproc
.LFE0:
.size g, .-g
.globl f
.type f, @function
f:
.LFB1:
.cfi_startproc
pushl %ebp ;ebp寄存器内容压栈
.cfi_def_cfa_offset 8
.cfi_offset 5, -8
movl %esp, %ebp ;esp值赋给ebp,设置函数的栈基址。
.cfi_def_cfa_register 5
subl $4, %esp ;esp下移动四个单位
movl 8(%ebp), %eax ;将ebp+8所指向内存的内容存至eax
movl %eax, (%esp) ;将eax存至esp所指内存中
call g ;调用g函数
leave ;将ebp值赋给esp,pop先前栈内的上级函数栈的基地址给ebp,恢复原栈基址
.cfi_restore 5
.cfi_def_cfa 4, 4
ret ;函数返回,回到上级调用
.cfi_endproc
.LFE1:
.size f, .-f
.globl main
.type main, @function
main:
.LFB2:
.cfi_startproc
pushl %ebp ;ebp寄存器内容压栈
.cfi_def_cfa_offset 8
.cfi_offset 5, -8
movl %esp, %ebp ;esp值赋给ebp,设置函数的栈基址。
.cfi_def_cfa_register 5
subl $4, %esp ;esp下移动四个单位
movl $8, (%esp) ;将8存入esp所指向的内存空间
call f ;调用f函数
addl $1, %eax ;将1与eax的内容相加
leave ;将ebp值赋给esp,pop先前栈内的上级函数栈的基地址给ebp,恢复原栈基址
.cfi_restore 5
.cfi_def_cfa 4, 4
ret ;函数返回,回到上级调用
.cfi_endproc
.LFE2:
.size main, .-main
.ident "GCC: (SUSE Linux) 4.7.1 20120723 [gcc-4_7-branch revision 189773]"
.section .comment.SUSE.OPTs,"MS",@progbits,1
.string "ospwg"
.section .note.GNU-stack,"",@progbits分析
第1行为gcc留下的文件信息;第2行标识下面一段是代码段,第3、4行表示这是g函数的入口,第5行为入口标号;6~20行为 g 函数体,稍后 分析;21行为 f 函数的代码段的大小;22、23行表示这是 f 函数的入口;24行为入口标识,25到41为 f 函数的汇编实现;42行为f函数的代码段的大小;43、44行表示这是main函数的入口;45行为入口标识,46到62为main函数的汇编实现;63行为main函数的代码段的大小;54到67行为 gcc留下的信息。
具体程序运行时内存的调用情况如下图:
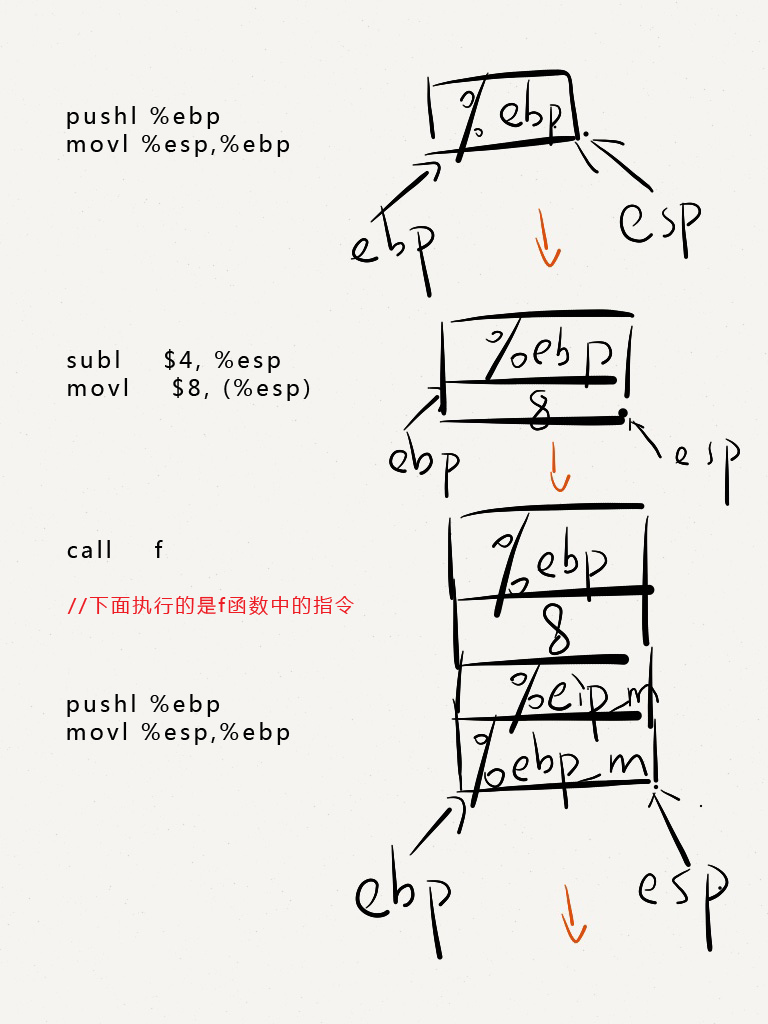
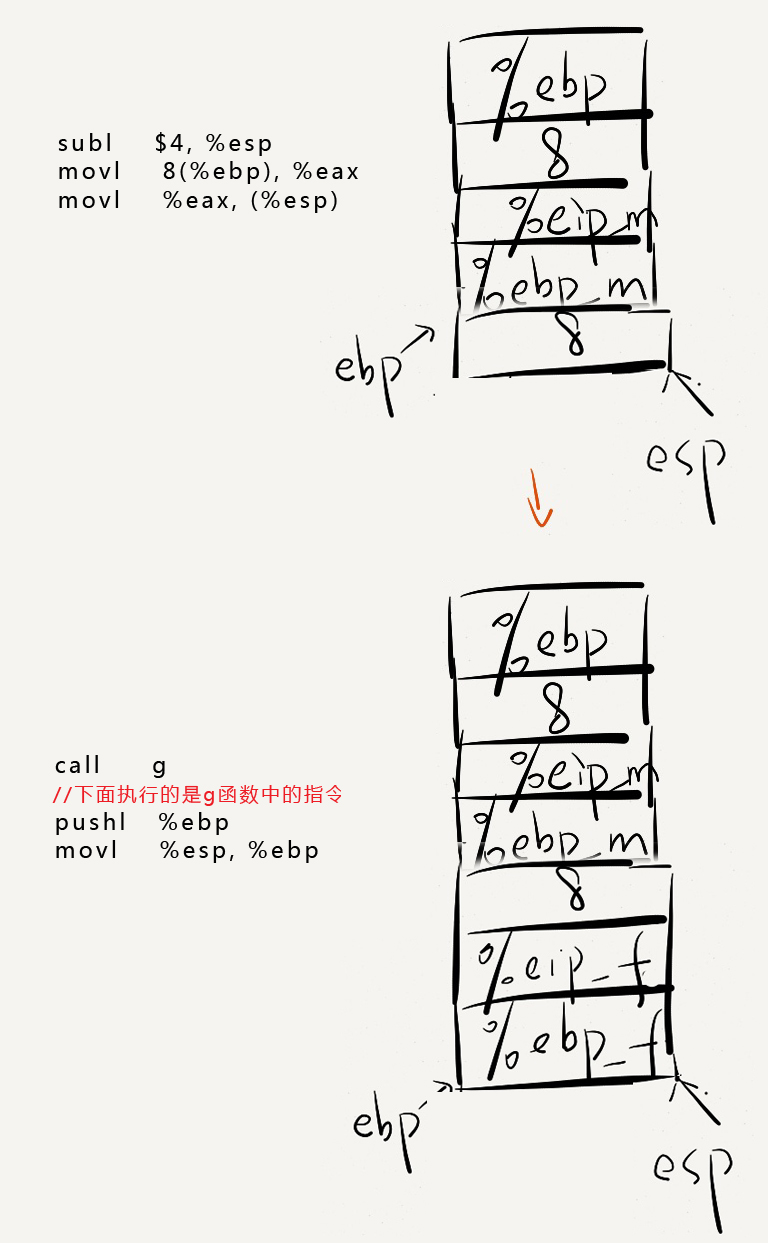
以.cfi开头的命令如.cfi_startproc,主要用于作用是出现异常时stack的回滚(unwind),而回滚的过程是一级级CFA往上回退,直到异常被catch。
这里不做讨论,需要详细了解的点这里。
每一个函数在开始都会调用到
pushl %ebp ;ebp寄存器内容压栈,即保存函数的上级调用函数的栈基地址
movl %esp,%ebp ;esp值赋给ebp,设置函数的栈基址主要作用是保存当前程序执行的状态。
还有两句在函数调用结束时也会出现:
leave ; 将ebp值赋给esp,pop先前栈内的上级函数栈的基地址给ebp,恢复原栈基址
ret ; 函数返回,回到上级调用 用于在函数执行完后回到执行前的状态。
还有要注意的是汇编中的push和pop
pop系列指令的格式是:
pop destination
pop指令把栈顶指定长度的数据存放到destination中,并且设置相应的esp的值使它始终指向栈顶位置。
push刚好相反。
pushl %eax 等价于
subl $4 %esp
movl %eax (%esp)
popl %eax 等价于
movl (%esp) %eax
addl %4 %esp
2.3汇编
汇编之后得到的是.o文件,终端执行命令:
as Example.s -o Example.o
在终端用vim打开:
vim -b Example.o用16进制进行查看,在vim中输入
:%!xxd结果如下(未完全显示)
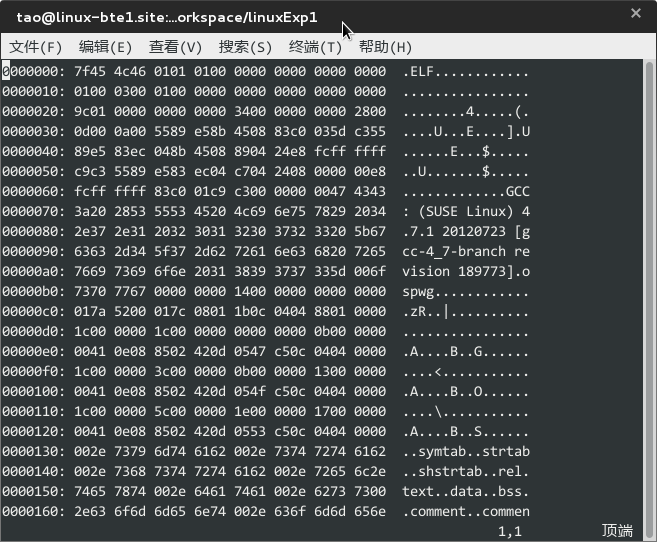
分析
目标文件就是源代码编译后但未进行链接的那些中间文件,包含有编译后的机器指令代码,还包括链接时所需要的一些信息,比如符号表、调试信息、字符串等。
可以查看目标文件的信息,在终端执行
file Example.o得到:
Example.o: ELF 32-bit LSB relocatable, Intel 80386, version 1 (SYSV), not stripped
其中的relocatable指出该文件为ELF中的可重定位文件类型。
2.4链接
链接后的文件为可执行文件,在linux中没有扩展名。终端执行:
gcc Example.o -o Example执行Example,终端运行:
./Example运行结果:

分析
用file命令查看Example属性:
file ExampleExample: ELF 32-bit LSB executable, Intel 80386, version 1 (SYSV), dynamically linked (uses shared libs), for GNU/Linux 2.6.16, BuildID[sha1]=0xffdc8de348d59ce38f1f933e55b7a5c55184ef39, not stripped
其中的executable指出该文件为ELF中的可执行文件类型。
由于程序没有任何打印语句,所以程序执行完之后就直接退出了。
3.计算机工作流程-单任务和多任务
4.参考资料
Computer Systems: A Programmer's Perspective 3rd Edith
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









