







A central achievement of classical linear algebra is a thorough examination of the problem of solving systems of linear equations,but there is an elementary problem that has to do with sparse solutions of linear systems, we shall concentrate on defining this problem carefully, and set the stage for its answers in later chapters
1.1 Underdetermined Linear Systems
Ax = b,
![]()
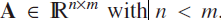 ,
A is a full-rank matrix,
,
A is a full-rank matrix,
,
A is a full-rank matrix,
1.2 Regularization(想要得到唯一解——》用凸函数(2阶为正,一介单调,函数值封闭,有唯一解,比如抛物线))
solutions
are infinitely many ,but we
desire a single solution->
Regularization

the image scale-up example, a function
J
(x) that prefers smooth or,
better yet, piecewise smooth results, is typically used
(1)
The most known choice of J(x) is the squared Euclidean norm L2,
Using Lagrange multipliers【
A full-rank,AA‘
positive definite
invertible
】

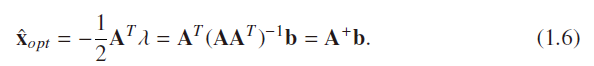
(2)a more general choice of the form J(x) = |Bx|2
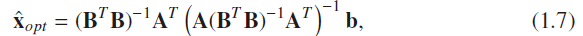
why we use L2——
simplicity as manifested by the above closed-form and unique solution【
strictly convex function
J
(X) guarantees uniqueness
】
the mathematical simplicity of ` L
2
is a
misleading fact that diverts engineers from making better choices for
J
(x). Indeed,
in image processing, after three decades of trying to successfully activate the (`
2
-
norm based) Wiener filter, it was eventually realized that the solution resides with
a di_erent, robust-statistics based choice of
J
(x),
this book.
1.3 The Temptation of Convexity——
guarantees
uniquenes
s
【向外凸的,因此任意两点的连线得到的线段比在此空间中,
non-convex可能有最优解,只是不完美而已,我们要避免
】
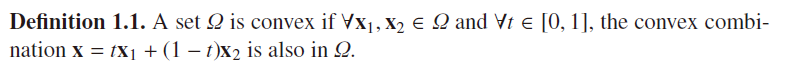
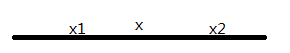
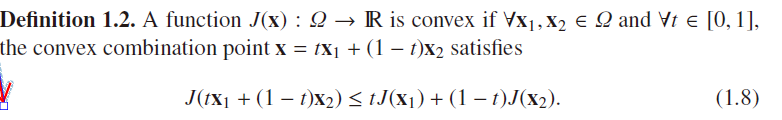
(1)如果从集合(definition1.1)的角度来看,
![]()
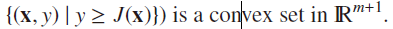
(2)
derivatives的角度来看(J必须
twice continuously differentiable
):
一阶:
![]()
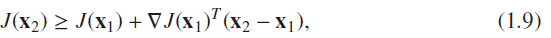
二阶:
![]()
注意:定义域必定为凸集
Special cases of interest for convex functions are all the `
p
-norms for p _ 1 (use
the Hessian to verify that). These are defined as
convex, 不一定strickly cinvex!比如L1,其坐标在第一象限的时候。
不一定strickly cinvex!比如L1,其坐标在第一象限的时候。
不一定strickly cinvex!比如L1,其坐标在第一象限的时候。
We shall have a special interest in L
1
due to its
tendency to sparsify the solution(因为1范数有助于稀疏,所以我们要研究一范数)
1.4 A Closer Look at `L
1
Minimization
因为L1不是严格凸的,因此
may have more than one solution
why 我们还要研究它呢?
(i) these solutions are gathered
in a set that is bounded and convex(最优解的图组合还是最优解,由J的凸性得到)
(ii) among these solutions, there exists at
least one with at most
n
non-zeros (
存在至少一个,最多n非零
)(as the number of constraints).
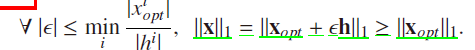
This implies that the addition/substraction of h under those
circumstances does not change the L
1
-length of the solution

以上推导,说明了一范数的优良特性,可以保证n的稀疏,但是远远不足于达到我们的需要,但是,作为追求稀疏的方法,是值得我们去了解的
1.5 Conversion of (P1) to Linear Programming
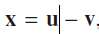
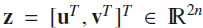
所以原来的L1问题可以转化为LP问题
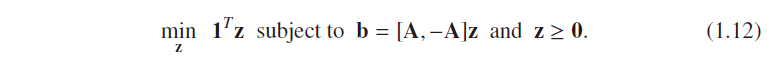
1.6 Promoting Sparse Solutions(为何会提出稀疏解)
illustrate 1 the tendency of p-norm to drive results to become sparse
p<1时,
the triangle inequality is no longer
satisfied

so
![]() ,
,
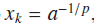

![]() ,
q一般比p要小,在为p范数下的单位ball的球心吹一个q球,如下图:dashed 和soild的交点就是我们要的解,
,
q一般比p要小,在为p范数下的单位ball的球心吹一个q球,如下图:dashed 和soild的交点就是我们要的解,
Lq是关于a单增的函数,故要使Lq最小,取a=1即可,{此处的理论意义在于Lq的min是在最稀疏处取得的!}
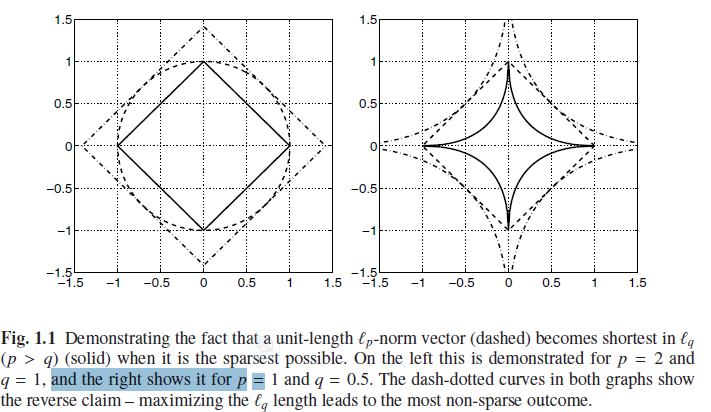
illustrate 2 the tendency of p -norm to drive results to become sparse
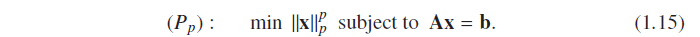
Geometrically speaking, solving ( P
p
) is done by “blowing” again an P
p
balloon,
centered around the origin, and stopping its inflation when it first touches the feasible
set:如下图:
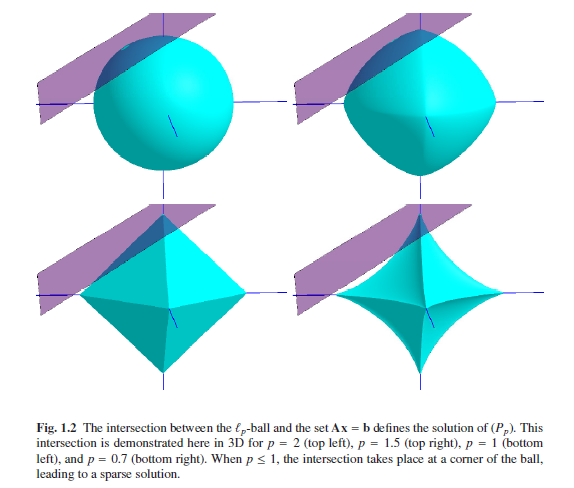
One can see that norms
with
p<=
1 tend to give that the intersection point is on the ball-corners, which take
place on the axes,[why p<=1才产生稀疏解,二在
illustrate 1 ,没有此限制,区别在,restrictive conditions
限制条件,illustrate 1 是在一个超空间里面blow ball,外球是限制条件,外球包含了内球,illustrate 1限制是一个约束平面,不存在包含关系,所以稀疏解产生的限制也增大了,仅仅在P<=1时才有稀疏解
]
上面提供了两种i解释,为什么我们要从范数的角度提出稀疏解,其实,我任然可以从若范数提供解释,但是诺番薯和范数都是基本等价,因此我们只是提出诺番薯的定义,不深入研究了
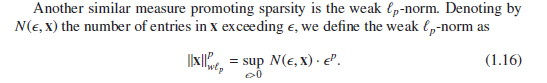
- summary:1.6 讨论,我们知道了,要解答一下问题
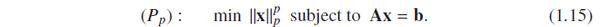
p只能取值(0,1),
Unfortunately,
each choice 0 <
p
< 1 leads to a
non-convex optimizatio【可以从理轮和几何图像上解释】
n problem, and this
raises some diffculties,
Nevertheless, from an engineering
point of view, if sparsity is a desired property, and we know that `
p
serves it
well, this problem can and should be used, despite its weaknesses
【?其他的函数族也会导致稀疏解吗,为何我们要限制在p范数上呢?当然有啦】
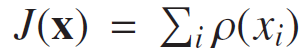
p(x) being symmetric, monotonically non-decreasing, and with a monotonic nonincreasing
derivative for x >0 will serve the same purpose of promoting sparsity.
As classic examples of this family, we mention p( x) = 1-exp(| x|), p(x) = log(1+
|x
|
),
and p(
x
) =
|x
|/
(1 +
|x
|
).
1.7 The l0-Norm and Implications
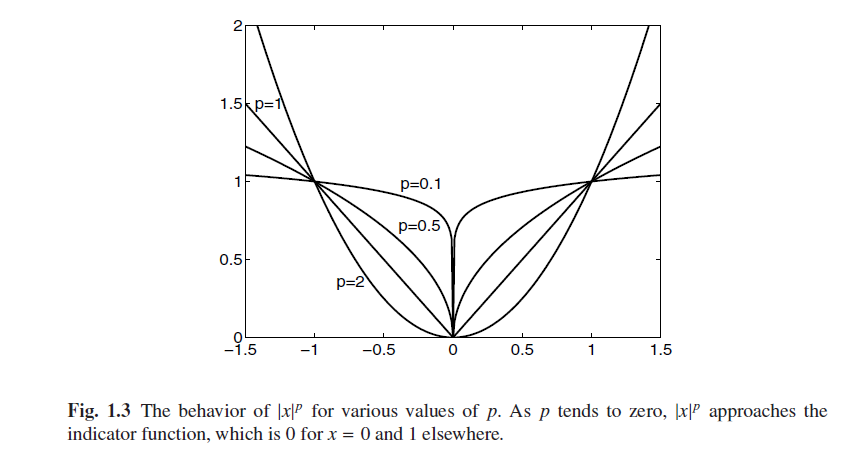
承上:既然p貌似越来越好,我们就来个极端点的吧,看有没有发现哈
取p=2,1,0.5,0.01,下图(y=|x|p)可以惊人发现,p越小,y
this curve becomes an indicator
function, being 0 for x = 0 and 1 for every other value
因此我们定义了令番薯
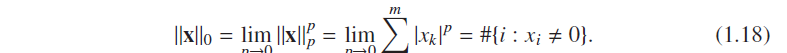
L0不满足范数的好多条件,没有0元和没有齐次关系(这个可能会困扰我们一辈子喔),但是满足三角不等式
我们会想,这个玩意儿对我们的实际工作有啥子用呢?还不如找其他的函数来刻画稀疏性呢?
(1)
A vector of real data would rarely be representable by a vector of coe_cients containing
many zeros.
(2)
A more relaxed and forgiving notion of sparsity can and should
be built on the notion of approximately representing a vector using a small number
of nonzeros; this can be quantified by the weak-`
p
and the usual `
p
-norms described
above.
Nevertheless, we proceed the discussion here with the assumption that `
0
is
the measure of
interest
1.8 The (P0) Problem – Our Main Interest(一个NP问题,我们只能找近似解法)
形式简单,但是难于解答:
These are rooted
in the discrete and discontinuous nature of the L
0
norm,不能用
convex analysis
(1)Can uniqueness of a solution be claimed? Under what conditions?
(2)If a candidate solution is available, can we perform a simple test to verify that
the solution is actually the global minimizer of ( P
0
)?
exhaustively sweep,is NP hard 问题,那肿么办呢?
Thus, a mandatory and crucial set of questions
arise:
Can (P
0
) be e_ciently solved by some other means?
Can approximate
solutions
be accepted?
How
accurate
can those be?
What kind
of approximations
will work?
1.9 The Signal Processing Perspective(
forward transform (from b to x) and its inverse (from x to b).
)
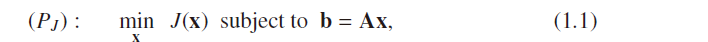
J为2范数时候,为redundant representations;
J为0范数时候,为sparse representations;
是什么催生了sparse,是需求,压缩表达的需求
many media types (still imagery, video, acoustic) can be sparsely represented
using transform-domain methods,
The appeal in such a transform is in the compact representation















 405
405











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









