







从本篇开始,将进入到深度学习的计算机视觉领域,在此之前有必要对传统 图像处理方法做个回顾。
传统图像处理
在我的【计算机视觉】基础图像知识点整理和【计算机视觉】数字图像处理基础知识题这两篇博文中,对于计算机视觉的基本知识有过梳理,并使用matlab进行了图像处理操作。在本节内容中,将使用python的opencv库,再次尝试对图像进行基本处理。
读入图片并显示:
import numpy as np
import matplotlib.pyplot as plt
import cv2
img = cv2.imread('photo.jpg')
#OpenCV在读取图像时会默认图像通道的顺序是BGR,将其转换为RGB
img = cv2.cvtColor(img,cv2.COLOR_BGR2RGB)
plt.figure(dpi=150) # dpi-分辨率
plt.imshow(img)
plt.axis('off'); #不显示坐标轴
显示原图如图所示:

注意:OpenCV默认图像通道的顺序是BGR,如果不进行转换,三通道红色和蓝色通道会交换,变成这样…

画面调整
画面亮度调整
首先对图片像素进行归一化方便处理,直接让图片三通道的数值增大,画面会被调亮;反之画面被调暗。
#调亮画面
img = img/255
img_ = np.clip(img + 100/255,0,1) #np.clip 将数值限制在0,1;否则会循环
plt.figure(dpi=100)
plt.imshow(img_)
plt.axis('off');
效果如图:

饱和度调整
将BGR通道转换称HSV通道后,可以将图片的色相、饱和度、亮度三个通道分离出来,单独进行调整
这里以增大饱和度为例
img = cv2.imread('photo.jpg')
#OpenCV默认读取后的图像通道是BGR,为了调整饱和度,将通道转换为HSV
img_hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
h, s, v = cv2.split(img_hsv)
#h += np.clip(s*1.0+100,0,255).astype("uint8") # 色相
s += np.clip(s*1.0+100,0,255).astype("uint8") # 饱和度
#v += np.clip(s*1.0+100,0,255).astype("uint8") # 亮度
final_hsv = cv2.merge((h, s, v))
img_s = cv2.cvtColor(final_hsv, cv2.COLOR_HSV2RGB)
plt.figure(dpi=100)
plt.imshow(img_s)
plt.axis('off');
效果如下:

边缘检测
下面将使用一张灰度图,利用Laplacian和Sobel两个边缘算子完成边缘检测。
img = cv2.imread("edge.png")
# 索贝尔等经典卷积操作在灰度图像上表现更好,因此将图像导入时就转化为灰度图像
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 两种经典算子:拉普拉斯与索贝尔
laplacian = cv2.Laplacian(img, cv2.CV_64F, ksize=5)
# 在这里输入之后可以保证输出数据是uint8类型
sobelx = cv2.Sobel(img, cv2.CV_64F, 1, 0, ksize=5) # 横向的索贝尔,旋转矩阵为5X5
sobely = cv2.Sobel(img, cv2.CV_64F, 0, 1, ksize=5) # 纵向的索贝尔,旋转矩阵为5X5
plt.figure(dpi=300)
plt.subplot(2, 2, 1), plt.imshow(img, cmap="gray")
plt.title("Original"), plt.axis("off")
plt.subplot(2, 2, 2), plt.imshow(laplacian, cmap="gray")
plt.title("Laplacian"), plt.axis("off")
plt.subplot(2, 2, 3), plt.imshow(sobelx, cmap="gray")
plt.title("Sobel X"), plt.axis("off")
plt.subplot(2, 2, 4), plt.imshow(sobely, cmap="gray")
plt.title("Sobel Y"), plt.axis("off")
效果如下:

卷积
原理
卷积的思想是受到人体视觉生理过程的启发:人类的眼球中含有一系列视觉细胞,但这些细胞不是等价的,他们之中的一部分是简单细胞,只能捕捉到简单的线条、颜色等信息,这些简单细胞捕捉到简单信息后,会将信息传导至复杂细胞,复杂细胞会将这些信息重组为轮廓、光泽等更高级的信息,之后再将信息传导至更高级的细胞,形成完整的图像。
卷积核(Convolution Kernel)(有的文献也称为过滤器(filter))就是在模拟人类中的视觉细胞。如图所示,图中绿色区域部分被称作感受野(receiptive field),卷积核与感受野轮流点积得到的新矩阵叫做特征图(feature map)
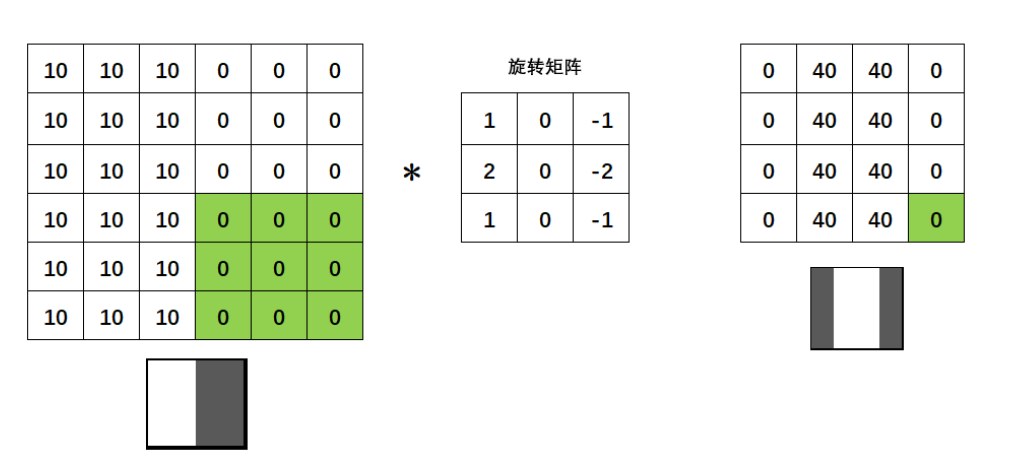
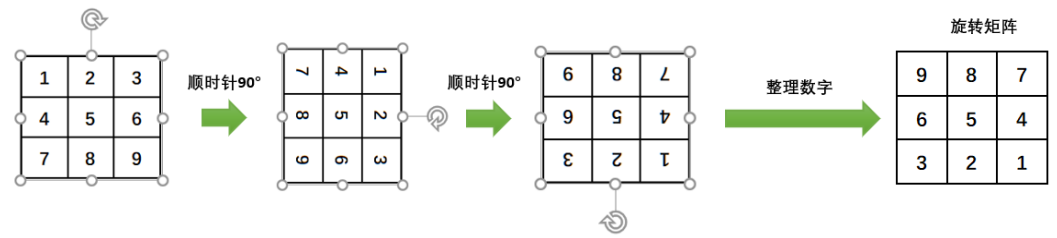
在信号与系统课程中,接触过一维卷积,信号的一维卷积就是将其中的一个信号先翻转再相乘相加。这个翻转的过程就是”卷“。在图像中,二维卷积同样有”卷“的过程,对于矩阵的卷,就是将矩阵旋转180°,过程如图所示:
然而在实际处理中,这个旋转的步骤往往被省略,直接演变成了对应点相乘再相加的形式。
编程
在pytorch中,nn.Conv2d这个函数能够实现2维卷积。
其中,有下列一些参数:
torch.nn.Conv2d (in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1,
groups=1, bias=True, padding_mode='zeros'
| 参数 | 描述 |
|---|---|
| kernel_size | 卷积核的尺寸。无默认值,必填 |
| in_channels | 整数,输入图像的通道数 |
| out_channels | 整数,输出的特征图的数量,同时等于卷积核的数量 |
| bias | 布尔值,"True"则代表在卷积层中使用偏置,反之则不使用偏置 |
| stride | 整数或数组,卷积核扫描时的步长。输入整数,则默认为水平方向的步长。输入数组,则同时控制水平和竖直方向的步长。默认为1。 |
| padding | 整数或数组,在输入图像的两边分辨进行填充。默认为0。 |
| padding_mode | 填充的方式,可输入’zeros’, ‘reflect’ , 'replicate’或者’circular’四种选项来选择填充模式。 |
特征图大小计算公式:
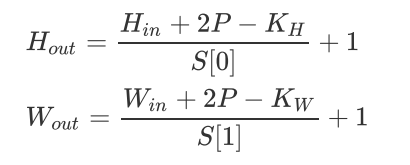
卷积层参数量计算公式:
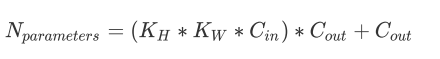
池化
池化很容易理解,即在特征图上将一块块区域打包进行处理,最常见的是最大池化(Max Pooling)和平均池化(Average Pooling)
Pytorch中,相关接口为nn.MaxPool和nn.AvgPool
两个接口参数类似,以MaxPool2d为例,有下列一些参数:
CLASS torch.nn.MaxPool2d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False,
ceil_mode=False)
其中kernel_size就是池化核的尺寸,一般都设置为2X2或3X3。Padding参数与Stride参数一般都不填
写。
Dropout
Dropout是在神经网络训练时,随机让一些神经元”失活“(权值变0),有利于防止过拟合,示意图如下:
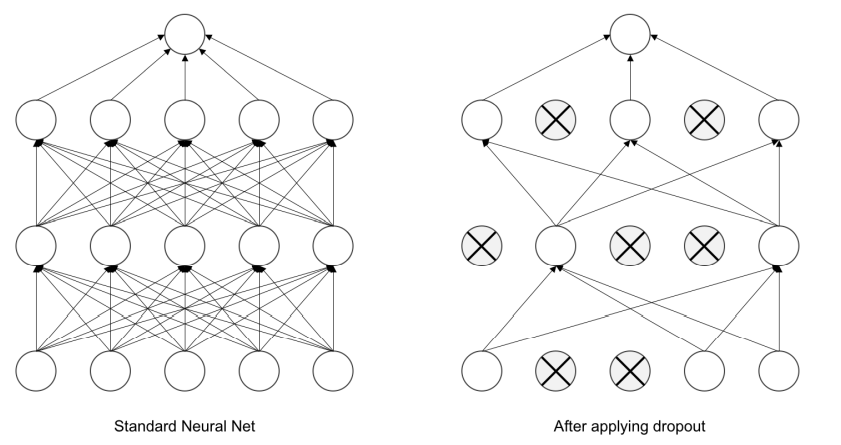
在Pytorch中,可用nn.Dropout2d(p=0.1)进行调用,这里的p表示概率p,即Dropout层会随机选择p * N个神经元进行沉默。
下一篇将使用这些知识来尝试复现经典网络LeNet5与AlexNet。
















 459
459











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











