







4. 神经网络
网络模型:

4. 1卷积
4.1.1 概念
卷积就是通过卷积核与输入相乘再相加。它可以获取图像的局部特征。因此卷积核也被称为滤波器。
卷积时参数的计算公式:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GQusqaHq-1647827095381)(image-20220216185903991.png)]](https://img-blog.csdnimg.cn/848a05b8fd9a4dea8b6ad33e0ee84699.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAaGFwcHk0ODgxMjczMTE=,size_20,color_FFFFFF,t_70,g_se,x_16)
分类
-
膨胀卷积(Dilated Convolutions)
- 引入了膨胀率(dilation rate)。
- 膨胀率是核中每个值之间的距离。一个膨胀率为2的3x3的核与一个5x5的核有相同的视野,唯一的区别就是3*3的核只有9个参数。
- 膨胀卷积的好处是在相同的计算成本下,提供了更宽的可视域。膨胀卷积在实时分割领域非常流行。
- 当需要比较宽阔的可视域(field of view)同时又没有多卷积或者更大核的条件时,可以采用膨胀卷积。
-
转置卷积(Transposed Convolutions)
- 进行上采样,不是卷积的逆运算,也是卷积的一种。
- 只是将大小还原到卷积前的大小,但是数值可能不一样。
- 步骤:
- 在输入特征图元素间填充``stride-1`行和列的0
- 在输入特征图四周填充``kernel_size-padding-1`行和列的0
- 将卷积核参数上下、左右翻转
- 做正常卷积运算(填充0,步距1)

4.1.2 特点
利用卷积可以对数据进行下采样和特征提取
- 卷积操作后,输出的通道数=卷积核的个数 * 卷积核的通道数
- 卷积核的个数和卷积核的通道数是不同的概念。每层卷积核的个数在设计网络时会给出,但是卷积核的通道数不一定会给出。
- 默认情况下,卷积核的通道数=输入的通道数,因为这是进行卷积操作的必要条件。
4.1.3 PyTorch中的卷积
以二维卷积为例
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros', device=None, dtype=None)
in_channels:输入图像的通道数out_channels:卷积产生的通道数kernel_size:卷积核大小stride:步长,默认1padding:填充的边距,可以是Str{‘valid’, ‘same’}。或者一个元组(2,3),或者一个整数。默认0。dilation:卷积核每个元素之间的间距,默认1。也就是没有间隔groups:从输入通道到输出通道的阻塞连接数。默认值:1
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
dataset = torchvision.datasets.CIFAR10("dataset", train=False, transform=transforms.ToTensor(), download=True)
dataLoader = DataLoader(dataset, batch_size=64)
class MyNN(nn.Module):
def __init__(self) -> None:
super().__init__()
# 将二维卷积核定义为变量
# in_channels: 输入矩阵通道数
# out_channels: 输出矩阵通道数
# kernel_size: 卷积核大小
self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0)
def forward(self, x):
x = self.conv1(x)
return x
demo_nn = MyNN()
writer = SummaryWriter("nn")
step = 0
for data in dataLoader:
imgs, target = data
output = demo_nn(imgs)
print(imgs.shape) # torch.Size([64, 3, 32, 32])
print(output.shape) # torch.Size([64, 6, 30, 30])
# 将图像添加到tensorboard中
writer.add_images("input", imgs, step)
# 因为输出图像有6个channel,无法进行展示,因此将其转换为3通道
# 第一个参数:要转换的矩阵
# 第二个参数:转换后形状,
# 第一个参数是像素点个数,-1表示不知道有多少个像素,会自动计算,
# 3是通道数,
# 30,30是宽和高
output = torch.reshape(output, (-1, 3, 30, 30))
print(output.shape) # torch.Size([128, 3, 30, 30])
writer.add_images("output", output, step)
step += 1
writer.close()
4.1.4 卷积示例
输入是5x5,无填充的边缘,3 x 3的卷积核,stride=1。输出大小是3 x 3。
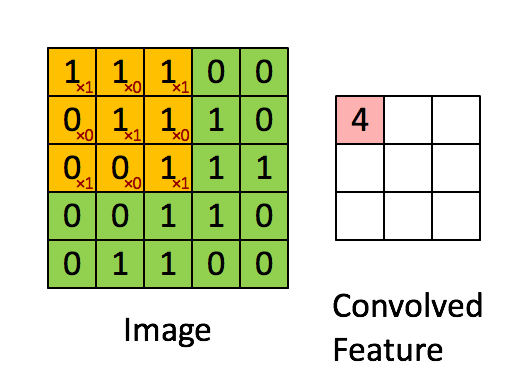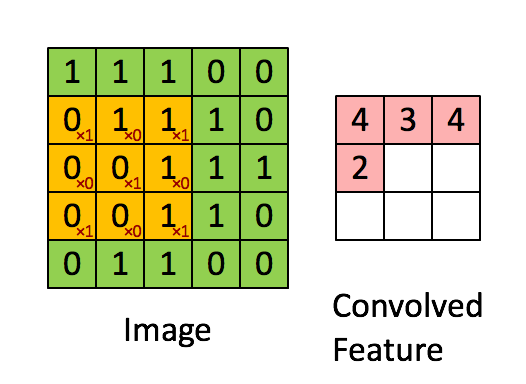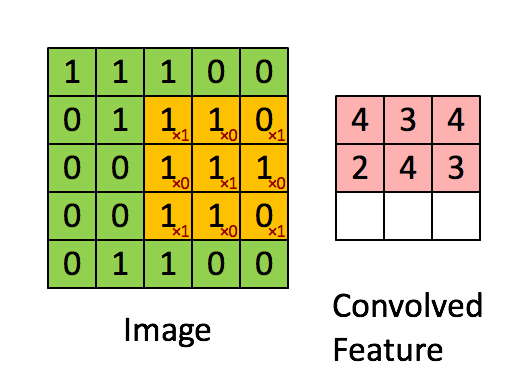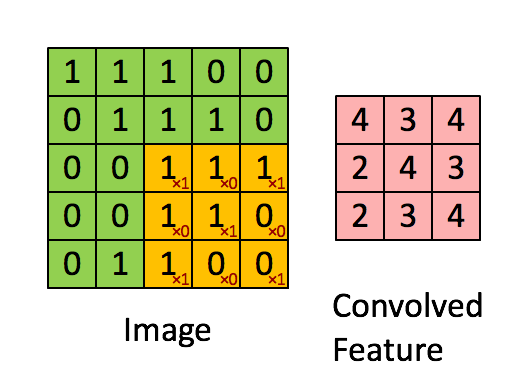
更多卷积动画可以看Github演示:Convolution arithmetic
4.2 池化
4.2.1 概念
池化即降采样(subsample),作用是降低输入图片的尺寸,降低数据的大小。
在卷积神经网络中,每一个卷积层后面总会跟着一个池化层。
添加池化层的作用是加速运算并且使得一些检测到的特征更强。
池化操作也会用到kernel和步长。
- 最大池化:Max Pooling(最常用)
- 平均值池化:Average Pooling
4.2.2 池化的作用
- 可以减少计算量,内存使用,参数数量(防止过拟合)
- 提高神经网络的容错能力(图片发生平移,位置的变动)

池化和卷积的异同:
- 通道方面:
- 使用池化不会造成数据矩阵深度的改变,只会在高度和宽带上降低,达到降维的目的。池化前几个通道,池化后还是几个通道。
- 上一层的feature map的个数(也即图层个数)与下一层的卷积核通道数一致。
- 卷积对应有卷积核,池化对应有池化核。卷积核里面有参数,但是池化核只是一个框架,里面没有参数。
- 使用方面都需要,定义其大小(size),步长(stride),padding类型。
- 卷积里面一般用padding same ;池化里面用padding valid
4.2.3 PyTorch中的池化
torch.nn.MaxPool2d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False)
kernel_size– 卷积核大小stride– 步长,默认为卷积核大小padding– 要在两侧添加的隐式零填充dilation– 卷积核每个元素之间的间距,默认1ceil_mode– 向上取整模式,True或者False
import torch
import torchvision.datasets
from torch import nn
from torch.nn import MaxPool2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
class MyNN(nn.Module):
def __init__(self) -> None:
super().__init__()
# MaxPool2d: 最大池化
# ceil_mode: 向上取整模式,当输入矩阵最后剩余的大小不足kernel_size时,
# 如果ceil_mode为Ture则保留,否则不保留
self.max_pool = MaxPool2d(kernel_size=3, stride=1, ceil_mode=True)
def forward(self, input):
output = self.max_pool(input)
return output
dataset = torchvision.datasets.CIFAR10("./dataset", train=False, download=True,
transform=torchvision.transforms.ToTensor())
dataLoader = DataLoader(dataset, batch_size=64)
writer = SummaryWriter("max-pool")
# 后边不写数据类型时默认为Long,会报错 RuntimeError: "max_pool2d" not implemented for 'Long'
input = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]], dtype=float)
input = torch.reshape(input, (-1, 1, 5, 5))
print(input.shape)
demo_nn = MyNN()
output = demo_nn(input)
print(output)
step = 0
for data in dataLoader:
imgs, targets = data
writer.add_images("max-pool-input", imgs, step)
output = demo_nn(imgs)
writer.add_images("max-pool-output", output, step)
step += 1
writer.close()
















 705
705











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











