







概述
要用好rag的输出增强效果,文档解析是关键一环。如果文档解析块存在问题,那么后面检索到的内容,也会对模型造成错误干扰。
前文分析过,ragflow使用自研的Deepdoc算法对不同类型的文档进行解析,然而,对于pdf文件,在多数情况下的解析效果并不如意。
下图中,所上传的论文为扫描版,扫描质量一般,在进行文档解析之后,出现了很多错别字,而且语句中的标点符号识别得相当糟糕。
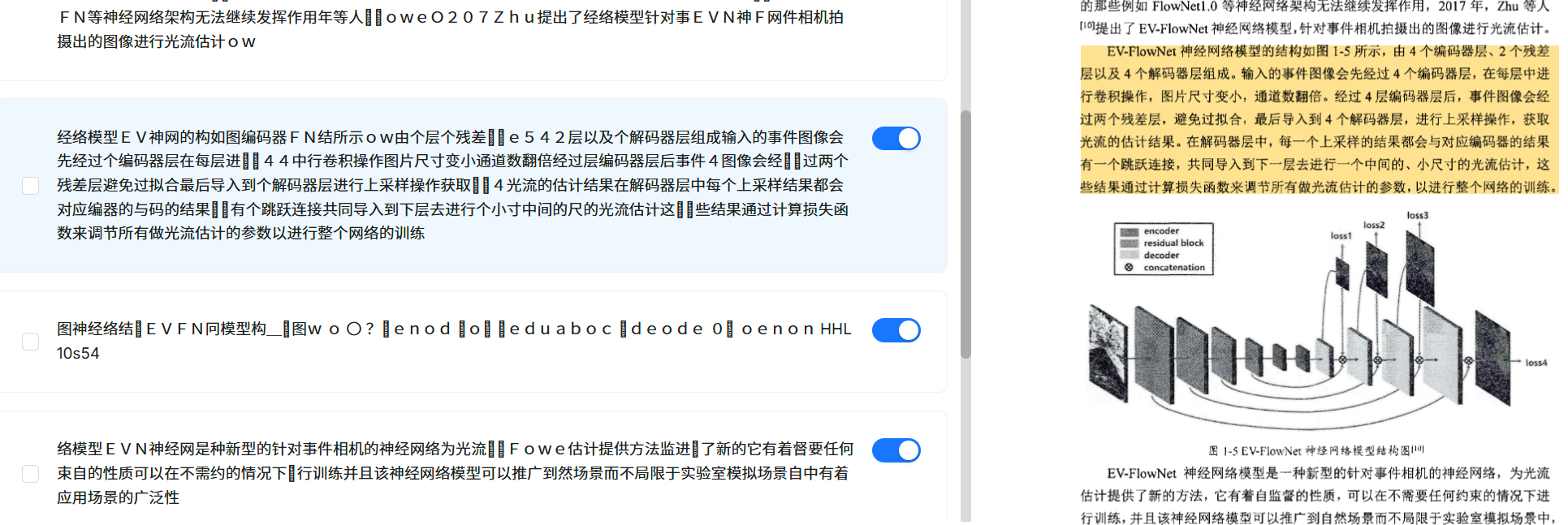
此外,对于gpu的加速,图像的解析提取,Deepdoc也支持得并不完善。
因此,亟需一种更优质的文档解析算法。
同类文档产品调研
经调研,开源的文档解析产品主要有MinerU、Marker、MarkItDown、Docling四款主流产品。对于Doc2X,TextIn等未开源的收费产品,不在本文的考虑范围之内。
这四款开源产品及对应的开发公司如下表所示:
| 工具名称 | 开发团队/公司 |
|---|---|
| MinerU | 上海AI实验室(OpenDataLab) |
| Marker | VikParuchuri(个人开发者) |
| MarkItDown | 微软(Microsoft) |
| Docling | IBM |
考虑到本土部署,需要优先支持中文文档的解析,大致浏览了一下这四款产品的仓库,发现MinerU的生态非常完善,并且文档都有中文版本,对本土开发者非常友好,于是对其进行研究。
MinerU 网页试用
MinerU 有在线试用网页,可让用户直接上传文件进行解析。
地址如下:
https://mineru.net/OpenSourceTools/Extractor
我上传了图1中相同的论文,相同部分解析效果如下:

解析效果让我震撼,不仅中文和标点能够精准的解析出来,英文解析也没有错误。

MinerU 本地部署
MinerU 仓库地址:https://github.com/opendatalab/MinerU
MinerU提供了两种部署方式,python包部署和docker部署。考虑到后续需要对其进行二次开发,下面使用前者的部署方式。
具体步骤如下:
- 创建环境
conda create -n mineru 'python<3.13' -y
conda activate mineru
- 安装依赖
pip install -U magic-pdf[full]
如果上述命令安装依赖失败,可采用这条命令:
pip install "magic-pdf[full]==1.3.0" --extra-index-url https://wheels.myhloli.com -i https://pypi.tuna.tsinghua.edu.cn/simple
顺利安装后,可以查看magic-pdf的具体版本:
magic-pdf --version
目前最新版本是1.3.0。
- 下载模型
通过以下方式下载模型:
pip install huggingface_hub
wget https://github.com/opendatalab/MinerU/raw/master/scripts/download_models_hf.py -O download_models_hf.py
python download_models_hf.py
如果windows系统,可以直接将代码链接中的download_models_hf.py文件拷贝下来,本地执行。
执行完成之后,会在C:/Users/username路径下生成一个magic-pdf.json的配置文件。
如果已经在windows中下载好模型,需要迁移到linux服务器中,可以手动将模型拷贝到hub的模型存储位置,同时将官方仓库的magic-pdf.template.json文件拷贝到执行路径下,运行下面我略做调整的代码:
import json
import os
import shutil
import requests
from huggingface_hub import snapshot_download
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com' # 设置镜像源
def download_and_modify_json(url, local_filename, modifications):
if os.path.exists(local_filename):
data = json.load(open(local_filename 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 472
472

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











