







数据输入
RDD对象
如图可见,PySpark支持多种数据的输入,在输入完成后,都会得到一个:RDD类的对象
RDD全称为:弹性分布式数据集(Resilient Distributed Datasets)
PySpark针对数据的处理,都是以RDD对象作为载体,即:
- 数据存储在RDD内
- 各类数据的计算方法,也都是RDD的成员方法
- RDD的数据计算方法,返回值依旧是RDD对象
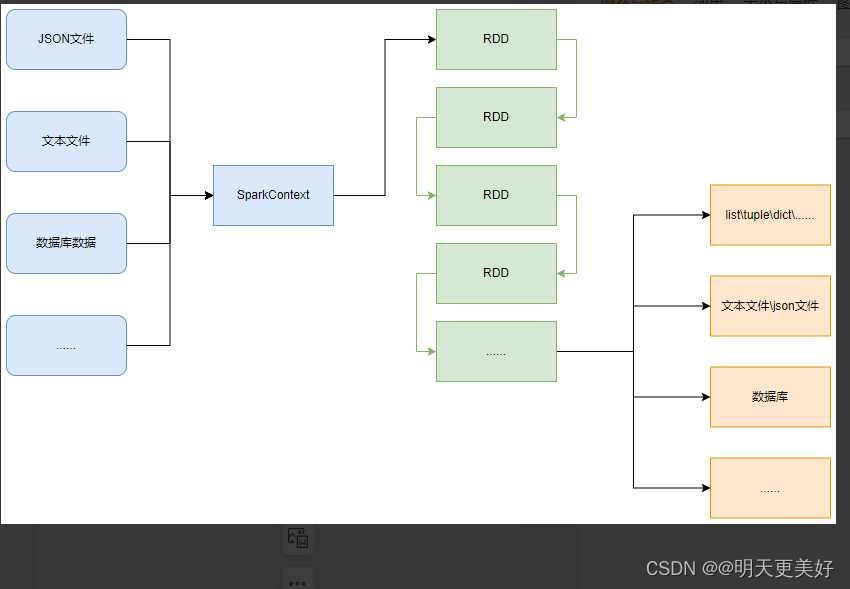
PySpark的编程模型(上图)可以归纳为:
- 准备数据到RDD -> RDD迭代计算 -> RDD导出为list、文本文件等
- 即:源数据 -> RDD -> 结果数据
Python数据容器转RDD对象
PySpark支持通过SparkContext对象的parallelize成员方法,将:
- list
- tuple
- set
- dict
- str
转换为PySpark的RDD对象
注意:
- 字符串会被拆分出1个个的字符,存入RDD对象
- 字典仅有key会被存入RDD对象
读取文件转RDD对象
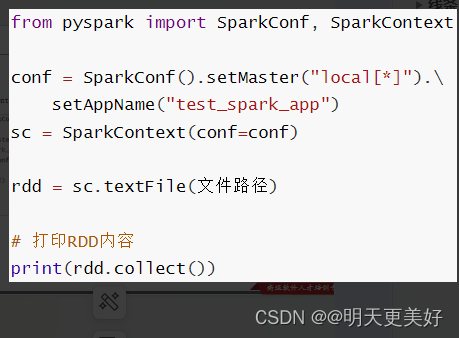
PySpark也支持通过SparkContext入口对象,来读取文件,来构建出RDD对象。
总结:
1. RDD对象是什么?为什么要使用它?
RDD对象称之为分布式弹性数据集,是PySpark中数据计算的载体,它可以:
- 提供数据存储
- 提供数据计算的各类方法
- 数据计算的方法,返回值依旧是RDD(RDD迭代计算)
后续对数据进行各类计算,都是基于RDD对象进行
2. 如何输入数据到Spark(即得到RDD对象)
- 通过SparkContext的parallelize成员方法,将Python数据容器转换为RDD对象
- 通过SparkContext的textFile成员方法,读取文本文件得到RDD对象
数据计算
map方法
PySpark的数据计算,都是基于RDD对象来进行的,那么如何进行呢?
自然是依赖,RDD对象内置丰富的:成员方法(算子)

语法:

"""
演示PySpark代码加载数据即数据输入
"""
from pyspark import SparkConf, SparkContext
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)
# # 通过parallelize方法将Python对象加载到Spark内,成为RDD对象
rdd1 = sc.parallelize([1, 2, 3, 4, 5])
rdd2 = sc.parallelize((1, 2, 3, 4, 5))
rdd3 = sc.parallelize("abcdefg")
rdd4 = sc.parallelize({1, 2, 3, 4, 5})
rdd5 = sc.parallelize({"key1": "value1", "key2": "value2", "key3": "value3"})
# # 如果要查看RDD里边有什么内容,需要用collect()方法
print(rdd1.collect())
print(rdd2.collect())
print(rdd3.collect())
print(rdd4.collect())
print(rdd5.collect())
# 用过textFile方法,读取文件数据加载到Spark内,成为RDD对象
rdd = sc.textFile("E:/百度网盘/1、Python快速入门(8天零基础入门到精通)/资料/第15章资料/资料/hello.txt")
print(rdd.collect())
sc.stop()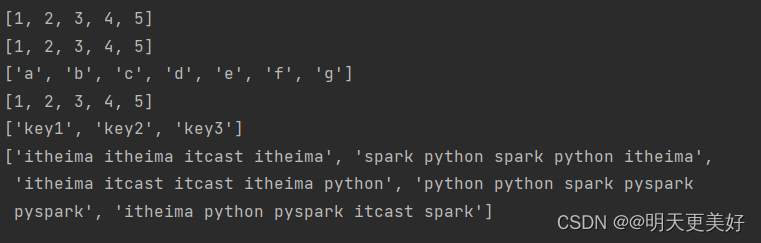
总结:
1. map算子(成员方法)
- 接受一个处理函数,可用lambda表达式快速编写
- 对RDD内的元素逐个处理,并返回一个新的RDD
2. 链式调用
- 对于返回值是新RDD的算子,可以通过链式调用的方式多次调用算子。
flatMap方法


总结
flatMap算子
- 计算逻辑和map一样
- 可以比map多出,解除一层嵌套的功能
reduceByKey方法

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 285
285











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











