






kmp算法被看为是对普通字符匹配算法的一种改进,这种改进对于算法的时间复杂度来说从原本的O(n2)-》O(n+m),相对来说降低了算法的时间复杂度
1.kmp算法的原理
KMP 算法主要是通过消除主串指针回溯(只前进,不后退),模式串指针回溯有要求(根据next数组来回溯)来提高匹配的效率的
解释next数组构造过程中的回溯问题
大家来看下面的图:
下图中的1,2,3,4是一样的。1-2之间的和3-4之间的也是一样的,我们发现A和B不一样;之前的算法是我把下面的字符串往前移动一个距离,重新从头开始比较,那必然存在很多重复的比较。现在的做法是,我把下面的字符串往前移动,使3和2对其,直接比较C和A是否一样。
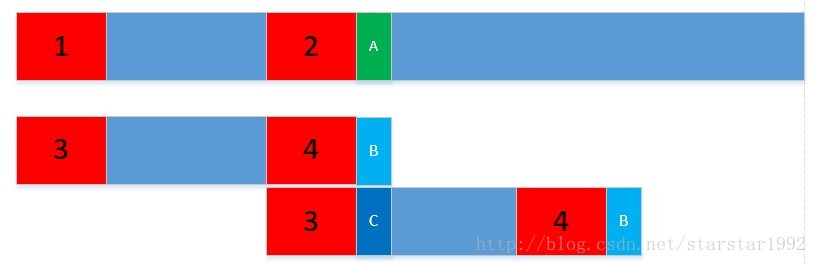

就是在一个子串找到两个相同的部分,当后面的这个部分匹配不上时,将前面的部分移动到当前的位置,减少了时间复杂度在模式串匹配串时j表示已经匹配上了j个字符了,但是在j+1个字符匹配失败,所以有j个字 符的部分模式串需要后退(j指针后退变小)因为j+1的匹配失败表明下次再重新匹配时(j后退完成后)j值肯定小于j后退前的值,因为已经匹配到j个字符了(部分模式串)j后退退到ne[j]的位置因为ne[j]表示当有j个字符时最大前缀后缀的共同元素个数。例:若j=5,j+1匹配失败退到ne[5],若ne[5]=2,则表示当模式串的部分模式串(只有前五个字符)可以匹配上两个字符所以后退后j=2,即退后的模式串相比后退前的模式串中有两个已经匹配好了,然后j+1继续匹配主串即可。
下面是KMP的源码
int KMP(char *str, int slen, char *ptr, int plen)
{
int *next = new int[plen];
get_next(ptr, next, plen);//计算next数组
int k = -1;
for (int i = 0; i < slen; i++)
{
//ptr和str不匹配,且k>-1(表示ptr和str有部分匹配)往前回溯
while (k >-1&& ptr[k + 1] != str[i])
k = next[k];
//如果匹配就一直往下走
if (ptr[k + 1] == str[i])
k = k + 1;
//说明k移动到ptr的最末端,即匹配成功了
if (k == plen-1)
return i-plen+1;//返回相应的位置
}
return -1;
}2.求解next数组
next数组是kmp算法中最关键的部分
我们首先看一下严蔚敏书上的代码
void get_next(int next[],SString T)
{
next[0]=-1; //下标为0的元素直接为-1,方便计算
next[1]=0; //下标为1元素直接为0
int i=1,j=-1;
while(i<=T.len)
{
if(j==-1||T[i]==T[j])
{
++i;
++j;
//由上面两行可以看出来,next数组的值是由
//上一个元素计算出来的
next[i]=j;
}
else
j=next[j]; //这个后面会介绍到
}
}我们可以先来看一个字符串 ababa
他的next数组可以很好的求出来
j=-1,i=1 ---》 j=0,i=2,next[2]=0
j=0,i=2 ---》 j=1,i=3,next[3]=1
j=1, i=3 ---》 j=2,i=4,next[4]=2
a b a b a
next -1 0 0 1 2
我们可以得出一个规律,next[n]=k;他前面有k个与前缀相同的字符串
即 p1p2...pk=pj-k+1...pj
我们还注意了一行代码 j=next[j];
理解j=next[j],首先我们需要理解next[i]=j
next[i]=j表示:next[i]表示当有i个字符时最大前缀后缀的共同元素个数为j
next数组中每一个元素都是表示前面n个字符最大前缀后缀的共同元素
这行代码是什么意思呢,下面这张图可以给出答案
我们发现了j=next[j]的意思是不断往前找到重合的最多部分,直到没有重合
还有一种情况是next[0]不是-1,而是0开始
他的源代码就变成了
void get_next(int next[],SString T)
{
next[0]=0; //下标为0的元素直接为-1,方便计算
int i=1,j=-1;
while(i<=T.len)
{
if(j==-1||T[i]==T[j])
{
++i;
++j;
//由上面两行可以看出来,next数组的值是由
//上一个元素计算出来的
next[i]=j+1;
}
else
j=next[j]; //这个后面会介绍到
}
}他的意思是next[n]=k+1;他前面有k个与前缀相同的字符串并且再加上一个1
这样子做是为了方便回溯
于是我们可以得出一个规律
next[0]=0; next[n]=k+1;
next[0]=-1; next[n]=k;
在书中还加上了修正过的getnext代码
while(i<=T.len)
{
if(j==-1||T[i]==T[j])
{
++i;
++j;
if(T[i]==T[j])
next[i]=next[j];
//现在next只储存有意义的值,如果是1,2,3这种递增的直接储存为0,-1
//防止多次比较增加时间复杂度
else
next[i]=j;
}
else
j=next[j];
}
| 下标 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|---|
| 子串 | a | b | a | b | a | a | a | b |
| next | -1 | 0 | 0 | 1 | 2 | 3 | 1 | 1 |
| nextval | -1 | 0 | -1 | 0 | -1 | 3 | 1 | 0 |
| j(next[i]=j) | null | 0 | 0 | 1 | 2 | 3 | 1 | 1 |
只储存了最大的next数组元素,如果无意义的递增直接跳过,让他等于next[j] ,说明和前缀一一对应
3.完整代码
#include <iostream>
using namespace std;
int Next[7];
void get_next(char *T,int plen)
{
int i = 1,j=-1;
Next[0] = -1;
Next[1] = 0;
while (i < plen)
{ //i代表现在移动到第几个元素
//j代表现在是串头的第几个元素
if (j == -1 || T[j] == T[i])
{
++i;
++j;
Next[i] = j;
}
else
j = Next[j];
//这个代码对字串也进行了模式匹配,让他回溯到表头第?个元素
}
}
int KMP(char* str, int slen, char* ptr, int plen)
{
int k=0;
get_next(ptr,plen);
for (int i = 0;i < slen;i++)
{
//未匹配情况
while (ptr[k + 1] != str[i] && k > -1)
k = Next[k]; //Next[k]的值表明它对应字串前缀第几个元素
//能够匹配的情况
if (ptr[k + 1] == str[i])
k++;
//匹配完成的情况
if (k == plen - 1)
return i-plen+1; //返回第一个字符所在位置
}
return -1;
}
int main()
{
memset(Next, -1, sizeof(Next));
char str[] = "bacbababadababacambabacaddababacasdsd";
char ptr[] = "ababaca";
int Position=KMP(str,38,ptr,7); //返回字串第一个字符位置
cout << Position;
}














 889
889











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









