






一、API接口搭建(百度云)
这里选用的是百度云的文心一言来实现智能问答,下面介绍具体的接口搭建
1、进入官网注册账号
官方网址:百度智能云-登录 (baidu.com)
这里扫码登陆即可 百度APP或者百度网盘APP进行登录
2、按照步骤进行接口搭建
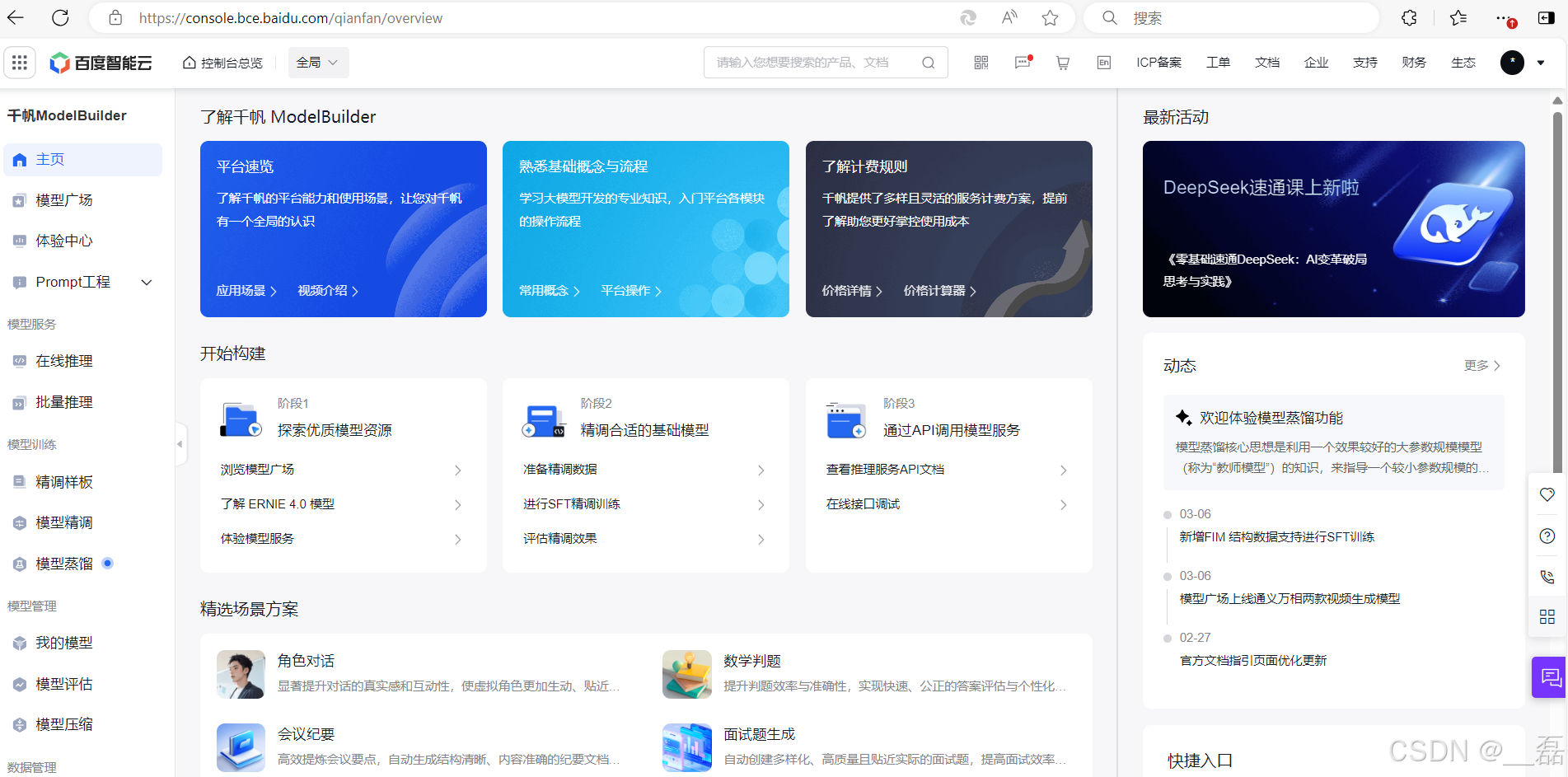
左侧往下翻找到应用接入点击,然后点击创建应用进行创建
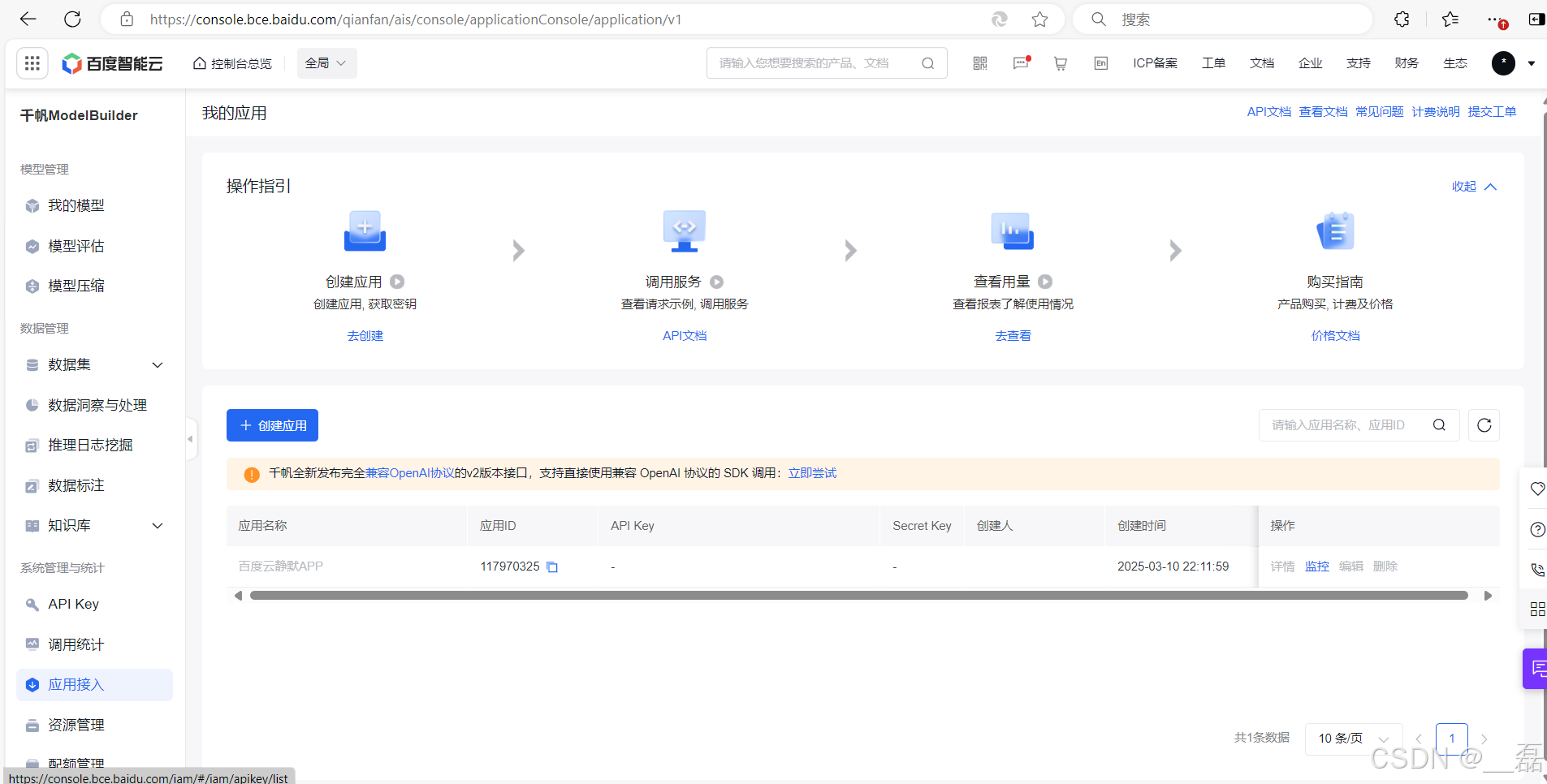
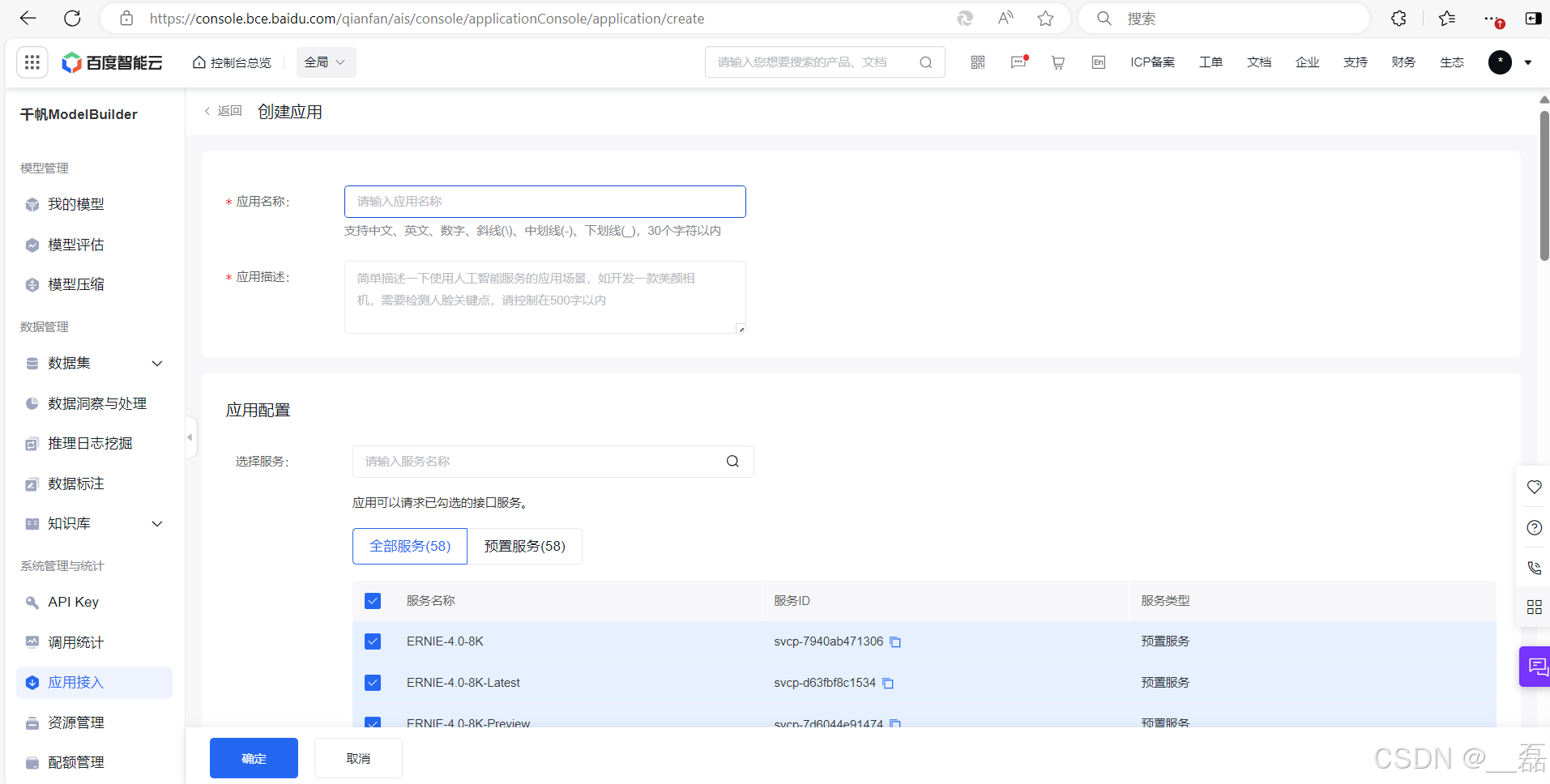
这里根据自己的喜好进行填写应用名称 应用描述,下面的应用配置建议全部选择,然后点击确认即可
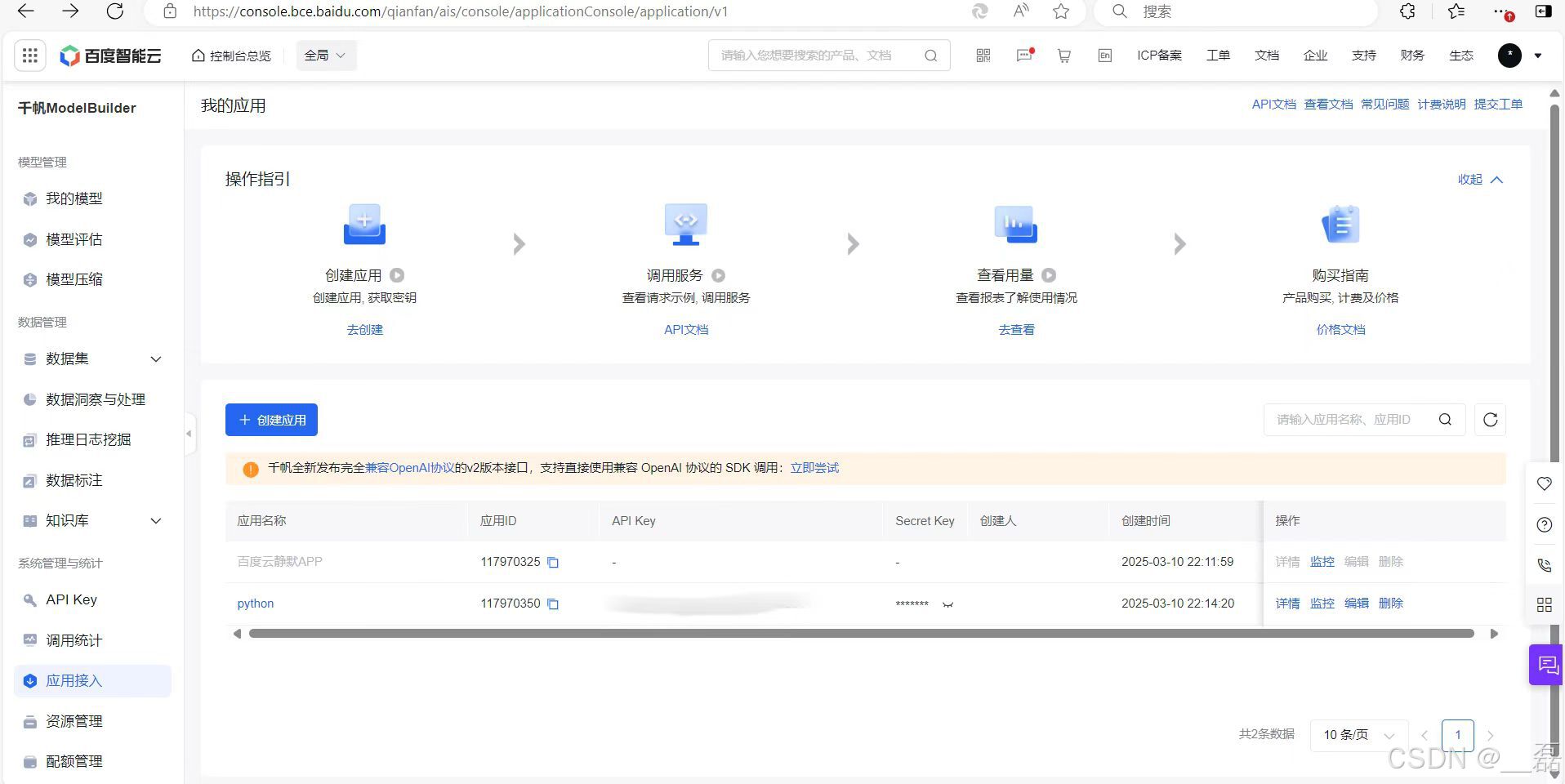
这里需要记下API Key 和 Secret Key,后面代码中会用到
到此百度云的API已经搭建完成,就可以进入第二步啦
二、项目整体分析
本项目是一个基于 Python 实现的语音助手,利用了 Vosk 语音识别库、百度文心一言 API 进行语音指令处理和响应,同时结合了 pyttsx3 实现语音合成。此外,还支持通过终端输入指令进行交互,具备多线程处理能力。
1.功能概述
-
语音识别:
- 使用 Vosk 离线语音识别模型,对用户语音指令进行识别。
- 支持中文语音识别,通过设定唤醒词(如“小智小智”“你好助手”)来触发语音助手。
- 语音合成:
- 使用
pyttsx3进行语音反馈,例如:在识别到指令后播报结果。 - 封装了一个线程安全的语音合成类
ThreadSafeTTS,确保多线程环境下语音合成不会冲突。
- 使用
- 终端交互:
- 用户在终端中输入指令(如“你好小智”),也可以唤醒语音助手并处理相应指令。
- 终端监听通过独立线程运行,支持输入
exit指令来关闭程序。
- 与百度文心一言 API 集成:
- 利用百度 AI 平台的文心一言 API,进行更复杂的自然语言处理和生成任务。
- 通过 Access Token 鉴权,发送用户指令给 API,并接收和处理 API 的响应。
- 多线程机制:
- 实现了多线程处理,包括语音监听线程、终端监听线程,以及指令处理线程。
- 使用线程锁(
threading.Lock)和队列(queue.Queue)确保线程安全。
2、项目架构与模块分析
(1)核心类设计
ThreadSafeTTS类:- 封装
pyttsx3,实现线程安全的语音合成。 - 在初始化时,自动选择中文语音并设置语速。
- 提供
safe_speak方法,确保在多线程环境下不会因重复调用engine.runAndWait()导致错误。
- 封装
VoskVoiceAssistant类:- 语音助手的核心逻辑实现,负责语音识别、指令处理和语音反馈。
- 关键功能:
- 初始化 Vosk 模型和语音识别器。
- 启动语音监听线程,通过回调函数捕获音频并识别语音。
- 启动终端监听线程,支持用户通过终端输入指令。
- 调用百度 API 处理复杂指令,并返回结果。
- 使用队列和线程锁,确保任务分发的线程安全性。
(2)关键函数与机制
- 语音识别(
_audio_callback方法):- 利用
sounddevice捕获实时音频流,将其转换为字节数据传递给 Vosk 识别器。 - 识别结果通过 JSON 格式解析,检测是否包含唤醒词,若检测到则向任务队列添加“唤醒”任务。
- 利用
- 语音指令处理(
_process_command方法):- 从任务队列中获取“唤醒”任务后,开始录音,并将音频数据保存至缓冲区。
- 在录音结束后,将音频提交给 Vosk 进行识别,解析用户指令。
- 调用
_call_wenxin方法,与百度 API 交互,获取响应结果并用语音播报。
- 百度 API 调用(
_call_wenxin方法):- 获取 Access Token:
- 通过 API Key 和 Secret Key,向百度 OAuth 服务请求
access_token。
- 通过 API Key 和 Secret Key,向百度 OAuth 服务请求
- 调用文心一言 API:
- 构建包含用户指令的请求数据,发送给百度 API。
- 接收响应数据并解析结果,返回给用户。
- 异常处理:
- 捕获网络请求或 API 响应中的异常,返回错误信息。
- 获取 Access Token:
- 终端指令监听(
_terminal_input_listener方法):- 独立线程运行,监听用户终端输入。
- 若输入包含唤醒词或特定指令(如
exit),向任务队列添加相应任务。
- 主运行循环(
run方法):- 启动语音监听线程和终端监听线程。
- 从任务队列中获取任务,根据任务类型(如“唤醒”或“关闭”)执行相应操作。
- 支持通过
Ctrl+C手动退出程序,并确保资源清理。
(3)辅助功能
- 语音唤醒检测(
_wake_detection方法):- 使用
sounddevice的InputStream实现实时音频流监听。 - 基于 Vosk 的识别结果,检测是否说出唤醒词。
- 使用
- 多线程管理:
- 使用
threading.Thread启动语音监听和终端监听线程。 - 使用
queue.Queue管理任务分发,确保线程间通信安全。 - 使用
threading.Lock避免多线程环境下对共享资源(如音频缓冲区、识别器)的冲突。
- 使用
3、配置与依赖
1、Vosk 模型
需要下载 Vosk 的中文离线模型(vosk-model-cn-0.22)并指定路径。
配置路径:VOSK_MODEL_PATH。
2、百度 API 凭据
需提供百度 AI 平台的 API Key 和 Secret Key。
在 _call_wenxin 方法中替换为用户自己的凭据。
这里需要注意的是Vosk模型如果不会”科学上网“的话直接下载的话会非常慢甚至会产生报错信息,导致下载失败,当然可以采用一些镜像源比如清华镜像源或者阿里镜像源 但是貌似并没有这个模型,如果不着急的话可以在官网进行下载
官网地址:https://alphacephei.com/vosk/models/vosk-model-cn-0.22.zip
进入下载即可 比较慢
这里直接分享一下百度网盘的链接:
链接: https://pan.baidu.com/s/1D0PKmMtlVI574EP0HO5fDQ?pwd=naxx 提取码: naxx 复制这段内容后打开百度网盘手机App,操作更方便哦
简单介绍一下Vosk模型吧
Vosk模型能够支持连续的语音识别,并广泛适用于多种语言和平台,包括Linux、Windows和Android等。该模型的工作原理主要基于深度神经网络(DNN),通过对大量语音数据进行训练,学习从语音信号中提取有效特征的能力。在识别阶段,Vosk模型将输入的语音信号转换为高维向量,与预训练的声学模型进行匹配,从而确定最可能的单词序列。
Vosk模型的优点在于它是一款轻量级、开源的语音识别工具,支持离线识别,无需依赖云端服务,有效保护了用户隐私。同时,它具备多语言识别能力,适应性强,可以在多种平台和设备上运行,为开发者提供了极大的便利。此外,Vosk模型还具有良好的实时性和准确性,能够满足大多数语音识别应用的需求。
3、核心依赖库
vosk:离线语音识别。sounddevice:音频流捕获。pyttsx3:语音合成。requests:与百度 API 通信。numpy:处理音频数据。json、queue、threading等 Python 内置库。
安装主要有两种方法
第一种:
文件里面单击设置
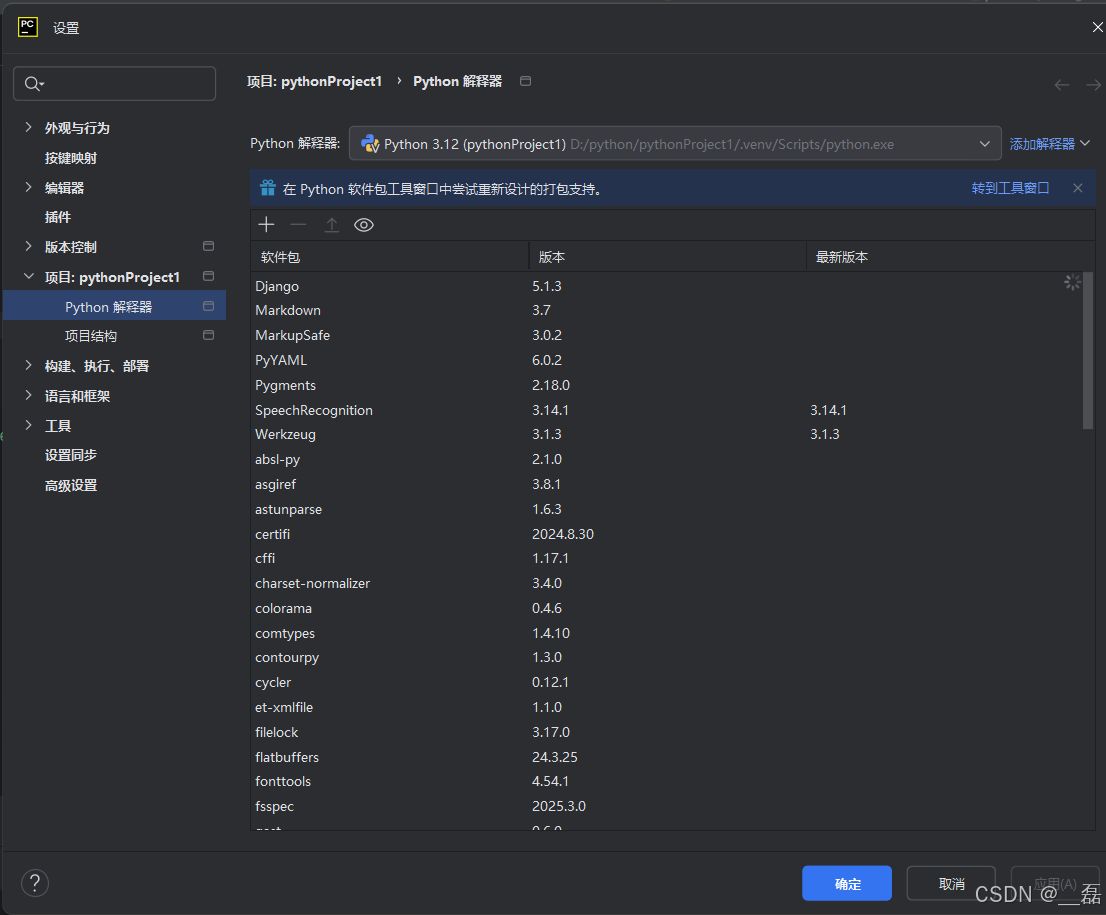
选择Python解释器,点+号进行搜索后下载即可
第二种:
在终端中下载:
点击终端之后输入如下命令:pip install vosk sounddevice pyttsx3 requests numpy
如果下载不了的话 可以采用一些镜像源比如 清华镜像源命令如下:pip install vosk sounddevice pyttsx3 requests numpy -i https://pypi.tuna.tsinghua.edu.cn/simple
安装好后 对于本项目的配置与依赖就已经完成啦,下面就是代码的编写
三、核心代码编写及分析
在确保环境等配置无误后,就可以进行代码编写了
1. 导入模块
代码首先导入了必要的Python模块,包括sys、queue、json、os、threading、time、requests、sounddevice、numpy、vosk和pyttsx3等,用于实现语音识别、语音合成、线程管理、音频处理等功能。
2. 用户配置区域
VOSK_MODEL_PATH:指定Vosk语音识别模型的路径。WAKE_WORDS:定义唤醒语音助手的关键词列表。
3. 系统参数
SAMPLE_RATE:音频采样率。CHUNK_SIZE:音频处理块大小。RECORD_TIMEOUT:录音超时时间。
4. 线程安全语音合成类(ThreadSafeTTS)
- 封装了
pyttsx3语音合成库,确保在多线程环境下安全地输出语音。 _find_chinese_voice方法:配置中文语音。safe_speak方法:线程安全地输出语音。
5. 语音助手类(VoskVoiceAssistant)
_init_vosk方法:初始化Vosk语音识别模型。_audio_callback方法:音频回调函数,用于接收音频数据并进行语音识别。_wake_detection方法:启动语音唤醒检测线程,持续监听音频输入。_process_command方法:处理语音指令,将识别结果通过百度文心一言API进行处理,并输出响应。_call_wenxin方法:调用百度文心一言API,获取API响应。speak方法:输出语音响应。run方法:启动语音助手,包括语音唤醒检测线程和终端输入监听线程。
6. 终端输入监听功能
_terminal_input_listener方法:独立线程监听终端输入,支持通过终端输入指令唤醒语音助手或关闭程序。
7. 主程序入口
- 初始化语音助手并启动。
- 捕获异常并输出错误信息。
8、功能概述
- 语音助手支持通过语音或终端输入指令进行交互。
- 使用Vosk进行离线语音识别,支持中文。
- 使用百度文心一言API进行自然语言处理和响应生成。
- 支持多线程,确保语音合成和指令处理不会阻塞其他功能。
9、源代码展示
import sys
import queue
import json
import os
import threading
import time
import requests
import sounddevice as sd
import numpy as np
from vosk import Model, KaldiRecognizer
import pyttsx3
# ----------------- 用户配置区域 -----------------
VOSK_MODEL_PATH = "D:\\python\\pythonProject1\\.venv\\vosk-model-cn-0.22"
WAKE_WORDS = ["小智小智", "你好助手"]
# ----------------- 系统参数 -----------------
SAMPLE_RATE = 16000
CHUNK_SIZE = 8000
RECORD_TIMEOUT = 10
class ThreadSafeTTS:
"""线程安全的语音合成封装类"""
def __init__(self):
self.engine = pyttsx3.init()
self.lock = threading.Lock()
self._find_chinese_voice()
def _find_chinese_voice(self):
"""配置中文语音"""
for voice in self.engine.getProperty('voices'):
if 'chinese' in voice.name.lower():
self.engine.setProperty('voice', voice.id)
self.engine.setProperty('rate', 160)
break
def safe_speak(self, text):
"""线程安全的语音输出"""
with self.lock:
try:
# 确保事件循环未运行
if not self.engine._inLoop:
self.engine.say(text)
self.engine.runAndWait()
except Exception as e:
print(f"❌ 语音合成失败: {str(e)}")
class VoskVoiceAssistant:
def __init__(self):
self._init_vosk()
self.tts = ThreadSafeTTS() #使用线程安全封装
self.task_queue = queue.Queue()
self.is_listening = True
self.recording = False
self.audio_buffer = np.array([], dtype=np.int16)
self.recognizer_lock = threading.Lock()
self.recording_event = threading.Event() # 添加录音状态事件
self.processing_lock = threading.Lock()
# 新增终端输入线程控制
self.terminal_running = True
def _init_vosk(self):
if not os.path.exists(VOSK_MODEL_PATH):
raise FileNotFoundError(f"模型未找到:{VOSK_MODEL_PATH}")
self.model = Model(VOSK_MODEL_PATH)
self.recognizer = KaldiRecognizer(self.model, SAMPLE_RATE)
self.recognizer.SetWords(True)
def _init_tts(self):
self.engine = pyttsx3.init()
for voice in self.engine.getProperty('voices'):
if 'chinese' in voice.name.lower():
self.engine.setProperty('voice', voice.id)
self.engine.setProperty('rate', 160)
break
# 新增终端输入监听功能
def _terminal_input_listener(self):
"""独立线程监听终端输入"""
print("\n🔧 终端唤醒功能已启用(输入 '你好小智' 唤醒)")
while self.terminal_running:
try:
# 使用超时机制避免阻塞
user_input = input("请输入指令(或输入 exit 退出):\n").strip()
if user_input.lower() == "exit":
self.task_queue.put("shutdown")
elif "你好小智" in user_input:
print("🖥️ 终端唤醒成功!")
self.task_queue.put("wake")
#self._process_command()
#self.speak("请说出你的指令: ")
except Exception as e:
print(f"终端输入异常: {str(e)}")
def _audio_callback(self, indata, frames, time_info, status):
if status:
#print(f"音频异常: {status}")
return
audio_data = indata.astype(np.int16).tobytes()
with self.recognizer_lock:
if self.recognizer.AcceptWaveform(audio_data):
result = json.loads(self.recognizer.Result())
text = result.get('text', '')
if any(word in text for word in WAKE_WORDS):
self.task_queue.put("wake")
if self.recording_event.is_set():
self.audio_buffer = np.append(self.audio_buffer, indata)
def _wake_detection(self):
print("🟢 语音唤醒检测已启动")
with sd.InputStream(
samplerate=SAMPLE_RATE,
blocksize=CHUNK_SIZE,
dtype=np.float32,
channels=1,
callback=self._audio_callback
):
while self.is_listening:
time.sleep(0.1)
def _process_command(self):
try:
with self.processing_lock: #防止重复处理
self.audio_buffer = np.array([], dtype=np.float32)
self.recording_event.set()
print("⏺️ 请说出您的指令...")
start_time = time.time()
while time.time() - start_time < RECORD_TIMEOUT:
time.sleep(0.1)
# 停止录音并处理数据
self.recording_event.clear()
# time.sleep(0.5) # 等待最后一段数据写入
# self.recording = False
audio_data = (self.audio_buffer * 32767).astype(np.int16).tobytes()
with self.recognizer_lock:
self.recognizer.Reset()
self.recognizer.AcceptWaveform(audio_data)
result = json.loads(self.recognizer.Result())
text = result.get('text', '')
if text:
print(f"👤 语音指令: {text}")
response = self._call_wenxin(text)
self.speak(response)
# 添加结束提示
print("🟢 您可以继续提问")
self.speak("您可以继续提问")
except Exception as e:
print(f"❌ 处理失败: {str(e)}")
finally:
# 确保清空缓冲区
self.audio_buffer = np.array([], dtype=np.float32)
self.recognizer.Reset()
self.recording_event.clear()
def _call_wenxin(self, prompt):
api_key = "" # 替换为你的API Key
api_secret = "" # 替换为你的Secret Key
try:
# 首先获取 access_token
# 在函数内部直接获取 access_token
url = "https://aip.baidubce.com/oauth/2.0/token"
params = {
'grant_type': 'client_credentials',
'client_id': api_key,
'client_secret': api_secret
}
headers = {
'Content-Type': 'application/json',
'Accept': 'application/json'
}
response = requests.get(url, params=params, headers=headers)
response.raise_for_status() # 确保请求成功
response_data = response.json()
if 'access_token' in response_data:
access_token = response_data['access_token']
else:
raise Exception(
f"Failed to retrieve access token: {response_data.get('error_description', 'Unknown error')}")
# 构建请求 URL
url = f"https://aip.baidubce.com/rpc/2.0/ai_custom/v1/wenxinworkshop/chat/ernie_speed?access_token={access_token}"
# 构建请求 payload
payload = {
"messages": [ {"role": "user", "content": prompt} ]
}
# 发送 POST 请求
response = requests.post(
url,
json=payload,
timeout=30
)
# 检查响应状态并解析 JSON 数据
response.raise_for_status()
data = response.json()
# 根据百度文心 API 的响应格式,提取需要的数据
# 这里假设响应中有一个 'result' 键,且其中包含我们需要的内容
# 具体结构需参考百度文心 API 文档
if 'result' in data:
# 具体结构需根据实际情况调整
return data['result']
else:
return f"Unexpected response format: {data}"
except requests.exceptions.RequestException as e:
return f"请求错误:{str(e)}"
except Exception as e:
return f"发生错误:{str(e)}"
def speak(self, text):
print(f"📢 助理:{text}")
self.tts.safe_speak(text)
#self.engine.say(text)
#self.engine.runAndWait()
def run(self):
# 启动语音检测线程
audio_thread = threading.Thread(target=self._wake_detection, daemon=True)
audio_thread.start()
# 启动终端输入线程
terminal_thread = threading.Thread(target=self._terminal_input_listener, daemon=True)
terminal_thread.start()
try:
while self.is_listening:
try:
if not self.task_queue.empty():
task = self.task_queue.get()
if task == "wake":
self.speak("在的,请说")
command_thread = threading.Thread(target=self._process_command)
command_thread.start()
elif task == "shutdown":
print("\n🛑 收到关闭指令...")
break
except queue.Empty:
continue
# time.sleep(0.1)
except KeyboardInterrupt:
print("\n🛑 正在关闭...")
finally:
self.is_listening = False
self.terminal_running = False
if terminal_thread.is_alive():
terminal_thread.join(timeout=1)
if __name__ == "__main__":
try:
print("🚀 语音助手启动中...")
assistant = VoskVoiceAssistant()
#assistant._process_command()
assistant.run()
except Exception as e:
print(f"💥 致命错误: {str(e)}")
sys.exit(1)四、项目成果展示
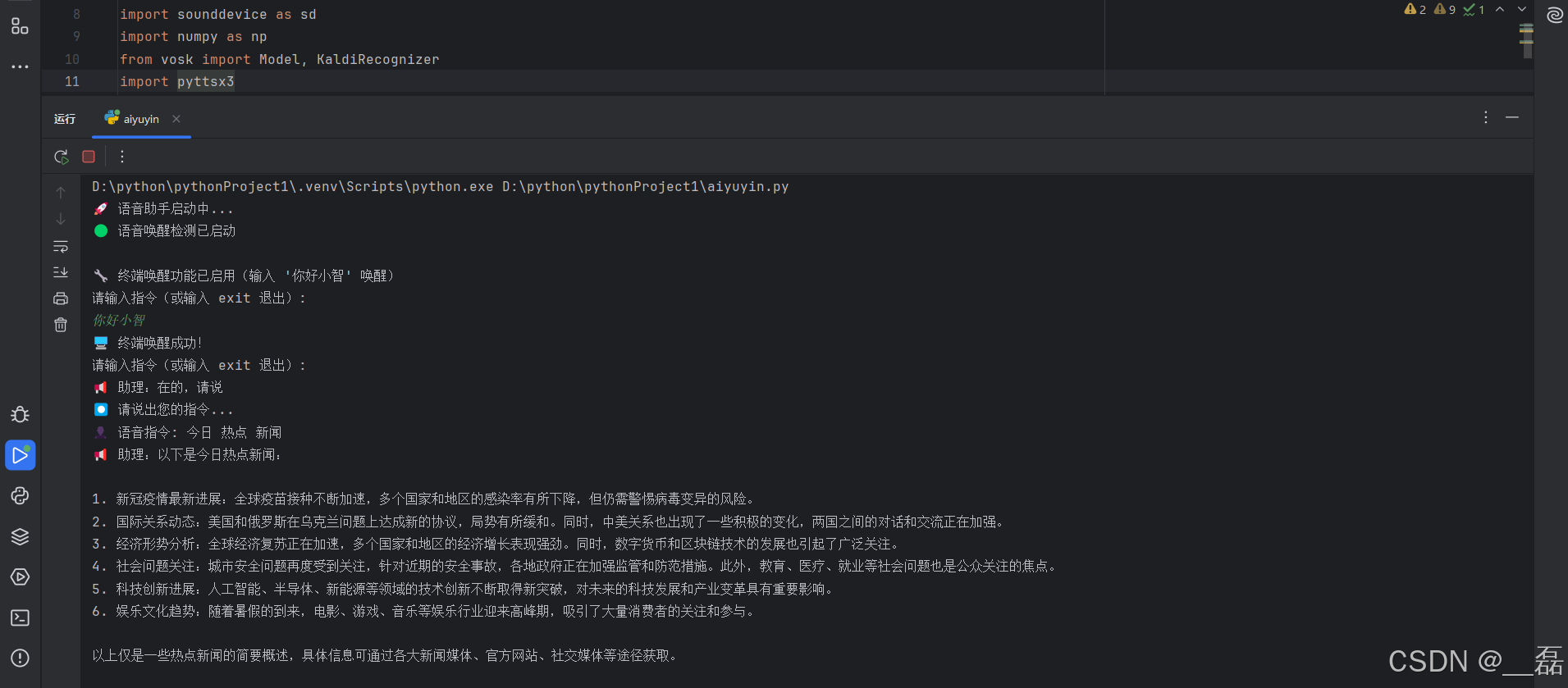
可以看到在进行运行时在出现请说出你的指令后 进行说话 会对对话进行识别并作出响应
五、项目总结
一、项目背景与目标
本项目旨在开发一个基于VOSK语音识别和百度文心一言API的语音助手。通过集成语音识别、自然语言处理和语音合成技术,实现用户通过语音指令与助手进行交互,完成特定的任务或获取信息。项目的目标是提供一个便捷、智能的语音交互体验,满足用户在日常生活和工作中的多样化需求。
二、项目实施过程
-
需求分析与规划
- 分析了市场上现有语音助手的功能和特点,结合用户需求,确定了项目的核心功能和实现方案。
- 制定了详细的项目计划,包括技术选型、模块划分、开发进度等。
-
技术选型与实现
- 选用了VOSK作为语音识别引擎,实现了高精度的语音识别功能。
- 集成了百度文心一言API,利用其自然语言处理能力,实现了对用户指令的理解和响应。
- 使用了pyttsx3库进行语音合成,实现了流畅的语音输出。
- 通过多线程技术,实现了语音检测、终端输入监听和命令处理的并行运行,提高了系统的响应速度和稳定性。
- 测试与优化
- 进行了全面的测试,包括功能测试、性能测试和稳定性测试,确保了系统的各项功能正常运行。
- 针对测试中发现的问题,进行了及时的优化和调整,提高了系统的性能和用户体验。
三、项目成果与亮点
- 成果
- 成功开发了一个基于VOSK和百度文心一言的语音助手,实现了语音识别、自然语言处理和语音合成的全流程。
- 助手能够准确识别用户的语音指令,并给出相应的响应,满足了用户的多样化需求。
- 通过多线程技术,实现了多个功能的并行运行,提高了系统的效率和稳定性。
- 亮点
- 高精度语音识别:利用VOSK引擎,实现了高精度的语音识别功能,能够准确识别用户的语音指令。
- 智能自然语言处理:通过集成百度文心一言API,实现了对用户指令的智能理解和响应,提高了助手的智能化水平。
- 流畅语音合成:使用pyttsx3库进行语音合成,实现了流畅的语音输出,提高了用户体验。
- 多线程并行运行:通过多线程技术,实现了语音检测、终端输入监听和命令处理的并行运行,提高了系统的响应速度和稳定性。
本项目任然还有一些缺陷,后续会进行优化 今天的智能语音助手就分享到这里啦 制作不易 喜欢的话可以点赞+关注哦~

















 1712
1712

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









