







Qwen3 技术总结
Qwen3 技术总结
简介
阿里通义 Qwen3 系列大模型已正式发布。此次开源包含两大类模型:混合专家模型 (MoE) 和密集模型 (Dense)。
MoE 模型
- Qwen3-235B-A22B: 大型 MoE 模型,总参数量 2350 亿,激活参数量 220 亿。
- Qwen3-30B-A3B: 小型 MoE 模型,总参数量 300 亿,激活参数量 30 亿。
核心看点:旗舰模型 Qwen3-235B-A22B 在代码、数学及通用能力等基准测试中表现卓越,可与 DeepSeek-R1、o1、o3-mini、Grok-3 及 Gemini-2.5-Pro 等业界顶尖模型媲美。小型 MoE 模型 Qwen3-30B-A3B 仅需激活 Qwen1.5-32B (QwQ-32B) 约 10% 的参数即可实现更优性能。
MoE 模型参数详情:
| 模型 | 层数 | 头部 (Q / KV) | # 专家 (总数 / 已激活) | 上下文长度 |
|---|---|---|---|---|
| Qwen3-30B-A3B | 48 | 32 / 4 | 128 / 8 | 128K |
| Qwen3-235B-A22B | 94 | 64 / 4 | 128 / 8 | 128K |
Dense 模型
本次开源的密集模型包括:
- Qwen3-32B
- Qwen3-14B
- Qwen3-8B
- Qwen3-4B
- Qwen3-1.7B
- Qwen3-0.6B
核心看点:即便是 Qwen3-4B这样的小型密集模型,其性能也能与 Qwen2.5-72B-Instruct 相匹敌。
Dense 模型参数详情:
| 模型 | 层数 | 头部 (Q / KV) | 嵌入绑定 | 上下文长度 |
|---|---|---|---|---|
| 千问3-0.6B | 28 | 16 / 8 | 是的 | 32K |
| 千问3-1.7B | 28 | 16 / 8 | 是的 | 32K |
| 千问3-4B | 36 | 32 / 8 | 是的 | 32K |
| 千问3-8B | 36 | 32 / 8 | 否 | 128K |
| 千问3-14B | 40 | 40 / 8 | 否 | 128K |
| 通义千问3-32B | 64 | 64 / 8 | 否 | 128K |
混合思维模式
Qwen3 创新性地提供了两种智能模式供用户选择:
- 思考模式 (Thinking Mode): 如同经验丰富的教授,进行深思熟虑和逐步推理后给出答案,尤其擅长处理复杂和疑难问题。
- 非思考模式 (Non-thinking Mode): 追求极致响应速度,如同秒回小能手,非常适合需要快速直接答案的简单问题。
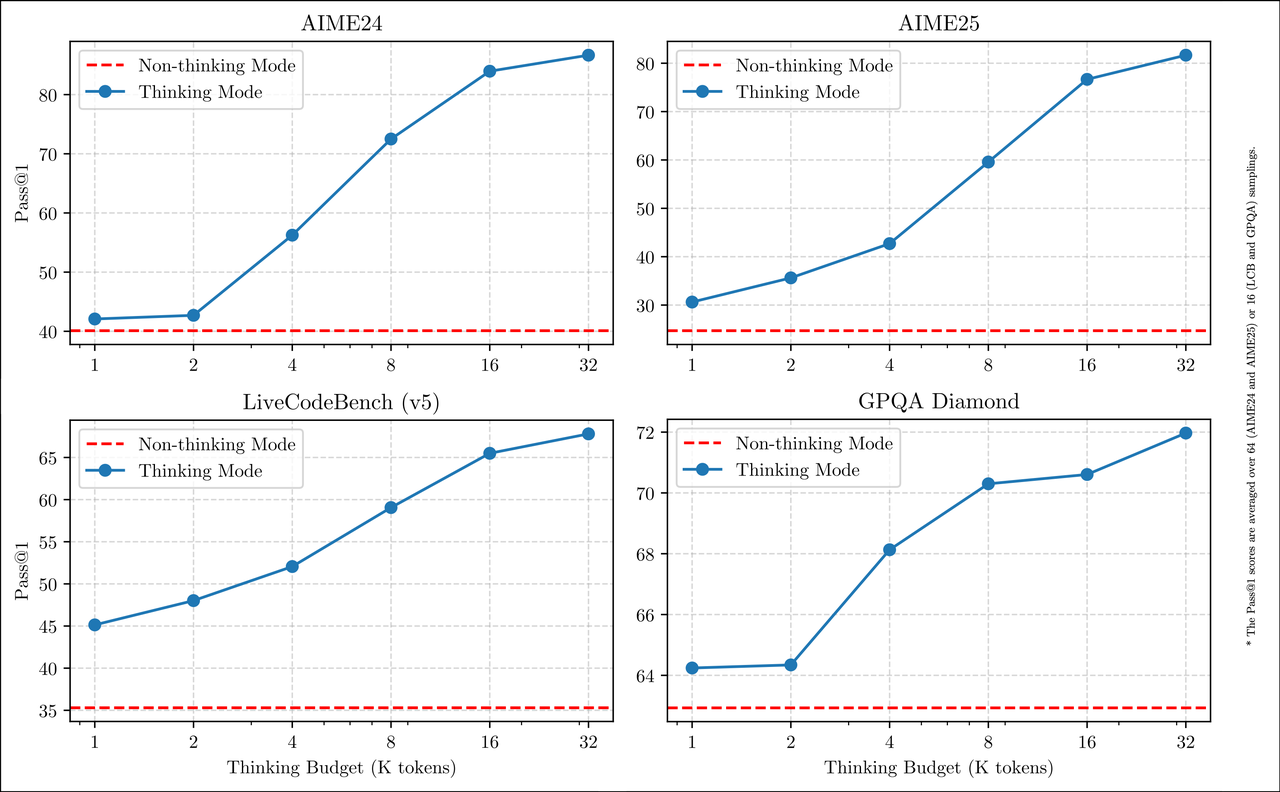
性能对比图:
(图片展示了在 AIME24, AIME25, LiveCodeBench (v5), 和 GPQA Diamond 等基准测试中,思考模式随着“思考预算 (K tokens)”的增加,性能显著优于非思考模式。图片来源:)
Agent 能力
Qwen3 特别强化了其 Agent 能力和代码处理能力,并加强了对模型上下文协议 (MCP) 的支持。
- 基于 MCP 协议的工具调用框架:实现了更标准化的工具调用。
- 自主调用外部 API 与执行代码能力:赋予模型更强的自主行动和问题解决能力。
- BFCL 评测新高:在 BFCL(一个评估大型语言模型工具调用能力的基准)评测中,Qwen3 创下了 70.8 分的新纪录,超越了 Gemini-2.5-Pro 和 OpenAI-o1
榜单测评
Qwen3 系列模型在多个权威基准测试中均取得了优异成绩。
(以下为主要模型的测评数据概览,详细数据请参照原文档中的图片。图片来源:)
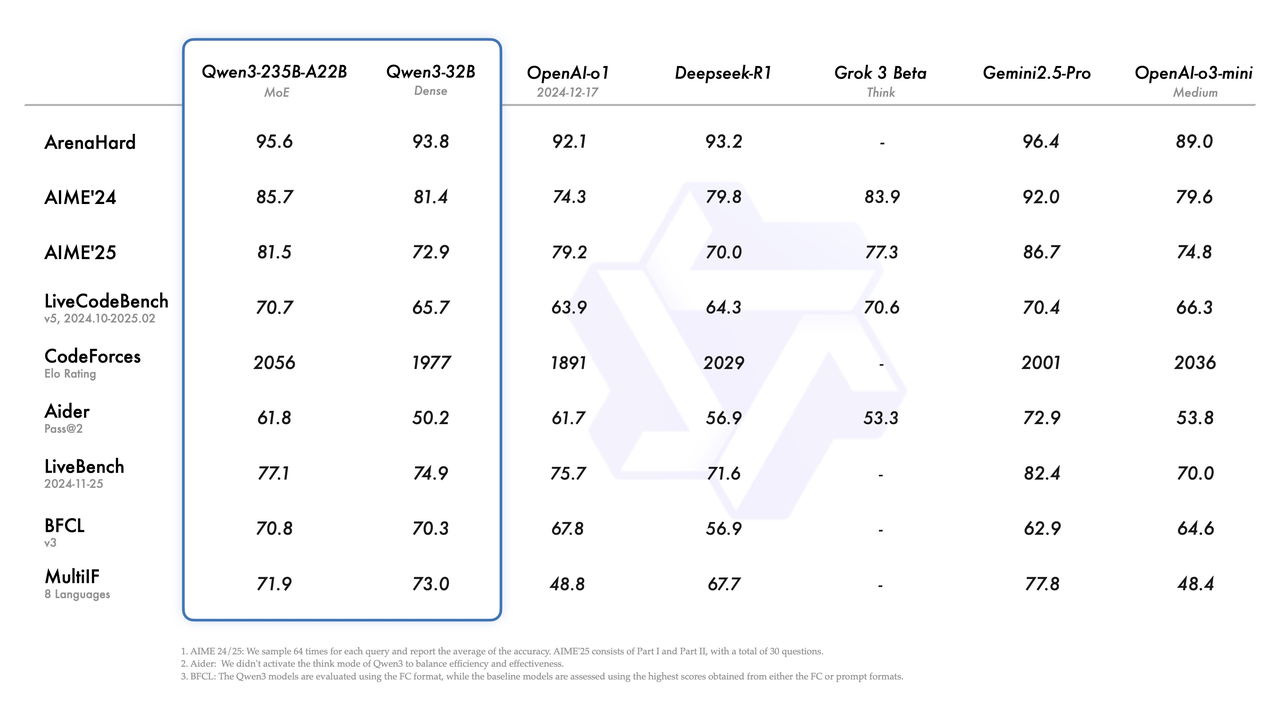
Qwen3-235B-A22B 与 Qwen3-32B 对比 OpenAI-o1, Deepseek-R1, Grok 3 Beta, Gemini2.5-Pro, OpenAI-o3-mini
(图片展示了在 Arenahard, AIME’24, AIME’25, LiveCodeBench, CodeForces, Aider, LiveBench, BFCL, MultiH 等基准上的得分对比。)
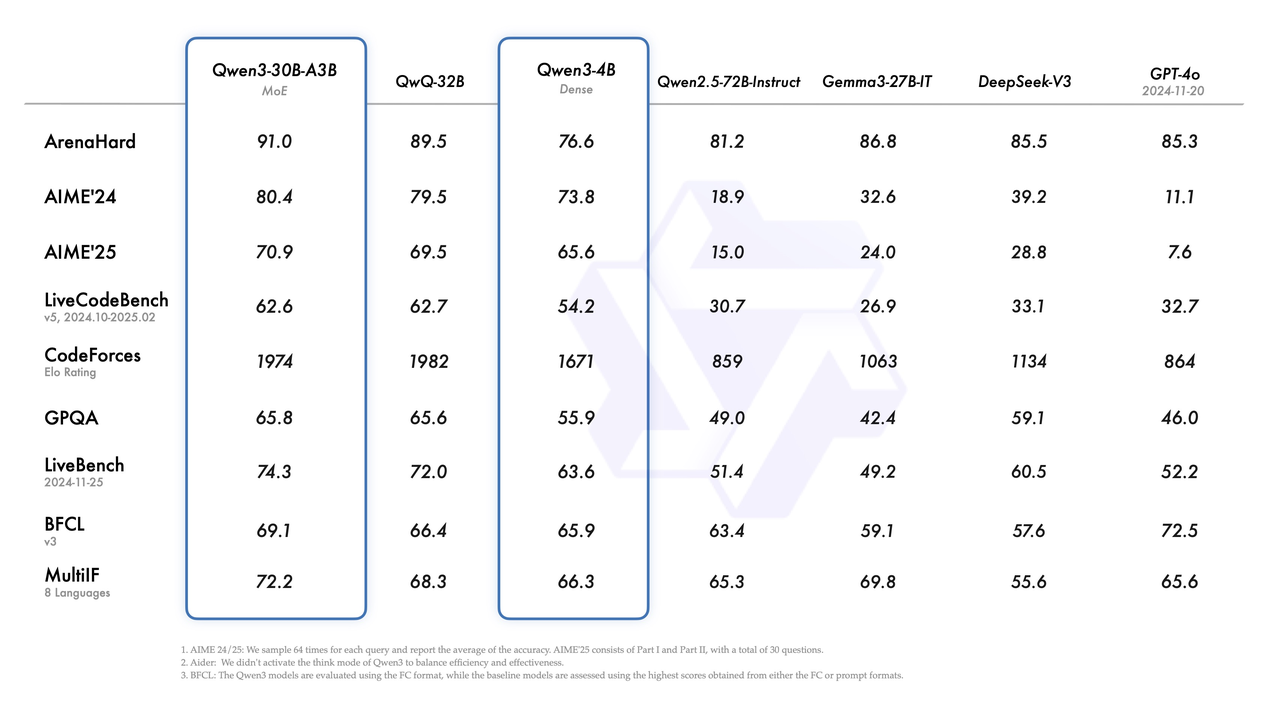
Qwen3-30B-A3B (MoE), QwQ-32B, Qwen3-4B (Dense) 对比 Qwen2.5-72B-Instruct, Gemma3-27B-IT, DeepSeek V3, GPT-Jo
(图片展示了在 Arenahard, AIME’24, AIME’25, LiveCodeBench, CodeForces, GPQA, LiveBench, BFCL, MultiH 等基准上的得分对比。)
测评备注:
- AIME’24 & '25: 复杂推理和查询的平均准确率,AIME’25 在 Tool use 和 RAG 上测试 GK 问题。
- Aider: 测试 Qwen 在代码编辑和生成方面的能力。
- BFCL: Qwen 模型进行采样,并与使用最高分(来自零样本或少样本提示)进行评估的其他模型进行比较。
训练细节
数据策略
Qwen3 的训练采用了超大规模、多语种的数据集,具体特点如下:
- 总数据量:高达 36 万亿 tokens,是 Qwen2.5 的两倍。
- 领域强化:显著强化了 STEM(科学、技术、工程、数学)领域与代码数据的占比。
- STEM 领域具体包括:
- Science (科学):如物理、化学、生物等自然科学。
- Technology (技术):如信息技术、软件开发等。
- Engineering (工程):如电子、机械、土木等工程学科。
- Mathematics (数学):如代数、统计、计算等数学领域。
- STEM 领域具体包括:
- 数据增强:引入了模型辅助的数据增强技术。
- 长文本支持:使用了高质量的长文本数据,将上下文窗口扩展至 32K。
三阶段预训练流程
- 阶段一 (S1):基础能力构建
- 使用 30 万亿 tokens 进行初步预训练。
- 目标:建立通用的语言理解与生成能力。
- 支持上下文窗口长度:4K。
- 阶段二 (S2):专业能力强化
- 追加 5 万亿 tokens 继续训练。
- 目标:大量引入 STEM 和代码相关数据,强化模型在专业领域的理解与表达能力。
- 阶段三 (S3):长文本能力优化
- 采用高质量长文本数据进行训练。
- 目标:上下文窗口扩展至 32K,显著提升长文档处理和推理能力。
四阶段强化学习流程
(图片展示了 Frontier Models (如 Qwen3-235B-A22B, Qwen3-32B) 和 Lightweight Models (如 Qwen3-30B-A3B, Qwen3-14B/8B/4B 等) 的不同强化学习路径。图片来源:)
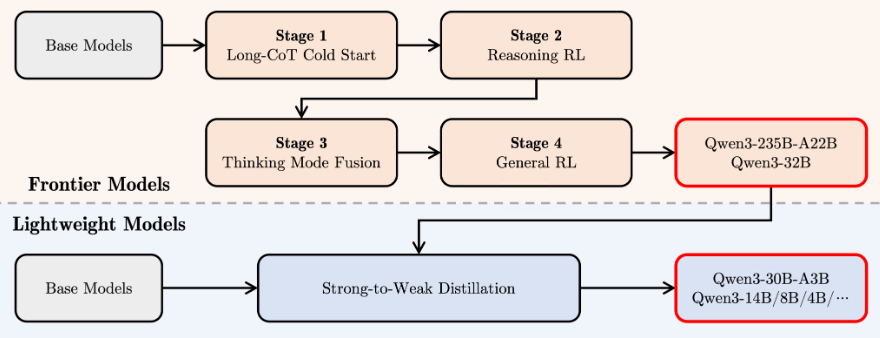
针对 Frontier Models (前沿模型) 的流程:
- 阶段1:长推理链冷启动 (Long-CoT Cold Start)
- 在复杂任务(如数学、代码、逻辑推理)中微调长推理链条。
- 目标:建立模型对复杂因果关系的基本理解。
- 阶段2:推理强化学习 (Reasoning RL)
- 基于规则的奖励机制。
- 目标:强化模型的推理深度与探索能力。
- 阶段3:思考模式融合 (Thinking Mode Fusion)
- 融合“思考”模式与“快速”响应模式。
- 目标:打通推理链条与即时响应路径
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











