






DeepSeek-V3 技术要点解析
DeepSeek-V3 模型解析
项目地址: https://github.com/deepseek-ai/DeepSeek-V3
论文链接: https://github.com/deepseek-ai/DeepSeek-V3/blob/main/DeepSeek_V3.pdf
简介
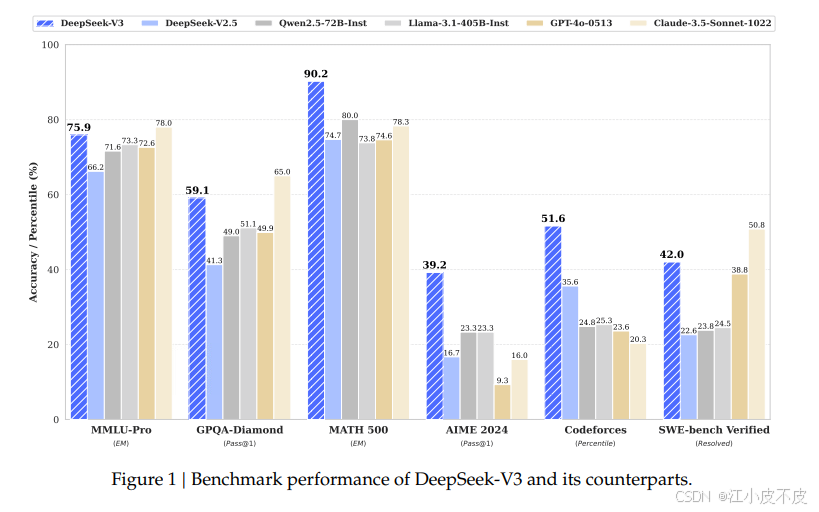
DeepSeek-V3 是一个大规模稀疏专家混合(MoE)模型,拥有高达 6710 亿个参数,其中每个 token 激活 37 亿个参数。
它采用多任务注意混合架构(MLA),相较于 DeepSeek-V2 显著提高了推理效率。
此外,DeepSeek-V3 引入了去随机负载平衡的负载平衡策略和 token 预测机制优化,以提高模型的鲁棒性和稳定性。
DeepSeek-V3的预训练阶段在不到两个月的时间里就完成了,花费了 2664K GPU(H800 GPU)小时。结合 119K GPU 小时(用于上下文长度扩展)和 5K GPU 小时(用于后期训练),DeepSeek-V3 的完整训练成本仅为 2.788M GPU 小时。

模型的主要特点
架构创新
多头潜在注意力(MLA): 通过低秩联合压缩机制,减少推理过程中的Key-Value缓存需求,提高了推理效率,同时保持性能不下降。
无辅助损失的负载均衡策略: 采用动态调整路由偏置的方式,解决专家负载不均问题,避免因使用辅助损失而引发的性能退化。
多Token预测(MTP)训练目标: 相比传统的单Token预测,MTP显著提升了模型在多个任务上的表现,并为推测性解码等推理优化提供了支持。
训练框架上的优化措施
FP8 混合精度训练:
- 支持FP8精度的计算和存储,大幅降低了训练过程中的GPU内存需求和存储带宽压力。
- 是首次在如此大规模模型上成功验证FP8训练有效性。
DualPipe 算法:
- 实现计算与通信的重叠,减少了分布式训练中因通信延迟造成的效率损失。
- 支持更精细的专家划分,并有效减少了全节点通信开销。
高效的跨节点通信:
- 开发高效的全对全(All-to-All)通信内核,充分利用InfiniBand和NVLink带宽,提升通信性能。
内存优化:
- 减少计算过程中的中间状态存储需求,使得训练过程能够不依赖昂贵的张量并行技术而实现更高效率。
预训练和后训练过程
预训练
数据构建:
- 使用14.8万亿高质量、多样化Token,覆盖多种领域以确保模型具备广泛的知识基础。
长上下文扩展:
- 分两阶段完成上下文长度的扩展:
- 第一阶段扩展至32K。
- 第二阶段扩展至128K,显著提升了处理长文档的能力。
训练过程:
- 在FP8混合精度和DualPipe等优化支持下,训练过程中无任何不可恢复的损失激增,表现出极高的稳定性。
后训练
监督微调(Supervised Fine-Tuning, SFT):
- 对模型进行监督训练,使其更好地对齐人类偏好。
强化学习(Reinforcement Learning, RL):
- 引入奖励模型和相对策略优化(Group Relative Policy Optimization),进一步优化模型的生成质量和交互能力。
知识蒸馏:
- 从DeepSeek-R1系列模型中蒸馏长链推理能力,将其整合到DeepSeek-V3中,提升模型的推理和验证能力。
- 训练数据对齐: 使用包含多步骤推理任务的数据,同时训练 DeepSeek-R1 和 DeepSeek-V3。DeepSeek-R1 的推理结果作为目标输出,指导 DeepSeek-V3 学习如何执行类似的多步骤推理任务。
- 概率分布蒸馏: 在每一步推理过程中,DeepSeek-R1 的中间输出(例如,某个步骤的预测概率分布或注意力分布)会被用于指导 DeepSeek-V3 学习这些中间步骤。
- 验证和反思能力的整合: DeepSeek-R1 的推理机制包括"验证"和"反思"的能力,例如评估自己某一步推理是否合理、并在错误时进行调整。通过蒸馏,这种验证和反思能力被引入到 DeepSeek-V3 中。
核心创新点详解
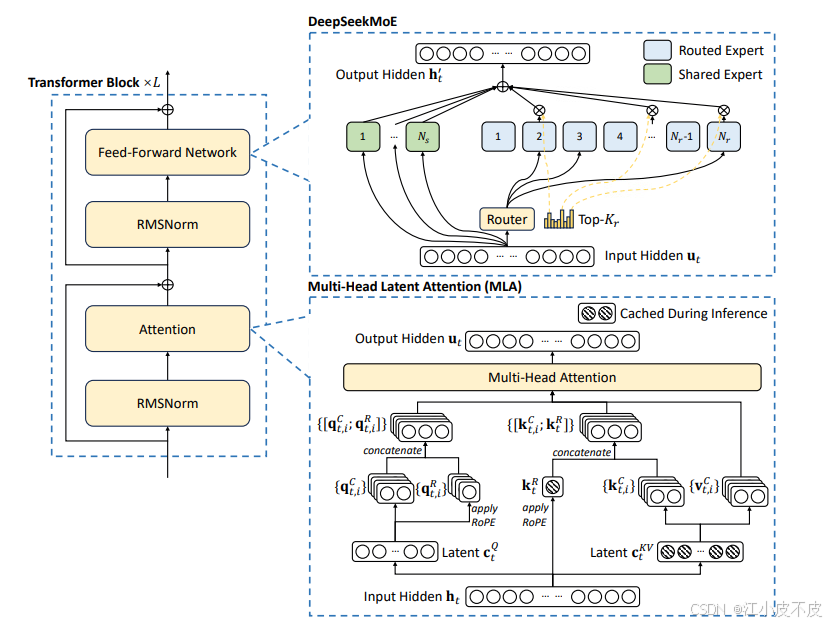
多头潜在注意力(Multi-Head Latent Attention,MLA)
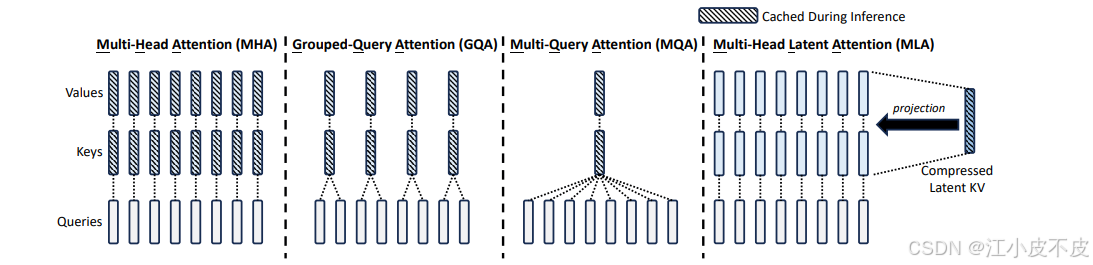
核心思路:
通过低秩联合压缩机制优化传统多头注意力(Multi-Head Attention, MHA)的计算效率和内存占用。推理时仅缓存必要的压缩Key和Value向量(非完整的高维表示),在保持性能的同时显著降低了内存使用。
步骤:
- 通过输入x乘以不同的矩阵参数Wq、Wk、Wv得到不同的QKV向量。
- 在转换到QKV向量时候,将x乘以一个低秩矩阵,得到低阶矩阵表示。
- 再通过一个高阶矩阵来恢复原来的特征空间。由于矩阵是模型的权重参数已经保存,所以只需要保存一个低秩的潜层特征就可以恢复成KV,而不是像之前需要同时缓存KV。
性能优势:
- 与标准多头注意力机制性能相当。
- 推理时内存占用大幅减少,尤其适用于长上下文处理的任务。
无辅助损失的负载均衡策略(Auxiliary-Loss-Free Load Balancing)
专家的负载分配问题
在 MoE 模型中,输入数据通过路由机制被分配给不同的专家(Expert),每个专家是一个独立的神经网络模块,负责处理特定部分的输入数据。然而,负载分配可能出现以下问题:
- 负载不均衡:某些专家处理了大量的数据,而其他专家很少被调用或几乎闲置。
- 计算资源浪费:如果大多数专家没有被充分利用,模型的计算资源就无法高效发挥作用。
- 训练效率下降:负载不均衡会导致某些专家成为瓶颈,影响训练过程的速度和稳定性。
核心思路:
通过动态调整每个专家的路由偏置(bias)来平衡专家负载,避免了传统方法中因使用辅助损失(Auxiliary Loss)来惩罚负载不均而引发的性能下降。
步骤:
- 为每个专家分配一个动态的路由偏置bi,该偏置影响专家选择过程,但不会影响最终计算结果。
- 在每次训练步骤结束后,检测每个专家的负载情况,并根据专家的负载状态调整其偏置:
- 如果某个专家的负载过高,减小该专家的偏置。
- 如果某个专家的负载过低,增加该专家的偏置。
- 使用动态调整机制来平衡负载,避免依赖于辅助损失函数来强制平衡负载。
性能优势:
- 不依赖辅助损失,因此避免了因平衡负载过度惩罚而引发的性能损失。
- 使得专家负载更加均匀,提高了训练效率和推理性能。
多Token预测(Multi-Token Prediction,MTP)
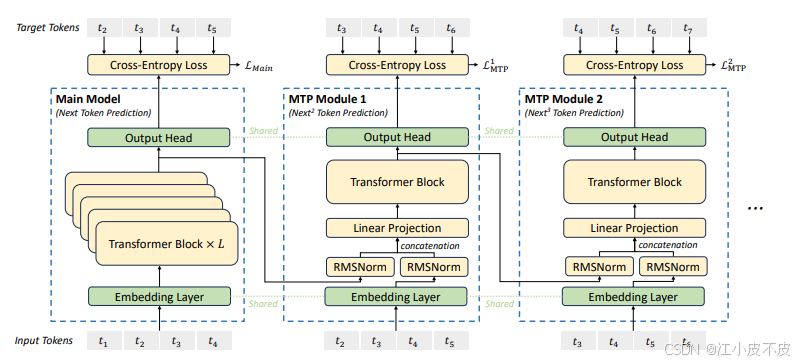
核心思路:
通过扩展传统的单Token预测目标,让模型每次生成多个Token。
每个深度上对每个标记进行预测时保持完整的因果链。MTP 模块通过共享的嵌入层、输出头和变换器块来实现对多个未来标记的预测,旨在提高数据效率并改善未来标记的预测能力。
步骤:
- 在每次训练和推理中,不仅预测当前Token,还需要同时预测后续的多个Token。
- 设计新的损失函数,优化生成多个Token的联合概率分布,而非单一Token的条件概率。
- 训练过程中,通过多Token预测目标来提高模型的上下文理解和生成能力。
性能优势:
- 通过一次性预测多个Token,提高了生成任务的效率。
- 推理时减少了交互计算次数,显著提升了推理速度。
- 增强了模型在联合生成任务中的表现,如代码生成和长文本生成。


















 788
788

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











