




YOLOv8 屏幕手写字母检测训练指南(26个大写+26个小写字母)
本指南将详细讲解如何使用YOLOv8训练一个能够检测屏幕上手写字母(52类:26个大写字母+26个小写字母)的模型。

1. SmartScreen准备工作
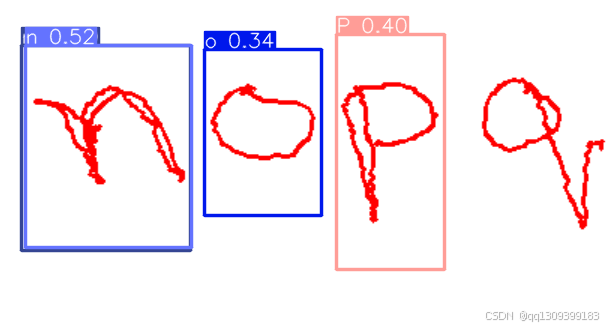
1.1 数据集结构
确保你的数据集结构如下:
/data/
├── train/
│ ├── images/ # 训练集图片
│ └── labels/ # 对应的标签文件
└── valid/
├── images/ # 验证集图片
└── labels/ # 对应的标签文件

1.2 数据标注
- 每个字母应该用边界框标注
- 标签文件应为YOLO格式(.txt文件),每行格式:
class_id x_center y_center width height - 例如字母"A"的标注可能是:
26 0.5 0.5 0.2 0.3(假设大写A的class_id是26)
2. 安装YOLOv8
pip install ultralytics
3. 创建数据集配置文件

创建一个YAML文件(如letters.yaml)配置数据集:
# letters.yaml
path: /content/drive/MyDrive/Major/data # 数据集根目录
train: train/images # 训练集路径
val: valid/images # 验证集路径
# 类别数量和名称
nc: 52
names: [
'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm',
'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z',
'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M',
'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z'
]
4. 训练模型
4.1 基本训练命令
from ultralytics import YOLO
# 加载预训练模型
model = YOLO('yolov8n.pt') # 可以选择yolov8s/m/l/x等不同大小的模型
# 训练模型
results = model.train(
data='letters.yaml',
epochs=100,
batch=16,
imgsz=640,
device='0' # 使用GPU,如果是CPU则设为'cpu'
)
4.2 高级训练配置(推荐)
results = model.train(
data='letters.yaml',
epochs=200,
batch=32,
imgsz=640,
device='0',
optimizer='Adam', # 使用Adam优化器
lr0=0.001, # 初始学习率
lrf=0.01, # 最终学习率 = lr0 * lrf
momentum=0.937, # SGD动量
weight_decay=0.0005, # 权重衰减
warmup_epochs=3, # 热身epochs
warmup_momentum=0.8,
warmup_bias_lr=0.1,
box=7.5, # 框损失权重
cls=0.5, # 分类损失权重
dfl=1.5, # dfl损失权重
fl_gamma=0.0, # 焦点损失gamma
label_smoothing=0.1, # 标签平滑
degrees=10.0, # 图像旋转角度范围
translate=0.1, # 图像平移范围
scale=0.5, # 图像缩放范围
shear=2.0, # 图像剪切范围
perspective=0.0001, # 透视变换
flipud=0.0, # 上下翻转概率
fliplr=0.5, # 左右翻转概率
mosaic=1.0, # mosaic数据增强概率
mixup=0.0, # mixup数据增强概率
copy_paste=0.0 # copy-paste数据增强概率
)
5. 训练过程监控
训练过程中,YOLOv8会自动:
- 在验证集上评估模型性能
- 记录训练指标(损失、mAP等)
- 保存最佳模型和最后模型到
runs/detect/train/目录
你可以使用TensorBoard监控训练过程:
tensorboard --logdir runs/detect/train
6. 模型评估
训练完成后,可以评估模型性能:
# 加载训练好的最佳模型
model = YOLO('runs/detect/train/weights/best.pt')
# 在验证集上评估
metrics = model.val() # 无需参数,会自动使用训练时的配置
print(metrics.box.map) # 打印mAP
7. 使用模型进行预测
# 加载训练好的模型
model = YOLO('runs/detect/train/weights/best.pt')
# 预测单张图片
results = model('path_to_image.jpg')
# 可视化结果
results[0].show()
# 获取预测结果
for result in results:
boxes = result.boxes # 边界框信息
for box in boxes:
class_id = int(box.cls) # 类别ID
confidence = float(box.conf) # 置信度
bbox = box.xywh[0] # 边界框坐标(x_center, y_center, width, height)
print(f"检测到字母: {model.names[class_id]}, 置信度: {confidence:.2f}")
8. 训练技巧与建议
- 数据增强:对于手写字母检测,可以适当增加旋转、平移等增强
- 类别平衡:确保每个字母类别都有足够的样本
- 学习率调整:如果训练不稳定,可以尝试降低学习率
- 模型大小选择:
- yolov8n:轻量级,适合快速测试
- yolov8s/m:平衡速度和精度
- yolov8l/x:高精度,但需要更多计算资源
- 多尺度训练:可以尝试在训练中使用不同输入尺寸
- 早停机制:如果验证集指标不再提升,可以提前停止训练
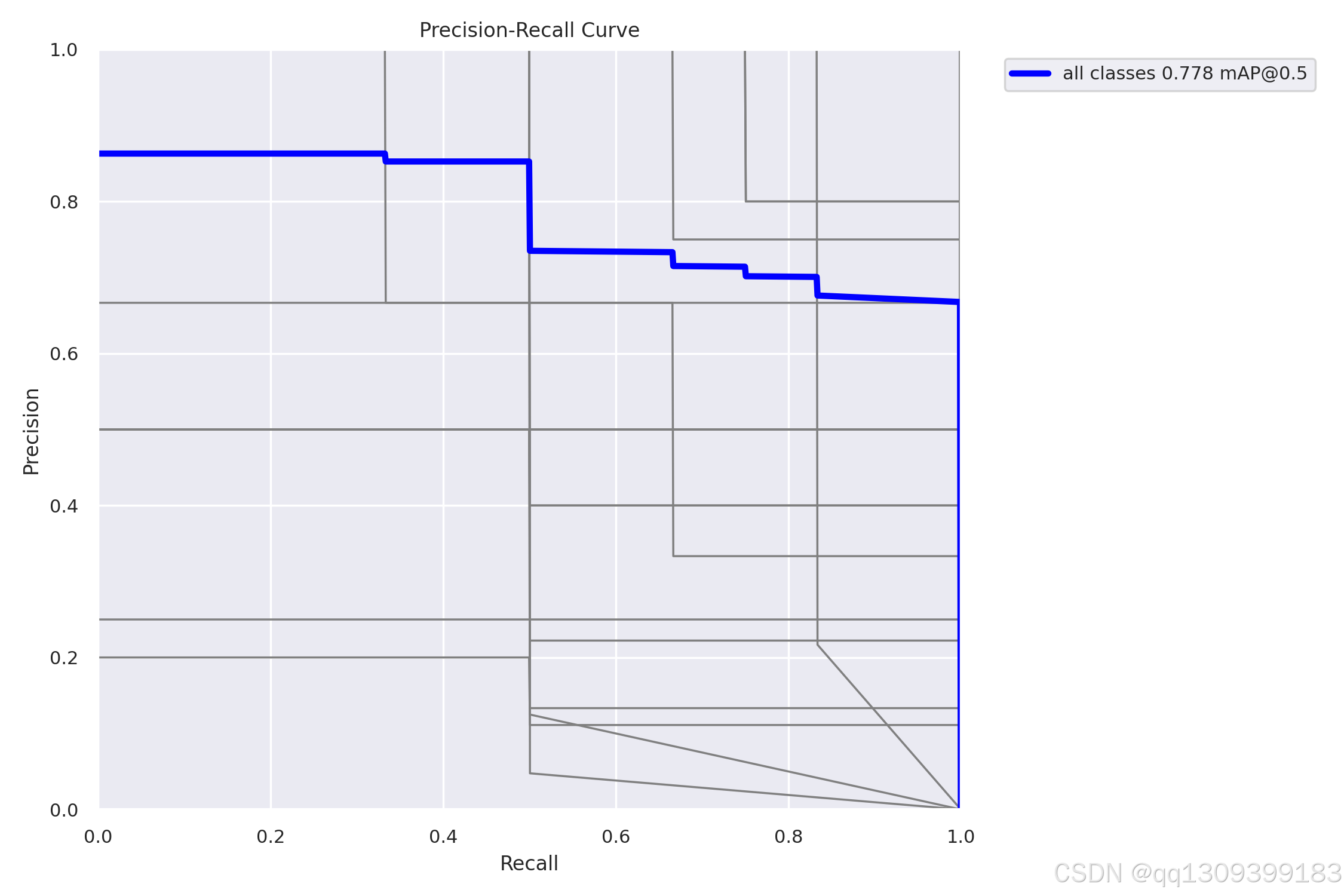
9. 常见问题解决
-
CUDA内存不足:
- 减小batch size
- 减小图像尺寸(imgsz)
-
训练损失不下降:
- 检查学习率是否合适
- 检查数据标注是否正确
- 尝试不同的优化器
-
验证集mAP低:
- 增加训练数据量
- 调整数据增强策略
- 尝试更大的模型
希望这个指南能帮助你成功训练YOLOv8手写字母检测模型!训练过程中可以根据实际表现调整参数。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









