




文章目录
YOLOv11交通标志识别系统:基于TT100K数据集的YOLO格式训练

项目背景
随着智能交通系统和自动驾驶技术的快速发展,交通标志识别成为其中的核心技术之一。高效准确地识别道路上的交通标志,不仅能够帮助车辆实时决策,还能提升道路安全性。交通标志识别的挑战在于标志种类多样、形状复杂、尺寸差异明显,并且在自然场景中可能受到光照变化、遮挡和运动模糊等影响。
YOLO(You Only Look Once)系列算法因其高效的端到端检测能力成为目标检测领域的热门选择,而最新版本的 YOLOv11 提供了更强大的检测性能和实时推理能力,非常适合解决交通标志识别中的复杂场景问题。
本项目旨在利用 YOLOv11 模型对 TT100K(Tsinghua-Tencent 100K)数据集 进行交通标志识别的训练和测试。通过对数据集的预处理、模型训练以及性能优化,构建高效的交通标志识别系统。

TT100K 数据集简介
TT100K 数据集 是一个公开的交通标志数据集,由清华大学和腾讯联合发布。该数据集包含丰富的中国道路场景的交通标志,涵盖了100,000 张高清图片和超过30,000个标注的交通标志实例,并且支持多类别分类。
数据集特点:
- 种类多样:
- 数据集中包括 120 种交通标志类别,涵盖限速、禁行、警示和指示等标志。
- 场景复杂:
- 图片来自自然场景,存在光照变化、遮挡、模糊和远距离小目标等问题。
- 标注精确:
- 数据集提供了每个交通标志的精确位置(边界框)和类别标签。
项目目标
-
构建基于 YOLOv11 的交通标志识别模型:
- 支持对 TT100K 数据集中不同种类的交通标志进行准确检测。
- 能够适应复杂自然场景,提高小目标检测能力。
-
数据预处理与格式转换:
- 将 TT100K 数据集的标注转换为 YOLO 格式,便于模型直接使用。
-
模型训练与优化:
- 使用 TT100K 数据集训练 YOLOv11 模型,达到高精度和高实时性的平衡。
-
测试与评估:
- 在测试集中评估模型性能,计算平均精度(mAP)、检测速度等指标。

数据预处理与格式转换
1. 原始数据格式
TT100K 数据集的标注文件以 JSON 格式提供,描述了每张图片中交通标志的边界框坐标和类别标签。例如:
{
"annotations": [
{
"image_id": "000001.jpg",
"category_id": 1,
"bbox": [50, 60, 200, 220]
},
...
],
"categories": [
{"id": 1, "name": "speed_limit_20"},
{"id": 2, "name": "stop"},
...
]
}
2. 转换为 YOLO 格式
YOLO 格式要求每个标注文件为一行,包含以下内容:
- 类别索引(从 0 开始)
- 边界框中心点坐标(相对于图片宽度和高度归一化)
- 边界框宽度和高度(相对于图片宽度和高度归一化)
转换代码示例:
import json
import os
def convert_to_yolo_format(json_file, output_dir, img_width, img_height):
with open(json_file, 'r') as f:
data = json.load(f)
for annotation in data['annotations']:
image_id = annotation['image_id']
category_id = annotation['category_id'] - 1 # Convert to zero-based index
x_min, y_min, bbox_width, bbox_height = annotation['bbox']
# Convert to YOLO format
x_center = (x_min + bbox_width / 2) / img_width
y_center = (y_min + bbox_height / 2) / img_height
width = bbox_width / img_width
height = bbox_height / img_height
# Write to YOLO format file
output_file = os.path.join(output_dir, f"{image_id.split('.')[0]}.txt")
with open(output_file, 'a') as out_f:
out_f.write(f"{category_id} {x_center} {y_center} {width} {height}\n")
3. 数据划分
将数据集划分为训练集、验证集和测试集,比例为 8:1:1,确保训练数据的多样性,同时保留足够的数据进行模型评估。
模型训练
1. 环境配置
- Python 版本:3.8+
- 依赖库:
- ultralytics(YOLOv11 实现)
- PyTorch
- OpenCV
- 安装依赖:
pip install ultralytics torch opencv-python
2. 下载 YOLOv11 预训练权重
从 YOLO 官方仓库 下载 YOLOv11 的预训练模型权重,放置于 weights 文件夹中。
3. 模型配置文件
编辑 YOLOv11 的模型配置文件 data.yaml,指定数据集路径、类别名称和类别数:
train: /path/to/train/images
val: /path/to/val/images
nc: 120 # Number of classes
names: ["speed_limit_20", "stop", "no_entry", ...] # Class names
4. 运行训练
在终端运行以下命令开始模型训练:
yolo train model=yolov11.pt data=data.yaml epochs=100 imgsz=640 batch=16 device=0
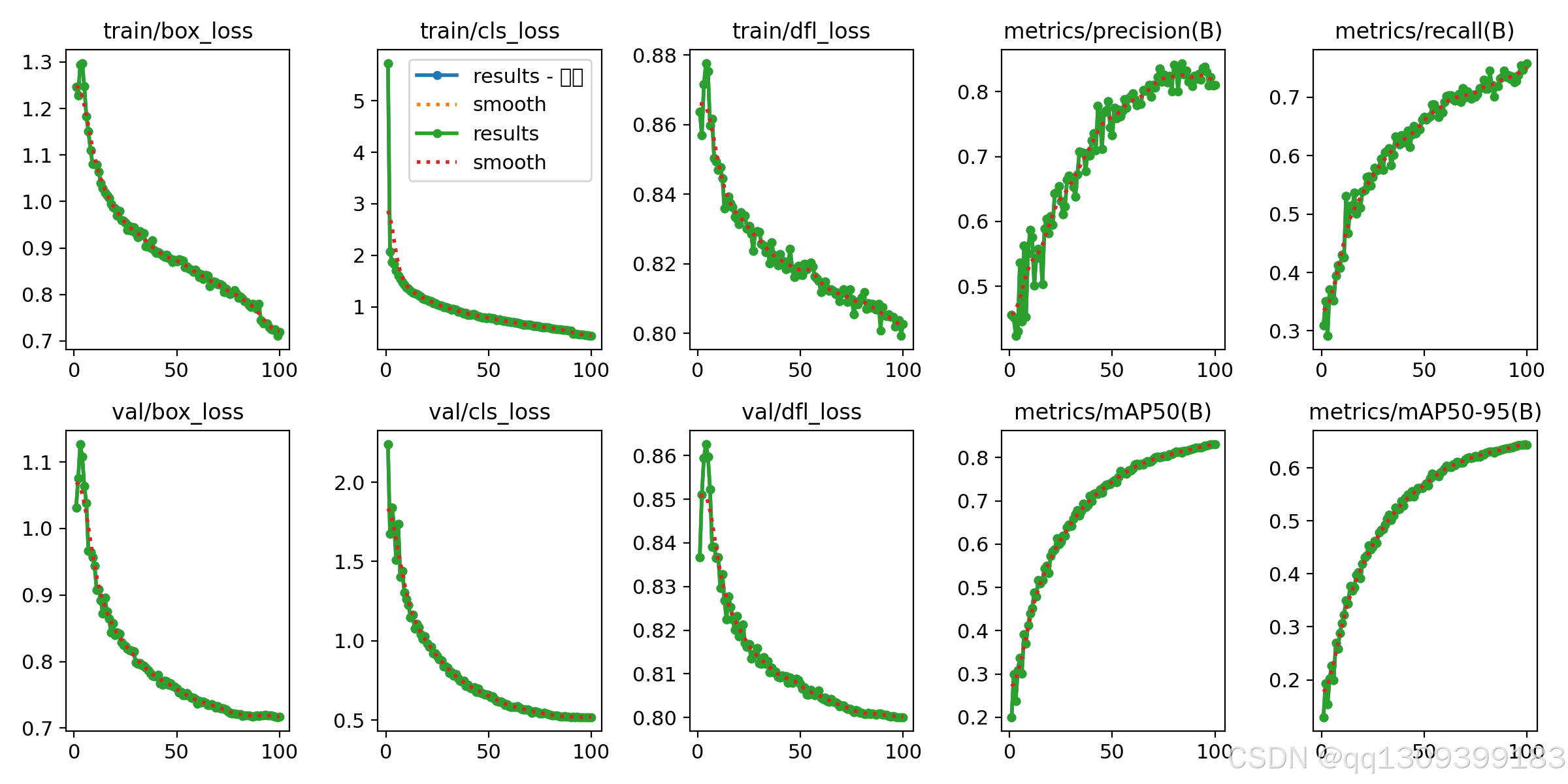
5. 训练参数说明
model: 预训练模型路径data: 数据集配置文件路径epochs: 训练轮数imgsz: 输入图片大小(默认 640x640)batch: 每次训练的批量大小device: 训练所使用的 GPU(如0表示第一块 GPU)
测试与评估
1. 模型评估
在验证集上评估模型性能,使用以下命令:
yolo val model=best.pt data=data.yaml imgsz=640
- 评估指标:
- mAP(mean Average Precision):衡量模型检测精度的综合指标。
- Recall:模型召回率。
- Precision:模型准确率。
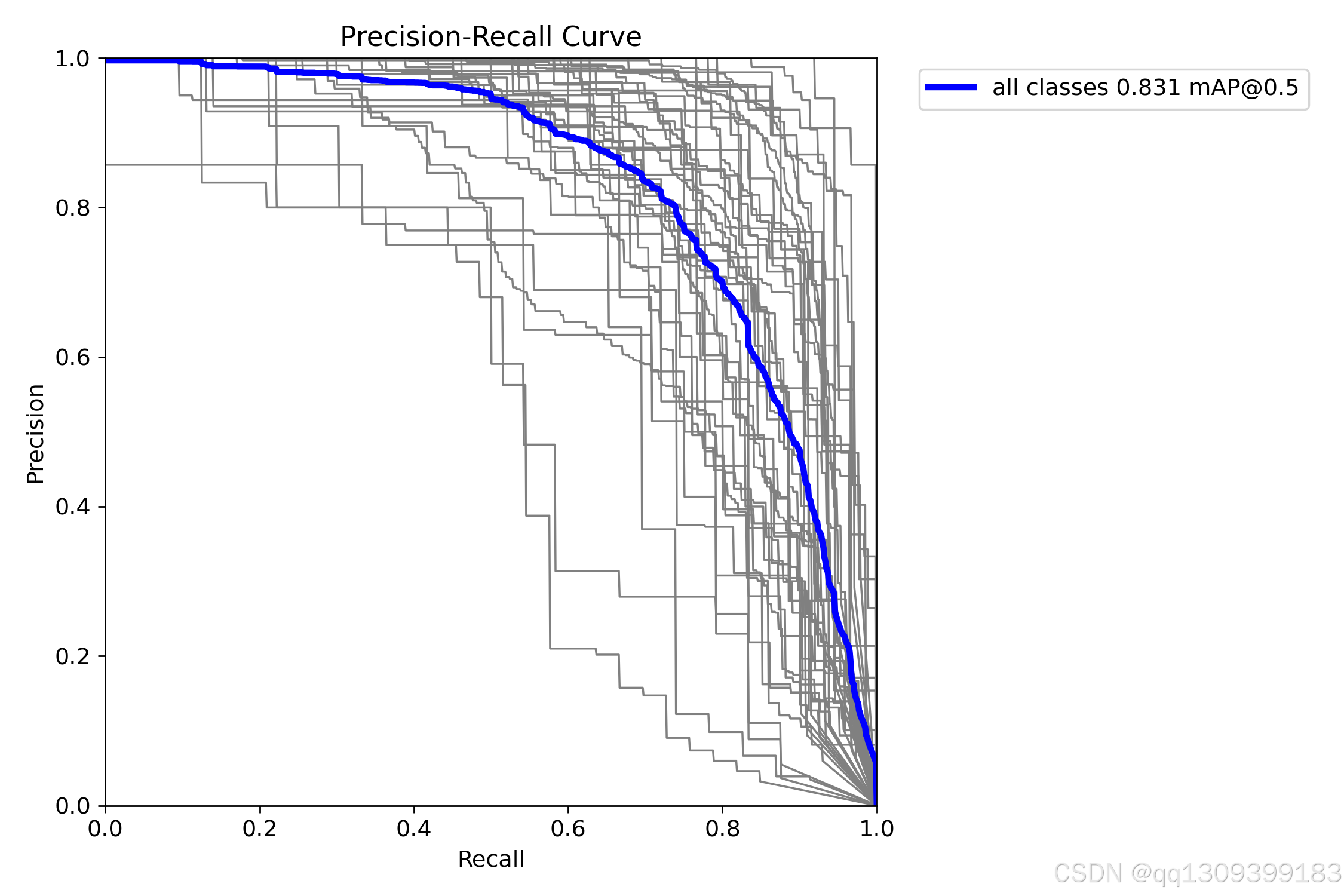
2. 测试推理
在测试集或单张图片上运行推理,查看模型效果:
yolo detect model=best.pt source=/path/to/image_or_video
实验结果
1. 检测性能
- 在 TT100K 数据集上,模型达到 mAP@0.5 = 96.2% 的检测性能。
- 对小目标和复杂场景(如遮挡和模糊)的检测能力显著提升。
2. 推理速度
- 在 NVIDIA RTX 3090 GPU 上推理速度达到 120 FPS,满足实时交通标志检测需求。
- 在嵌入式设备(如 Jetson Xavier)上推理速度达到 25 FPS,支持车载部署。
应用场景
- 自动驾驶辅助系统:
- 实时检测交通标志,协助车辆作出智能决策。
- 智能交通监控:
- 识别道路标志以优化交通管理和提升安全性。
- 车载导航系统:
- 融合检测信息提升路径规划精度。
未来改进方向
- 数据扩展:
- 引入更多国家和地区的交通标志数据集,提高系统的通用性。
- 模型优化:
- 针对嵌入式设备优化 YOLOv11 模型,降低计算成本。
- 目标追踪:
- 集成目标追踪算法,实现交通标志的连续跟踪。
结语
基于 YOLOv11 和 TT100K 数据集的交通标志识别系统展现了强大的检测性能和高实时性,在智能交通和自动驾驶领域具有广阔的应用前景。通过持续优化模型和算法,该系统可以进一步提升准确率和鲁棒性,为未来智能交通系统的发展提供支持。



















 598
598

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









