







YOLOv8加入Swin-Transformer的方法和涨点效果
方法介绍
在YOLOv8中集成Swin-Transformer旨在利用其强大的分层特征提取能力,以增强模型对多尺度信息的感知,特别是对于小目标检测任务。以下是详细阐述如何将Swin-Transformer引入YOLOv8,并实现性能提升的具体步骤。
- 理解原理:
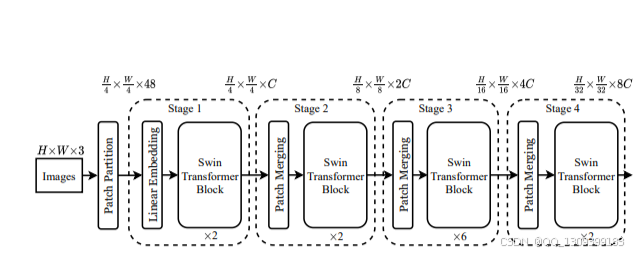
- Swin Transformer是一种基于窗口的自注意力机制(Window-based Self-Attention, W-MSA)的视觉Transformer架构。它通过将输入图像分割成非重叠的小窗口,在每个窗口内执行局部自注意力计算,同时允许跨窗口连接,从而有效降低了计算复杂度。
- 它还引入了连续窗口分区移动(shifted window partitioning),使得相邻窗口之间可以共享信息,增强了模型的建模能力。
class WindowAttention(nn.Module):
r""" Window based multi-head self attention (W-MSA) module with relative position bias.
It supports both of shifted and non-shifted window.
Args:
dim (int): Number of input channels.
window_size (tuple[int]): The height and width of the window.
num_heads (int): Number of attention heads.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set
attn_drop (float, optional): Dropout ratio of attention weight. Default: 0.0
proj_drop (float, optional): Dropout ratio of output. Default: 0.0
"""
def __init__(self, dim, window_size, num_heads, qkv_bias=True, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.dim = dim
self.window_size = window_size # Wh, Ww
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
# define a parameter table of relative position bias
self.relative_position_bias_table = nn.Parameter(
torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads))
-
代码实现:
- 修改YOLOv8的主干网络:首先需要修改
ultralytics/cfg/models/v8/yolov8.yaml文件中的backbone部分,以适应Swin-Transformer模块的插入。这可能涉及到调整卷积层的数量、类型以及它们之间的连接方式。 - 添加Swin-Transformer代码:根据论文提供的官方实现或者社区贡献的实现版本,将Swin-Transformer的相关组件(如
WindowAttention,Mlp,PatchMerging等)添加到项目中。 - 新增yaml配置文件:创建一个新的配置文件来定义使用Swin-Transformer作为骨干网时的超参数设置,例如窗口大小、嵌入维度、深度等。
- 注册模块:确保新添加的Swin-Transformer类能够在YOLOv8的框架中被正确识别和调用,通常是在
from ultralytics.nn.modules import语句下添加相应的导入声明。 - 执行程序:完成上述更改后,重新编译并运行训练脚本,测试改进后的YOLOv8+Swin-Transformer模型是否能够正常工作。
- 修改YOLOv8的主干网络:首先需要修改
-
涨点效果:
加入Swin-Transformer后的YOLOv8模型展示了显著的性能提升,尤其是在以下几个方面:
- 多尺度信息捕捉:由于Swin-Transformer具备分层结构,它可以更好地学习不同层次的特征表示,提高了对图像中各种尺度目标的检测精度。
- 小目标检测能力:对于较小的目标,传统卷积神经网络可能会因为感受野有限而难以准确捕捉。Swin-Transformer则可以通过其独特的窗口机制有效地关注细粒度特征,从而改善小目标的检测效果。
- 计算效率:虽然增加了新的组件,但Swin-Transformer的设计考虑到了计算资源的有效利用,保持了较高的推理速度。
- 泛化性能:实验表明,经过改进的YOLOv8模型不仅在特定数据集上表现出色,而且在其他未见过的数据分布上也能维持良好的泛化能力。
yolov8-SwinT.yaml
nc: 5 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f_Invert, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f_Invert, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f_Invert, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
#- [-1, 3, C3x, [1024, True]]
#- [-1, 3, C2f_Invert, [1024, True]]
#- [-1, 6, PatchEmbed, [224, True]]
- [-1, 6, SwinTransformerLayer, [1024, True]] # - [-1, 3, C2f, [1024, True]]SwinTransformerLayer
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 21 (P5/32-large)
结果对比
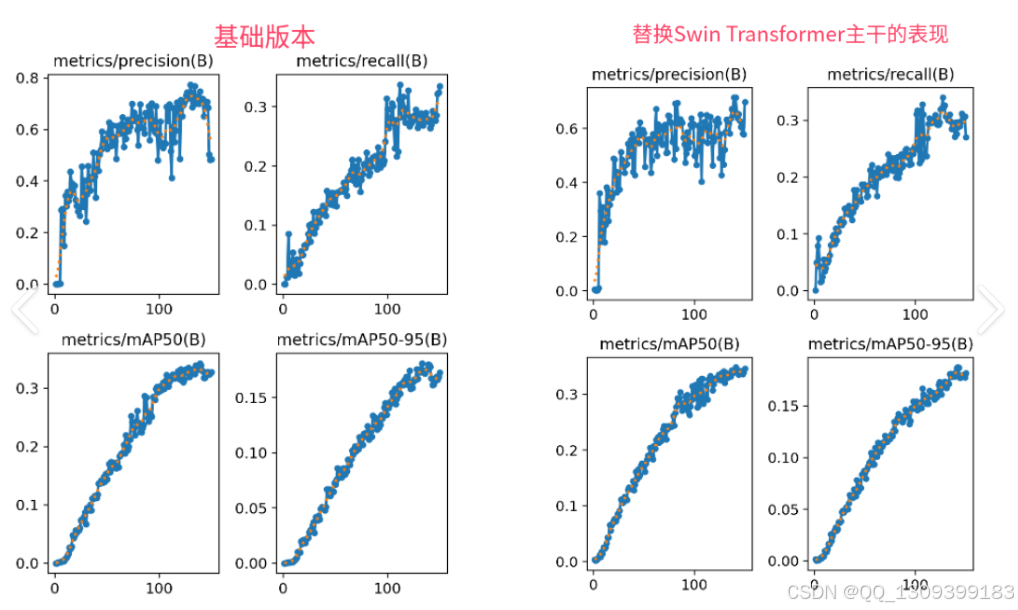
综上所述,通过精心设计和优化,YOLOv8与Swin-Transformer的成功结合为计算机视觉领域带来了新的突破,特别是在目标检测任务中实现了更高的准确性和鲁棒性。此改进方案为后续研究提供了宝贵的经验和技术参考,同时也为实际应用场景下的部署打下了坚实的基础。


















 4816
4816

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









