









文章目录
提示:以下是本篇文章正文内容,Java系列学习将会持续更新
一、常见数据结构
非线程安全的数据结构:ArrayList,LinkedList,ArrayQueue,HashMap,HashSet
线程安全的数据结构:Vector,Stack,Hashtable,CopyOnWriteArrayList,ConcurrentHashMap
二、ArrayList
2-1 线程不安全的原因
看源码
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
// 该方法是容量保障,当容纳不下新增的元素时会进行扩容
elementData[size++] = e;
return true;
}
分析:
- 当数组长度为10,而size = 9时,此时A线程判断可以容纳,B线程也来判断发现可以容纳(这是因为add非原子操作)。当A添加完之后,B线程再添加的话,就会报错(数组越界异常)
- 而且这一步elementData[size++] = e也非原子性的.
可以拆分为elementData[size] = e 和 size ++;
在多线程的情况下很容易出现elementData[size] = e1;elementData[size] = e2;size++;size++;的情况
2-2 Vector实现安全
Vector的add()源码:
public synchronized void addElement(E obj) {
modCount++;
ensureCapacityHelper(elementCount + 1);
elementData[elementCount++] = obj;
}
分析:
Vector的add方法加了synchronized ,而ArrayList没有,所以ArrayList线程不安全,但是,由于Vector加了synchronized ,变成了串行,所以效率低。
三、CopyOnWriteArrayList
CopyOnWrite容器即写时复制的容器。
// java.util.concurrent包下
List<String> list = new CopyOnWriteArrayList<String>();
3-1 如何实现线程安全?
通俗的理解是当我们往一个容器添加元素的时候,不直接往当前容器添加,而是先将当前容器进行Copy,复制出一个新的容器,然后新的容器里添加元素,添加完元素之后,再将原容器的引用指向新的容器。
这样做的好处是我们可以对CopyOnWrite容器进行并发的读,而不需要加锁,因为当前容器不会添加任何元素。所以CopyOnWrite容器也是一种读写分离的思想,读和写不同的容器。
3-2 特征
-
CopyOnWriteArrayList(写数组的拷贝)是ArrayList的一个线程安全的变体,CopyOnWriteArrayList和CopyOnWriteSet都是线程安全的集合,其中所有可变操作(add、set等等)都是通过对底层数组进行一次新的复制来实现的。
-
它绝对不会抛出ConcurrentModificationException的异常。因为该列表(CopyOnWriteArrayList)在遍历时将不会被做任何的修改。
-
CopyOnWriteArrayList适合用在“
读多,写少”的并发场景中,比如缓存、白名单、黑名单。它不存在“扩容”的概念,每次写操作(addorremove)都要copy一个副本,在副本的基础上修改后改变array引用,所以称为“CopyOnWrite”,因此在写操作要加锁,并且对整个list的copy操作时相当耗时的,过多的写操作不推荐使用该存储结构。 -
读的时候不需要加锁,如果读的时候有多个线程正在向CopyOnWriteArrayList添加数据,读还是会读到旧的数据,因为开始读的那一刻已经确定了读的对象是旧对象。
3-3 缺点
- 在写操作时,因为复制机制,会导致内存占用过大。
- 不能保证实时性的数据一致,“脏读”。
四、HashMap
4-1 底层原理
不清楚的小白看看之前两篇文章,就可以很容易搞懂HashMap的底层实现原理了。
4-2 线程不安全的原因
单看 HashMap 中的 put 操作:
- JDK1.7头插法 –> 将链表变成环 –> 死循环
- JDK1.8尾插法 –> 数据覆盖
五、ConcurrentHashMap
// java.util.concurrent包下
Map<Integer, String> map = new ConcurrentHashMap<>();
5-1 实现原理
- JDK1.7时,采用分段锁,将一个大哈希表默认分为16段的哈希表,同一个小表内互斥。用的是
Lock锁。
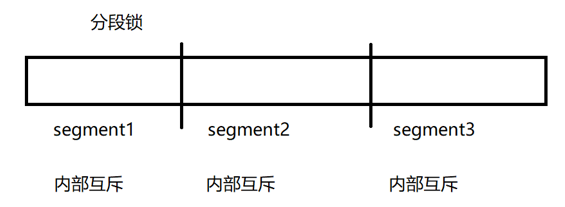
- JDK1.8时加入了红黑树,且只针对同一链表内互斥,不是同一链表内的操作就不需要互斥。用的是
synchronized锁。
但是一旦遇到需要扩容的时候,涉及到所有链表,此时就不是简单的互斥了。
扩容的过程:
- 当A线程put 操作时发现需要扩容,则它自己创建一个扩容后的新数组。
- A线程只把当前桶中的节点重新计算哈希值放入新数组中,并且标记该桶元素已经迁移完成。由于其它桶中的元素还没有迁移,所以暂时还不删除旧数组。
- 等其它线程抢到锁并在桶内做完操作时,需要义务的将该桶节点全部搬移并标记桶。
- 直到最后一个线程将最后一桶节点搬移完毕,则它需要把旧数组删除。
5-2 与Hashtable的区别
HashTable和HashMap的实现原理几乎一样,差别在于:
- HashTable不允许key和value为null;
- HashTable是线程安全的。
但是HashTable线程安全的策略实现代价却比较大,get/put所有相关操作都是synchronized的,这相当于给整个哈希表加了一把全表锁。当一个线程访问或操作该对象,那其他线程只能阻塞。
所以说,Hashtable 的效率低的离谱,几近废弃。
总结:
提示:这里对文章进行总结:
以上就是今天的学习内容,本文是Java数据结构和多线程的应用学习,认识常用数据结构的线程安全性,理解某些集合不安全的原因,以及某些集合底层如何实现的线程安全性。之后的学习内容将持续更新!!!
















 9306
9306











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











