







目录
3.正常运行的MySQL,数据写入后的最终落盘,是通过redo log更新过来的还是从buffer pool更新过来的
深色:Server层
浅色:innodb存储引擎层
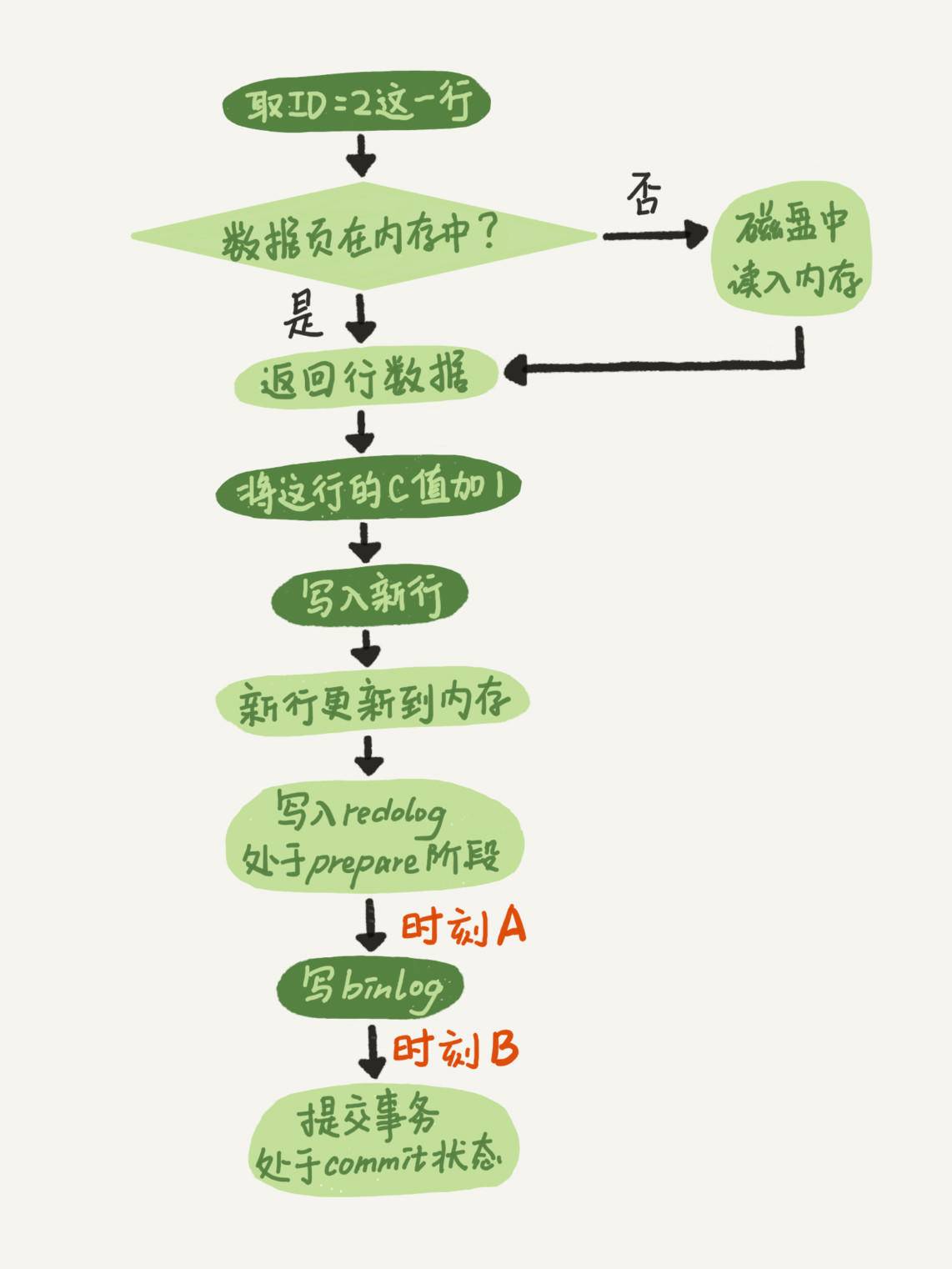
1.MySQL如何知道binlog是完整的
①statement格式的binlog(基于SQL语句的复制),最后会有 commit和 XID event
②row格式的binlog(基于每条数据的修改记录),最后会有 commit和 XID event
2.redo log和binlog如何关联起来
redo log和binlog有一个共同的数据字段,叫XID
当系统崩溃恢复时,会按照顺序扫描redo log:
若既有prepare、又有commit的redo log,则直接提交
若碰到只有prepare、没有commit的redo log,就拿着XID去binlog找对应的事务,如果找到了,则提交,否则回滚
3.正常运行的MySQL,数据写入后的最终落盘,是通过redo log更新过来的还是从buffer pool更新过来的
redo log并没有记录数据页的完整数据,因此它并没有能力去更新磁盘数据
①正常运行的时候,内存中的数据页被修改以后,和磁盘的数据页不一致,称为脏页。最终的数据落盘,就是把内存中的数据页写盘,与redo log没关系
②崩溃恢复的时候,innodb如果判断一个数据页可能丢失了更新,就会将其读到内存中,然后让redo log更新内存操作。更新完成后,脏页再落盘
4.为什么不能使用binlog进行崩溃恢复
一个事务的binlog如果回放,就是重做这个事务,而这个事务可能会涉及到多个数据页
如果一个事务更新了A、B、C三个数据页,崩溃后,A、B数据页没问题落盘了,C没有落盘
使用binlog恢复,可能会造成C恢复成功,但是A、B出现问题
5.当脏页刷盘后,对应的redo log会不会清除
不会,redo log下次刷的时候,看到是干净页,就会直接跳过
6.binlog的写入机制
①事务执行的过程中,先把日志写到binlog cache,事务提交的时候,再把binlog cache写到binlog文件中,并清空binlog cache
②一个事务的binlog是不能被拆开的,因此不论事务多大,也要确保一次性写入,否则主从同步有问题(分段执行)。且一个线程只能同时有一个事务在执行
③系统给每个线程分配一个binlog cache内存(binlog_cache_size用于控制单个线程该内存的大小),如果超过这个大小,就要暂存到磁盘
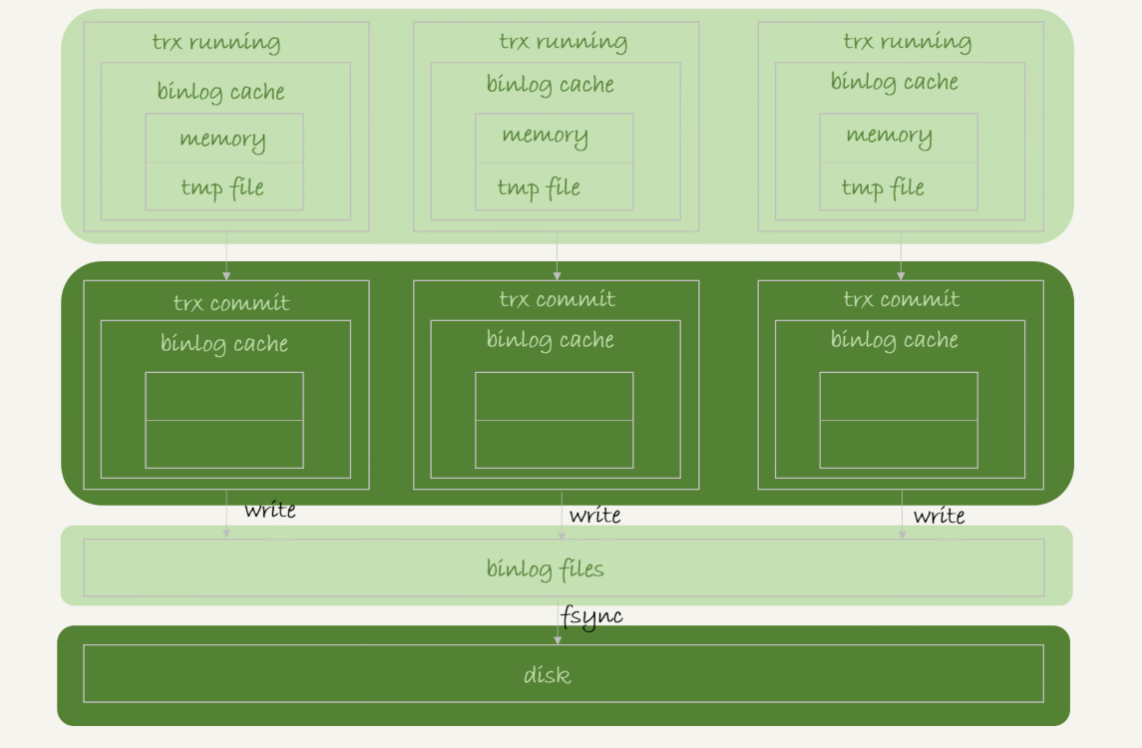
每个线程都有自己的binlog cache,但是共用同一份binlog文件
write:将日志写入到文件系统的page cache(Linux内),还没有把数据持久化到磁盘,所以速度比较快
fsync:将数据持久化道磁盘
sync_binlog:控制binlog的写入策略
sync_binlog=0:表示每次提交事务都只write,不fsync。
sync_binlog=1:表示每次提交事务都write+fsync。此时数据安全性最高,性能最低
sync_binlog=N(N>1):表示每次提交事务都write,但累积N个事务后才fsync。当主机异常重启,会丢失最近N个事务的binlog日志
7.redo log的写入机制

innodb_flush_log_at_trx_commit:控制redo log的写入策略
0:每次事务提交时都只把redo log留在 redo log buffer
1:每次事务提交时都进行write+flush持久化磁盘
2:每次事务提交时都只写入page buffer
redo log持久化场景:
①上面情况
②innodb有一个后台线程,每隔一秒,就会将redo log buffer中的日志,调用write写入到page buffer,最后调用fsync持久化磁盘
注意:事务执行的过程中,redo log也是直接写到redo log buffer中的,这些redo log 也会被后台线程持久化到磁盘中
也就是说,一个没有提交事务的redo log,也是可能被持久化磁盘的
③redo log buffer 占用的空间即将达到innodb_log_buffer_size一半的时候,后台线程会主动写盘(write到page buffer中)
④并行的事务执行的时候,将该事务的redo log buffer 顺带持久化到磁盘中
(并不是指该事务prepare持久化,只是指该事务的一部分持久化磁盘,只有该事务进入提交阶段,才会有prepare状态)
如果把innodb_flush_log_at_trx_commit设置为1时,redo log在prepare阶段就会持久化磁盘一次。
一个事务在完整提交之前,需要等待redo log prepare落盘和binlog落盘。
第5点只需要write,因为崩溃恢复的逻辑,redo log prepare和binlog已经落盘,数据不会丢失,所以innodb会认为redo log在commit阶段不需要fsync
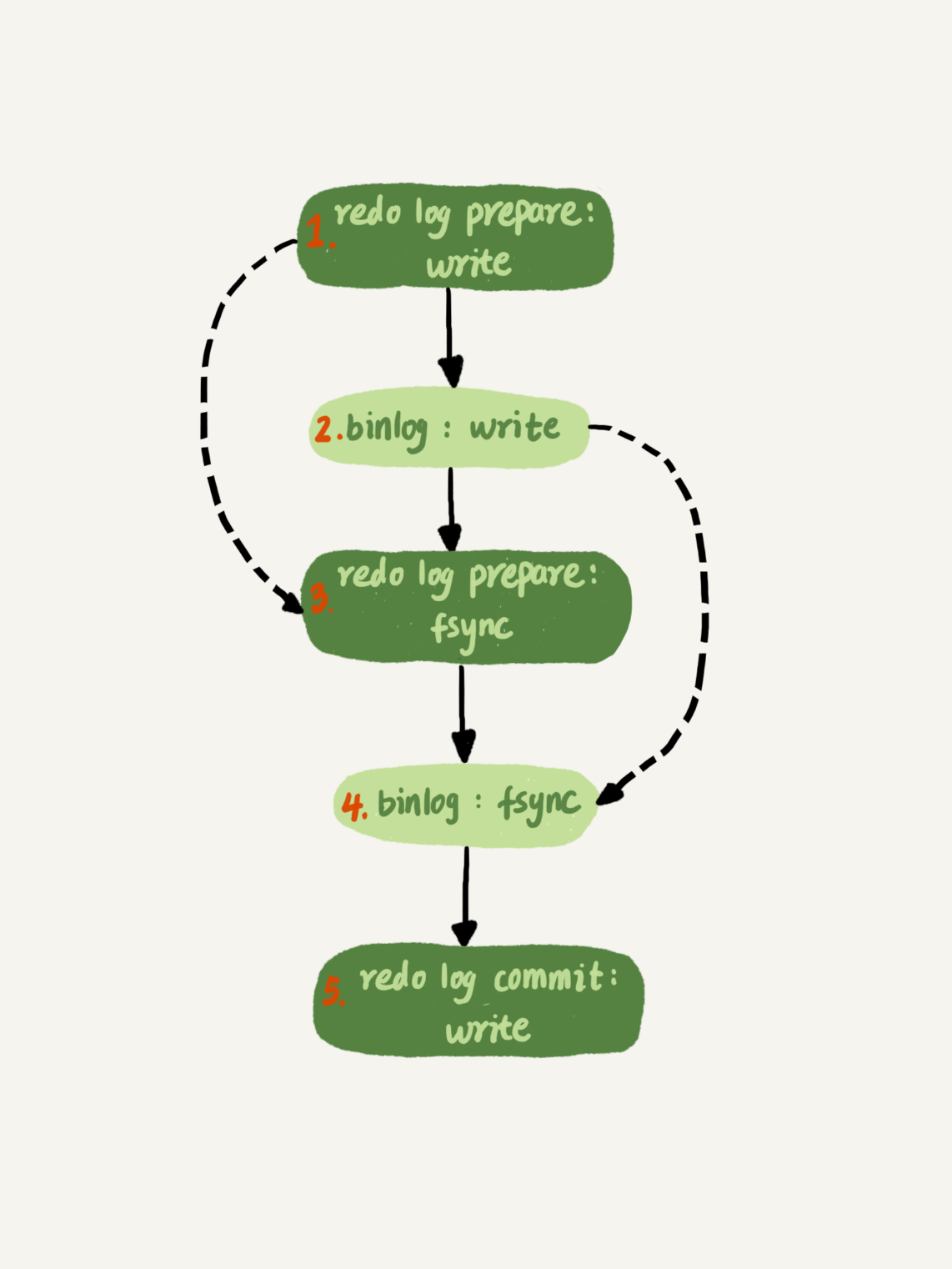
8.组提交机制
参考上图
当binlog fsync时,如果多个binlog已经write page buffer完成,则可以一起持久化磁盘,减少IOPS的消耗(redo log prepare同理)
binlog_group_commit_sync_delay:表示延迟多少微秒后才调用fsync
binlog_group_commit_sync_no_delay_count:表示累积多少次后才调用fsync
上面两者满足其一就fsync,减少IOPS(Input/OutputOperations Per Second)消耗,但是增加了持久化时间
上面两个参数和sync_binlog的区别是:
先满足sync_binlog可以刷盘了,再等到上面两个参数逻辑满足了再fsync
当sync_binlog=0时(只write),上面两个逻辑也会等待,但是等完还是不执行fsync
例子:
binlog_group_commit_sync_no_delay_count = 10,sync_binlog = 5 ===>>> 每10次fsync一次
9.undo log存储格式
更新内存之前,先写undo log
undo log 分为两种类型,一种是insert_undo(insert操作),记录插入的唯一键值;一种是update_undo(包含update及delete操作),记录修改的唯一键值以及old colomn记录

10.日志持久化

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









