







目录
一、flush脏页引起的SQL执行速度慢
疑问:本来执行很快的SQL,但是为什么突然就执行很慢?
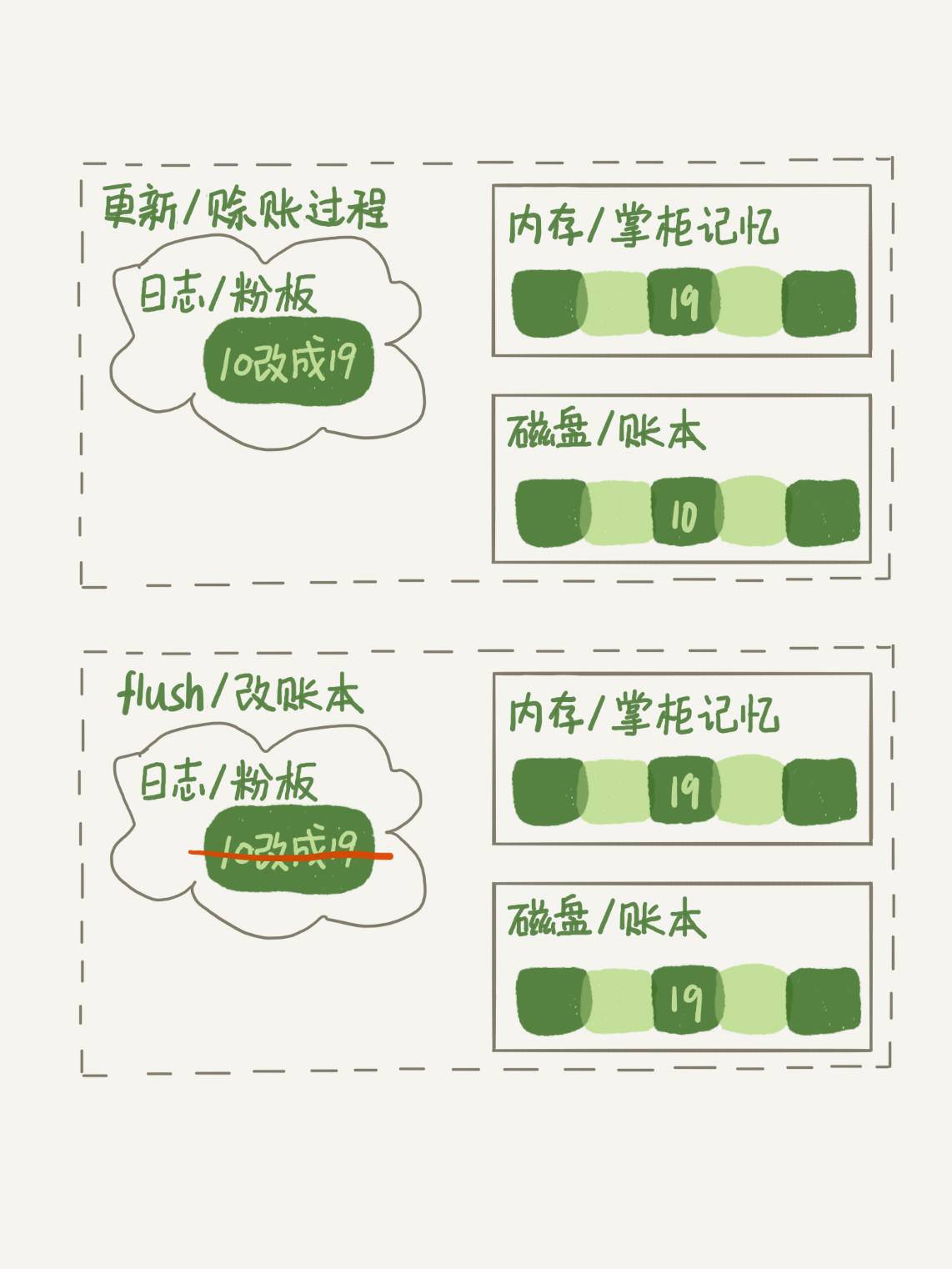
1.脏页
脏页:内存中数据页内容和磁盘数据页不相同
干净页:内存中数据页内容和磁盘数据页相同
无论脏页还是干净页,都是在内存中(buffer pool)
2.flush过程
innodb在处理更新语句时,更新内存+写redo log(+binlog),完成后返回客户端更新成功
此时,磁盘的数据页内容还不是最新的,flush就是将内存中最新的数据刷到磁盘页中进行持久化
而flush会造成SQL执行变得比较慢(阻塞执行),在正常情况下SQL执行很快
3.什么时候触发flush操作
①innodb的redo log写满了
由于redo log是固定大小,追加顺序写,写满了以后,系统会停止所有的更新操作,将redo log 中的部分日志(即将写的那部分日志空间) 对应的脏页flush到磁盘中
以便redo log 能留出空间可以继续写
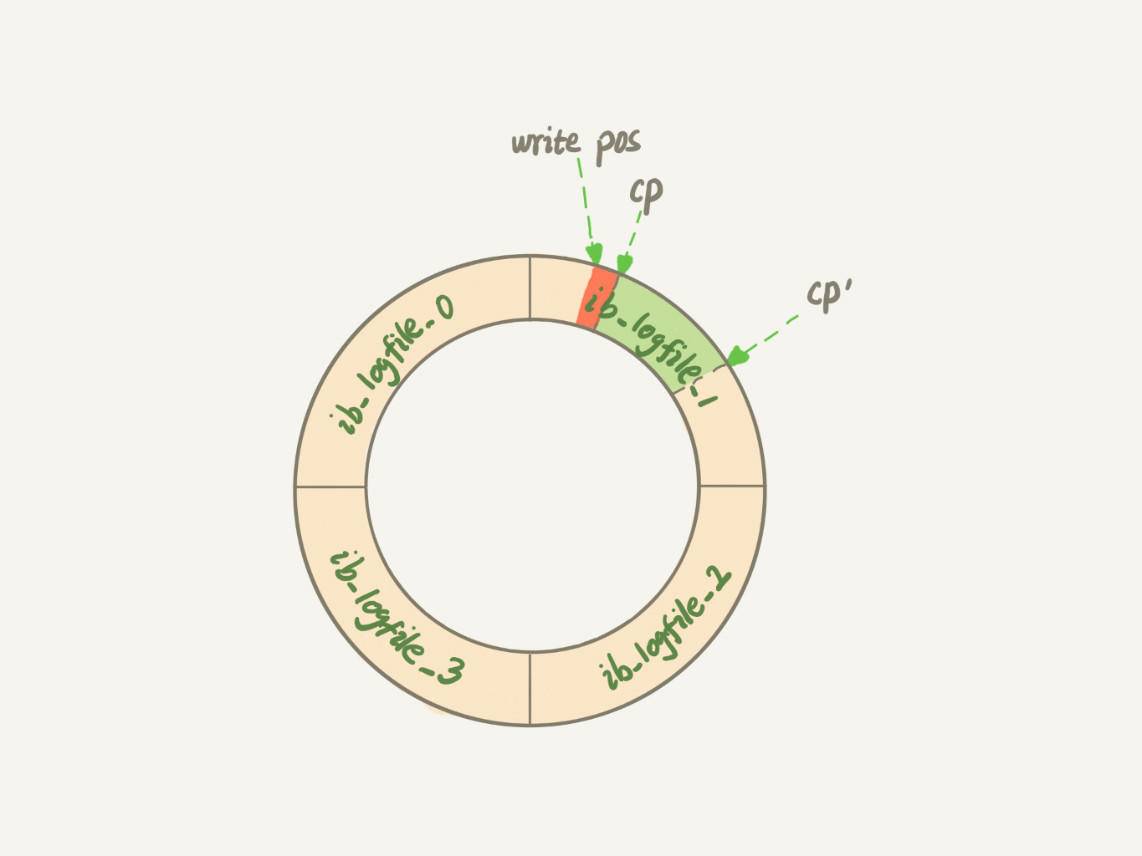
图中,将cp(check point)到cp’(新check point)之间的日志所对应的脏页flush到磁盘中,之后,write pos 到 cp'之间就是可以再次写入(check point机制以后可以好好了解,中优先级)
②内存不足
当需要新的内存页,而内存不够用的时候,就需要淘汰一些数据页(LRU算法)(innodb_buffer_pool页面淘汰算法以后可以好好了解,中优先级),空出内存。
如果淘汰的是脏页,就要先将脏页写到磁盘中
如果淘汰的是干净页,直接淘汰
所以,一个操作如果要淘汰的脏页数量太多,就会导致响应时间会明显边长
③空闲时候
④正常关闭
MySQL正常关闭时,会将所有脏页flush到磁盘上,下次启动的时候,就直接从磁盘中读取
总的来说,刷脏页虽然是常态,但是,当出现一个操作淘汰的脏页数量太多 以及 redo log日志写满,阻塞全部更新操作 这两种情况时,会导致响应时间过长
4.innodb刷脏页的控制策略
①设置innodb_io_capacity(磁盘的IO能力)
需要告诉innodb所在主机的IO能力,这样innodb才能知道全力刷磁盘时,可以刷多快
这个值一般设置为磁盘的IOPS(Input/Output Per Second,即每秒的读写次数,是衡量磁盘性能的主要指标)(IOPS的计算以后有兴趣可以再看看,极低优先级)
如果这个值设置过小,则innodb会认为磁盘的IO能力比较弱,刷脏页就会刷的比较慢,就会造成脏页的累积
②innodb选择合适的刷盘速度
两个影响因素:脏页比例、redo log 写盘速度
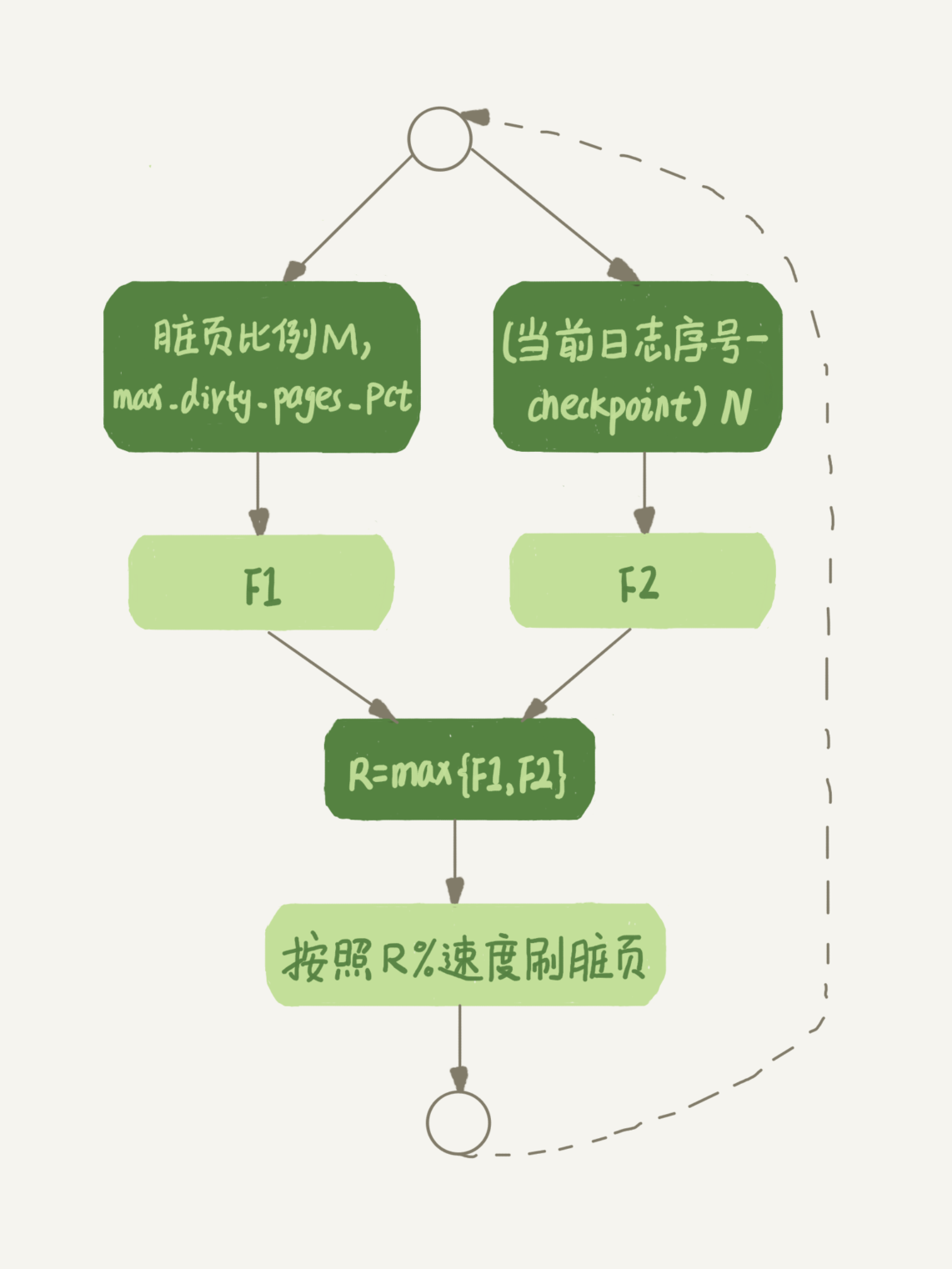
F1:参数innodb_max_dirty_pages_pct是脏页的比例上限,默认75%,innodb会根据当前比例算出来F1
F2:innodb每次写入redo log都有一个序号,当前写入的序号跟checkpoint对应的序号之间的差值记为N,innodb会根据这个N算出F2(具体咋算不用关心)
innodb按照indodb_io_capacity定义的能力乘以R%(R为F1和F2的最大值)来控制刷脏页的速度
5.innodb刷脏页的连坐机制
当innodb flush一个脏页的时候,如果这个数据页旁边的数据页也是脏页,就会把这个邻居数据页一起刷掉,如果与邻居数据页相邻的也是脏页,则会一起刷
innodb_flush_neighbors:1表示使用连坐机制,0表示不使用,自己刷自己
优点:对于机械硬盘来说,随机IOPS一般只有几百,相同的逻辑操作能够减少随机IO,意味着性能的提高
缺点:对于固态硬盘来说,IOPS比较高(比机械硬盘高几十上百倍),可以设置为0,提高SQL响应速度
注:(需要好好理解,内存中有脏页,redo log有新操作,此时MySQL短电,MySQL会通过redo log 恢复数据,问:MySQL如何知道磁盘数据是脏页刷过的还是未刷过的???)
LSN(log sequence number) 用于记录日志序号,它是一个不断递增的 unsigned long long 类型整数。在 InnoDB 的日志系统中,LSN 无处不在,它既用于表示修改脏页时的日志序号,也用于记录checkpoint,通过LSN,可以具体的定位到其在redo log文件中的位置。
为了管理脏页,在 Buffer Pool 的每个instance上都维持了一个flush list,flush list 上的 page 按照修改这些 page 的LSN号进行排序。因此定期做redo checkpoint点时,选择的 LSN 总是所有 bp instance 的 flush list 上最老的那个page(拥有最小的LSN)。由于采用WAL的策略,每次事务提交时需要持久化 redo log 才能保证事务不丢。而延迟刷脏页则起到了合并多次修改的效果,避免频繁写数据文件造成的性能问题。
二、数据库表的空间回收
疑问:表数据delete删除,但是为什么表文件大小不变?
1.数据删除流程
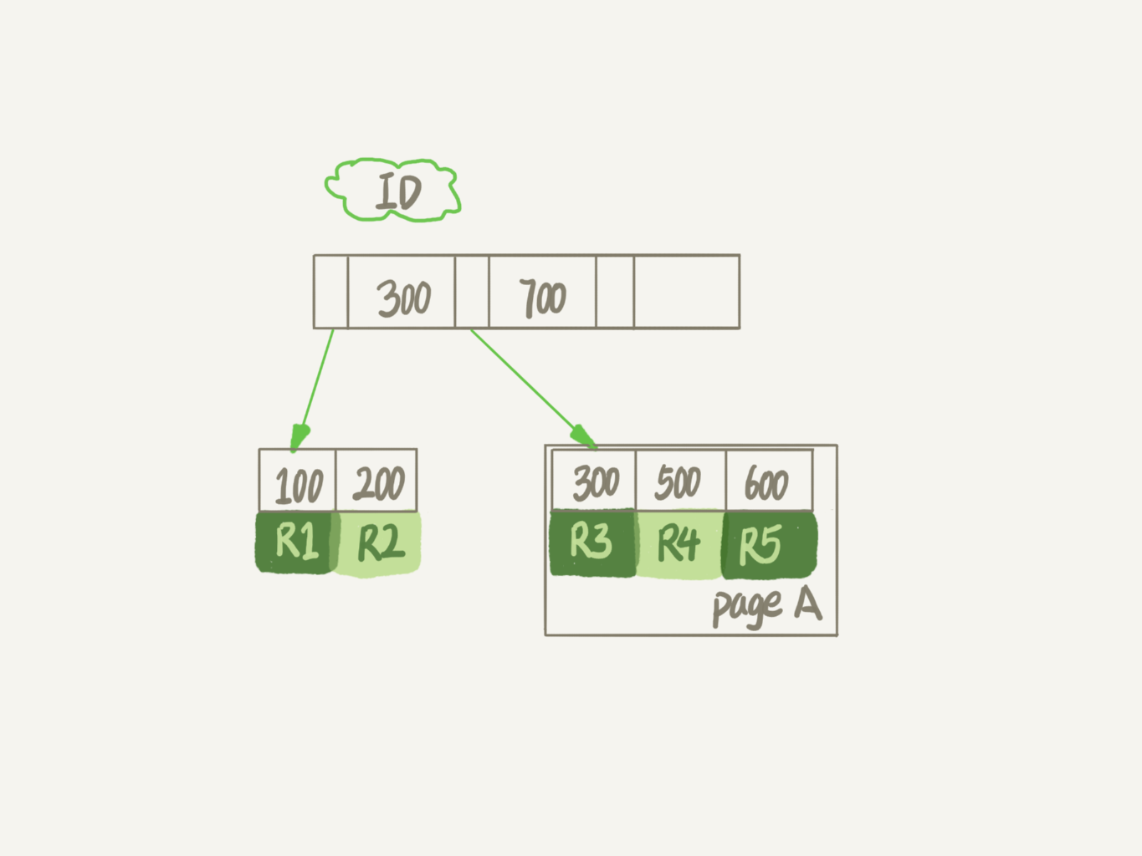
当删除id=500这条记录,innodb会将id=500这个记录标记为删除,磁盘文件的大小并不会变小。如果之后再插入id在300到600之间的记录时,有可能会复用这个位置。
而innodb的数据是按照页进行存储的,当一个数据页的所有记录都被删除了,那么这个数据页就可以被复用
数据页的复用和记录的复用是不同的:
①记录的复用,只限于符合范围条件的数据,上面的例子,如果插入一条id为800的记录,是不能够复用这个位置的
②当整个数据页的记录都被删除,那么这个数据页可以被复用在任何位置。
③如果相邻的两个数据页的利用率很小,系统就会将这两个数据页上的数据合并在其中一个页中,另一个数据页会被标记为可复用
④如果使用delete将整个表的数据删除,结果就是,所有的数据页都会被标记为可复用,但是磁盘文件大小不会变
也就是说,通过delete命令不能够回收表空间,仅会标记为可复用,这些没有被使用的空间,看起来就像是空洞
2.空间空洞
不止是删除数据会导致空洞现象,更新索引、插入数据也会导致空洞
如果数据是按照索引递增的顺序插入,那么索引是紧凑的,但是如果索引数据是随机插入的,就可能造成索引数据页的分裂

当pageA满了以后,再插入一条id为550的记录,就不得不申请一个新的数据页pageB来存储数据,pageA的尾部就出现了空洞
更新索引上的值,可以理解为删除一个旧的值,再插入一个新的值(id从200更新为700),也会造成空洞
也就是说,经过大量增删改的表,都是可能存在数据空洞的,如果要是能把这些空洞去掉,就可以达到收缩表空间的目的
3.重建表
使用alter table A engine=innodb命令来重建表,可以收缩表空间
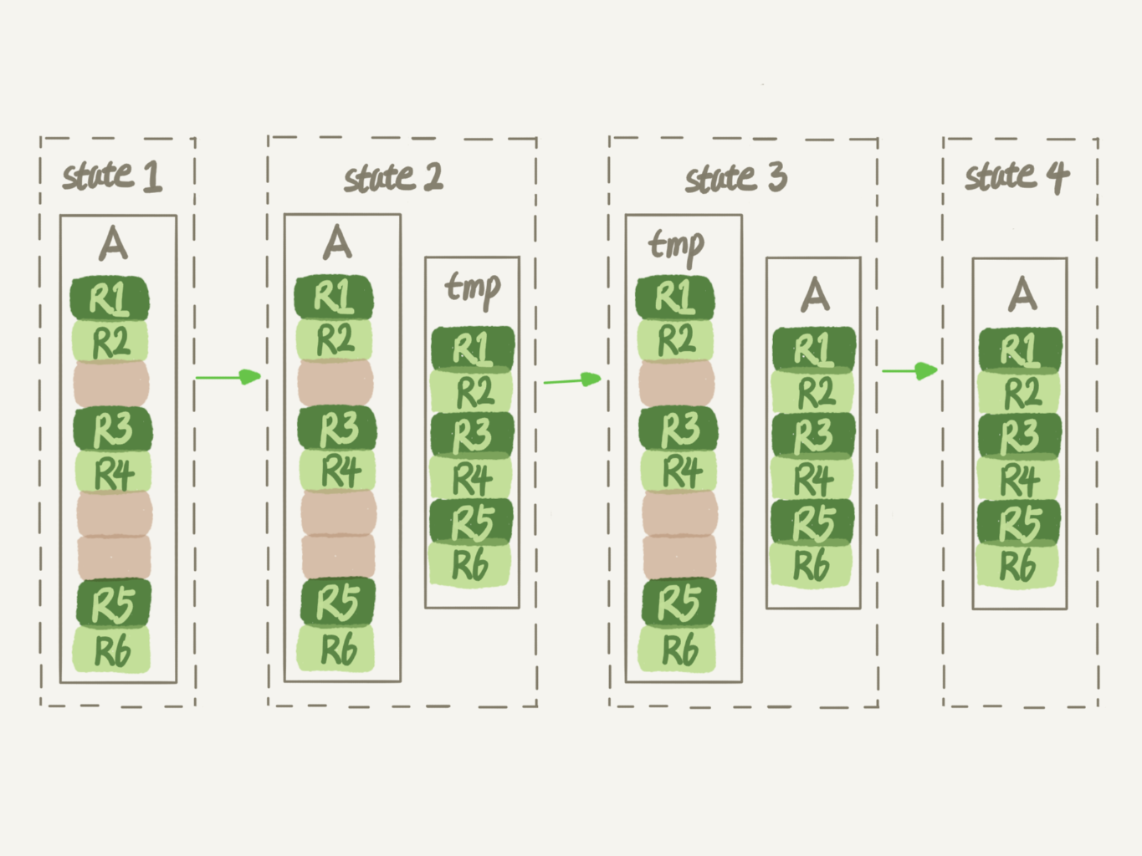
①在MySQL5.5版本及之前:
新建临时表、转存数据、交换表名、删除旧表
在整个过程中,表A不能有更新,如果有新数据写入表A,就可能会造成数据的丢失,即这个DDL不是Online的,而且是在server层
②在MySQL5.6版本及之后:
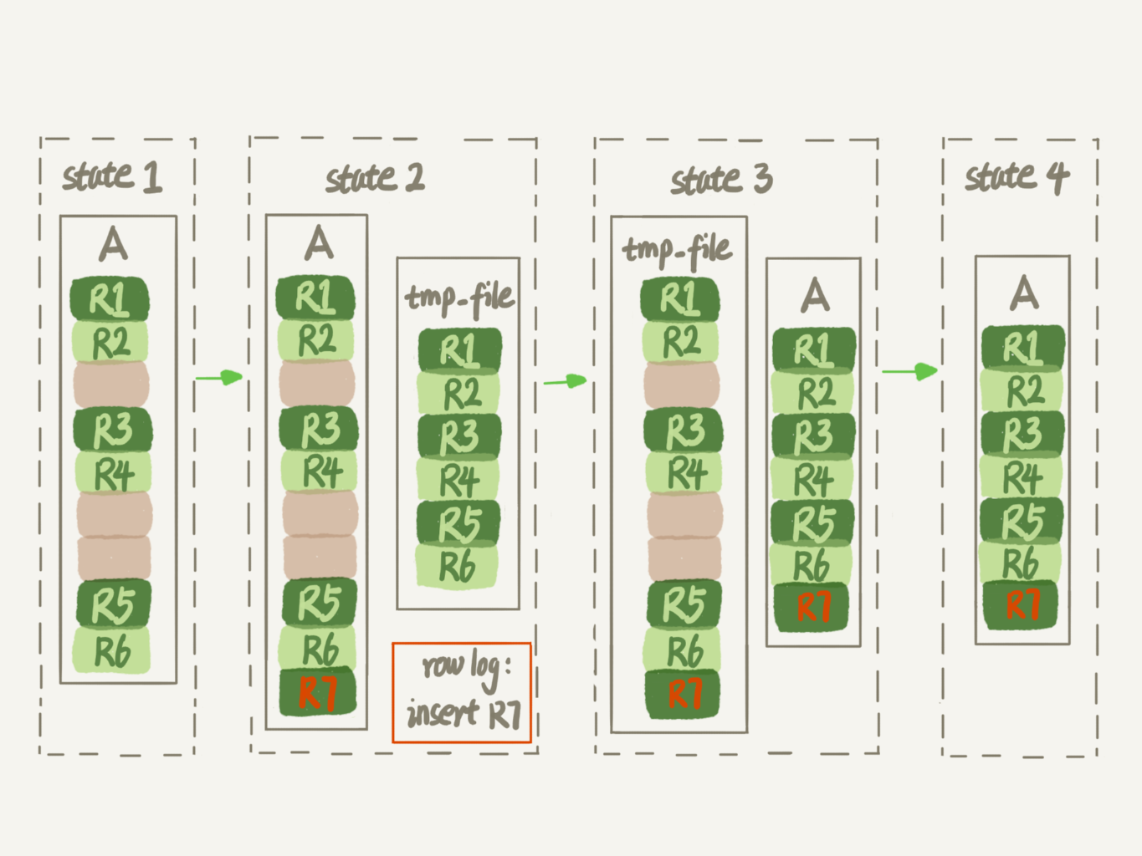
a.新建临时文件,扫描表A主键的所有数据页
b.用数据页中表A的记录生成B+树,存储到临时文件tmp-file中
c.在生成临时文件的时候,对表A的所有修改操作都会记录在row log中
d.临时文件生成后,将row log中的操作应用到临时文件中,再交换表名,删除临时表(此时是阻塞的,但是时间短,还是可以认为是Online)
在整个过程中,这个DDL是Online的,而且是在innoDB内部
注:
①DDL操作是需要拿到MDL写锁的,但是这个写锁在拷贝数据之前退化成MDL读锁。退化的目的就是为了实现Online,MDL读锁不会阻塞增删改操作
②上面这些重建方法都会扫描原表数据和构建临时文件,对于很大的表,这个操作是很消耗IO和CPU资源的
③alter table t engine = innodb (recreate):重建表
analyze table t:只是对表的索引信息做重新统计,没有修改数据,过程中加了MDL读锁
optimize table t:recreate + analyze
truncate:drop + create
4.Online和inplace
上面第二种重建表,整个DDL过程都是在innodb中完成的,对于server层来说,没有把数据移到临时表,是一个原地操作,可以称之为inplace
inplace和Online在重建表中的逻辑差不多一个意思,但是当给innodb表的一个字段添加全文索引,这个过程是inplace,但是会阻塞增删改操作,就不是Online的
也就是说,DDL过程如果是Online的,那么就一定是inplace的;反过来,inplace的DDL,有可能不是Online(全文索引和空间索引,以后可以了解一下)
三、innodb使用count(*)查询条数
疑问:如果需要经常计算一个表的行数,使用count(*)花费时间太长,应该怎么办?
1.count(*)的实现方式
①myisam引擎会将表的行数存储在磁盘上,执行count(*)时会直接返回这个数,效率很高
②innodb执行count(*)会将数据一行一行地从存储引擎里面读出来,然后累积计数
2.innodb为什么不把行数也存在磁盘上?
由于多版本并发控制(MVCC)的原因,在同一时刻的多个查询,查询出来的行数可能是不同的

3.计数方式
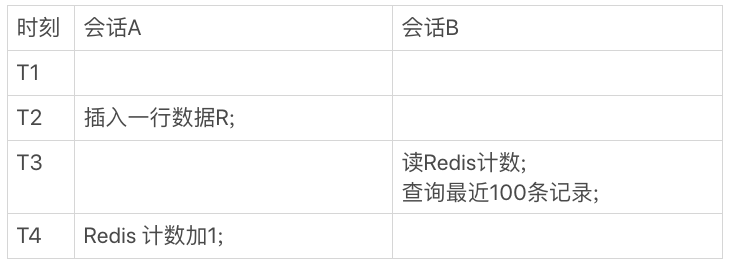
①使用缓存保存计数
涉及到缓存和db一致性问题,即使一致性有保证,下面的逻辑(先取出计数,再根据计数取数据记录)也是不准确的

②使用数据库保存计数
下面的逻辑(先取出计数,再根据计数取数据记录)是准确的

4.不同count的用法(innodb)
count(参数)是一个聚合函数,对于返回的结果集,会一行一行地进行判断,如果count函数的参数不为null,累计值就加1,否则就不加
①count(主键id):innodb会遍历整张表,会选择合适的索引树(都有主键),把每一行的主键id拿出来,返回给server层。server层拿到id后,判断是不可能为null的,按行累加
②count(1):innodb会遍历整张表,但不取值。server层对于返回的每一行,放一个数字1进行,判断是不可能为空的,按行累加
③count(字段):如果这个字段定义为not null,会一行行地读出这个字段,判断是不可能为null的,按行累加
如果允许为null,会把值取出来在判断一下,不为null才累加
如果该字段有索引,大概率会扫描该字段的索引树
④count(*):已经被优化过,不会把全部字段取出来,不取值。count(*)肯定不为null,按行累加
主键索引树的叶子节点是数据,而普通索引树的叶子节点是主键值。所以,普通索引树比主键索引树小很多。
对于count(*)这样的操作,遍历哪个索引树得到的结果逻辑上都是一样的。因此,MySQL优化器会找出最小的那棵树来遍历,减少扫描量
总的来说,count(字段) < count(主键id) < count(1) ≈ count(*)
四、修改的值和原来相同,MySQL会去执行修改吗?
例子:id等于1的记录,a已经等于2了,再执行update t set a=2 where id = 1;
①MySQL读出数据发现和原来相同,不更新,直接返回???错误
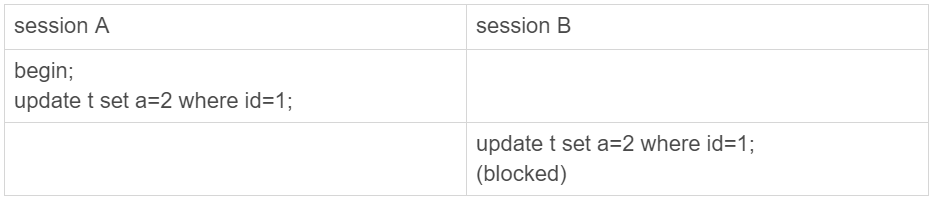
session B的update语句被blocked,而加锁这个操作时innodb才能做的,所以错误
②MySQL调用innodb引擎提供的接口,但是引擎发现和原来的值相同,不更新,直接返回???错误

session A的第二个查询是快照读(一致性读),它是不能看到session B的更新操作的,但是还是查询出了3,则可以证明session A的update语句是执行成功的了
所以说,修改的值和原来相同,MySQL也会正常执行,该加锁加锁,该更新更新
五、查询数据过多,会不会把数据库打爆
https://blog.csdn.net/weixin_34344677/article/details/94724824
1.全表扫描对server层的影响
MySQL server端的取数据和发数据流程:
①获取一行,写到net_buffer中,这块内存的大小是由net_buffer_length定义的,默认是16k
②重复获取行,直到net_buffer写满,然后调用网络接口发出去
③如果发送成功,就清空net_buffer,然后继续取下一行,并写入net_buffer
④如果发送函数返回eagain或wsaewouldblock,就表示本地网络栈(socket send buffer)写满了,进入等待,直到网络栈重新可写,再继续发送
总的来说,查询结果是分段发给客户端的,因此扫描全表,查询返回大量的数据,并不会把内存打爆
2.全表扫描对innodb层的影响-内存命中率
①innodb buffer pool 的大小是由参数 innodb_buffer_pool_size确定的,一般设置成物理内存的 60%-80%。
当buffer pool满了,而又要从磁盘读入一个数据页,肯定会要淘汰一个旧的数据页
②innodb内存管理使用最近最少使用(Least Recently Used,LRU)算法,核心就是淘汰最久未使用的数据,基于链表实现
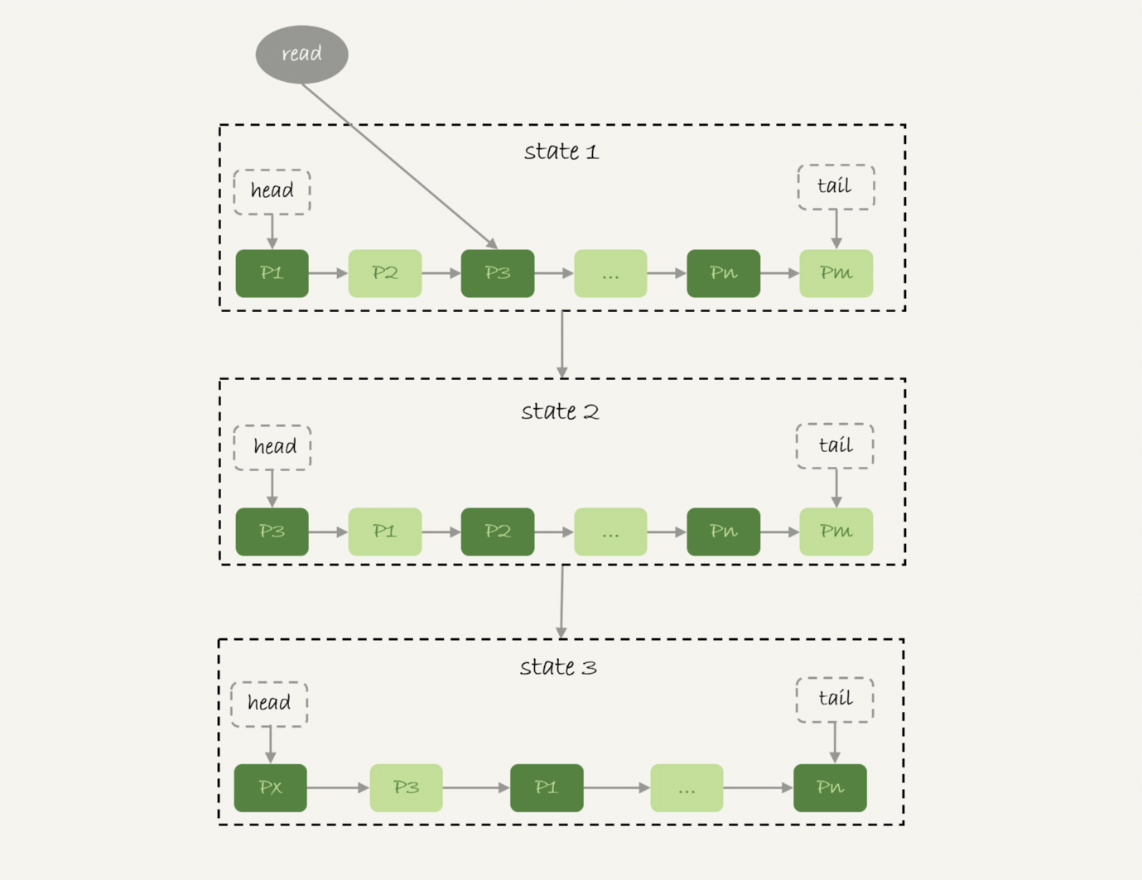
a)链表头部是P1,表示P1是最近被访问的数据页
b)此时有一个读请求访问P3,因此状态变成state2,P3放在链表头部
c)state3表示,此时有一个未在内存中的数据页Px被访问到了,将Px放入到头部,由于内存的大小固定,因此将Pm清除掉
这个做法存在的问题:
当做一个全表扫描时,如果整个表的数据量非常大,就会把当前buffer pool中的数据全部淘汰,存入扫描过程中访问到的数据页的内容
对于一个线上在做业务服务的库来说,会导致内存命中率急剧降低,磁盘的压力增加,SQL语句的响应变慢
所以说,innodb并没有直接采用这种算法,而是对它进行了优化
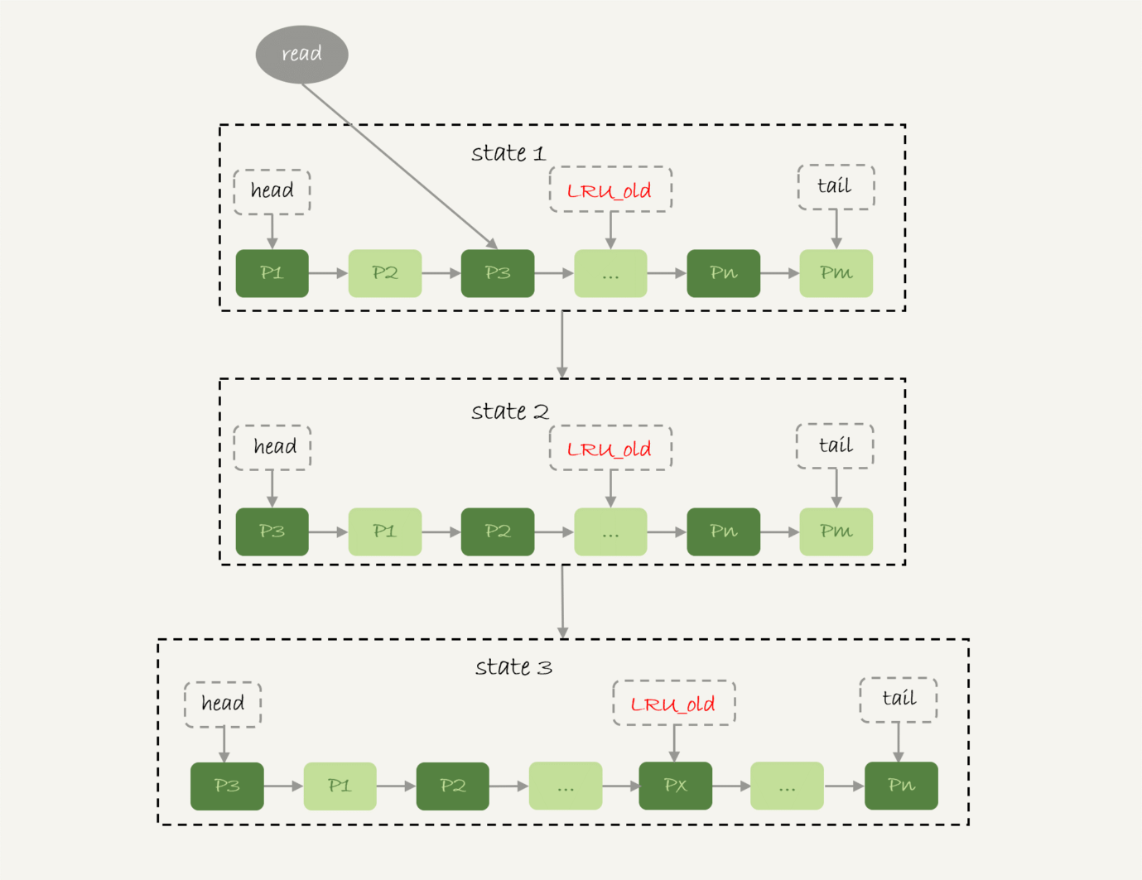
innodb按照5:3的比例把整个LRU链表分成了young区域和old区域,靠近链表头部的是young区域,靠近链表尾部的是old区域
a)当访问young区域的P3时,将P3移动到链表头部
b)当访问一个不存在当前链表的数据页Px,这时候是淘汰掉Pm,将Px放入到LRU的old区域
c)处于old区域的数据页,每次访问都需要做下面的判断:
如果这个数据页在LRU链表中存在的时间超过了1秒,就把它移到链表头部;
如果这个数据页在LRU链表中存在的时间短于1秒,位置保持不变;
1秒的时间,由参数innodb_old_blocks_time控制,默认是1000毫秒
当做全表扫描的时候,一个数据页里面有多条记录,这个数据页会被多次访问到,但由于是顺序扫描,这个数据页第一次被访问和最后一次被访问的时间间隔不会超过1s,
还是会被保留在old区域,再扫描后续的数据,之前的这个数据页也不会再被访问到,也就没有机会被移到链表的头部,从而保证了buffer pool的命中率
六、临时表、group by
1.临时表与内存表的区别
①临时表可以使用各种引擎类型,如果使用innodb引擎或者myisam引擎的临时表,写数据是写到磁盘上的,当然也可以使用memory引擎
②内存表指的是使用memory引擎的表,表数据都保存在内存中,系统重启的时候会被清空,但是表结构还存在
③临时表建表:create temporary table ...
内存表建表:create table ... engine=memory
2.临时表的特点
①一个临时表只能被创建它的session访问,对其他线程不可见
②临时表可以和普通表同名,如果session A中有同名的临时表和普通表,增删改查语句访问的是临时表
③show tables 不显示临时表
④在binlog_format='row'的时候,临时表的操作不记录到binlog中
3.临时表的分类
①用户临时表:用户手动创建的临时表,参考join优化
②内存临时表:MySQL自己使用
4.内部临时表的使用场景
①union执行流程
例子:t1在(0,1000]区间
(select 1000 as f) union (select id from t1 order by id desc limit 2);
union是取两个子查询结果的并集,重复的行只保留一行
a)创建一个内存临时表,这个临时表只有一个整型字段f,并且f是主键字段
b)执行第一个子查询,得到1000这个值,并存入临时表中
c)执行第二个子查询,拿到第一行id=1000,试图插入临时表中,但是1000这个值已经存在于临时表中,违反了唯一性约束,所以插入失败,然后继续执行;
取到第二行id=999,插入临时表成功
可以看出,这里的内存临时表起到了暂存数据的作用,而且还用上了临时表主键id的唯一性约束,实现了union的语义
如果把union改成union all,就没有去重的语义。这样执行过程就不需要临时表了
②group by执行流程
例子:
create table t1(id int primary key, a int, b int, index(a));
select id%10 as m, count(*) as c from t1 group by m;
a)创建内存临时表,表里有两个字段m和c,主键是m
b)扫描表t1的索引a,依次取出叶子节点上的id值,计算id%10的结果,记为x;
如果临时表中没有主键为x的行,就插入一条记录(x,1)
如果临时表中有主键为x的行,就将x这一行的c值加1
c)遍历完成后,再根据字段m做排序,得到结果集返回给客户端(如果不需要排序,增加order by null)
如果内存临时表放不下这么多数据,则转成磁盘临时表(默认innodb引擎)
③group by优化----索引
group by的语义逻辑,是统计不同的值出现的个数,但是由于id%100的结果是无序的,所以会需要一个临时表,来记录并统计结果
而扫描过程中可以保证出现的数据是有序的,就可以不需要临时表,即可以使用innodb的索引来实现:
当碰到第一个1的时候,就已经知道累积了X个0,结果集里的第一行就是(0,X)
当碰到第二个2的时候,就已经知道累积了Y个1,结果集里的第一行就是(1,Y)
按照这个逻辑执行的话,扫描到整个数据结束,就可以拿到group by的结果,不需要临时表,也不需要排序
增加新字段及索引:alter table t1 add column z int generated always as(id % 10), add index(z);
使用新字段索引:select z, count(*) as c from t1 group by z;
③group by优化----直接排序
如果不适合建索引,还是需要做排序;
当我们明知道一个group by语句要放到临时表上的数据量比较大,还要先放到内存临时表,插入一部分数据后,发现内存临时表不够用再转成磁盘临时表,无疑会非常傻。
此时,可以采用直接走磁盘临时表的方法:
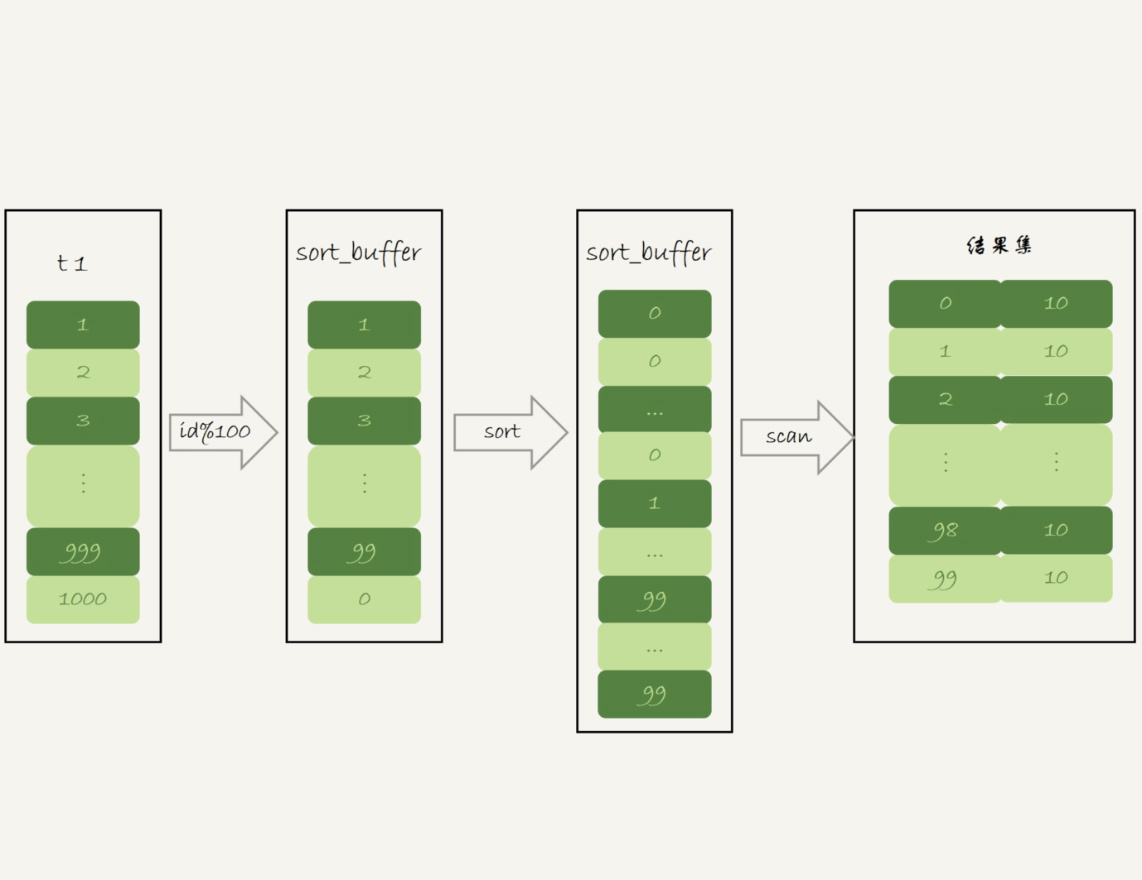
select SQL_BIG_RESULT id%100 as m, count(*) as c from t1 group by m;
a)初始化sort buffer,确定放入一个整型字段,记为m
b)扫描t1的索引a,依次取出里面的id值,将id%100的值存入sort buffer 中
c)扫描完成后,对sort buffer中的字段m排序(如果sort buffer内存不够用,就会利用磁盘临时文件进行排序)
d)排序完成后,就得到一个有序数组,根据有序数组,得到数组里面的不同值,以及每个值的出现次数
总的来说,MySQL会在以下情况使用内部临时表
a)如果语句执行过程可以一边读数据,一边得到结果,是不需要额外的内存的,否则就需要额外的内存,来保存中间结果
b)join_buffer是无序数组,sort_buffer是有序数组,临时表是二维表结构
c)如果执行逻辑需要用到二维表特性,就会优先考虑使用临时表。比如,union需要使用唯一索引约束,group by还需要用到另一个字段来存累积计数
六、distinct 与 group by
问:如果只需要去重,不使用聚合函数和排序,group by和distinct的性能有啥区别?
例子:
select a from t group by a order by null;
select distinct a from t;
答:没有区别,语义相同,执行过程相同
执行过程:
①创建一个临时表,临时表有一个字段a,并且在字段a上创建一个唯一索引
②遍历表t,依次将数据插入到临时表中
③如果发现唯一键冲突,则跳过,否则插入
④遍历完成,将临时表作为结果集返回给客户端














 3118
3118











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









