






目前抖音开放了网页版,可以直接通过打开链接就能观看视频,但是我们作为视频剪辑专业户,希望能批量下载视频。
我们以代古拉k作品主页为例,地址:
本节操作需要具备一定HTML+JS的基础能力,否则看不懂,因为这里只提供思路,不直接提供源代码,希望你耗子尾汁。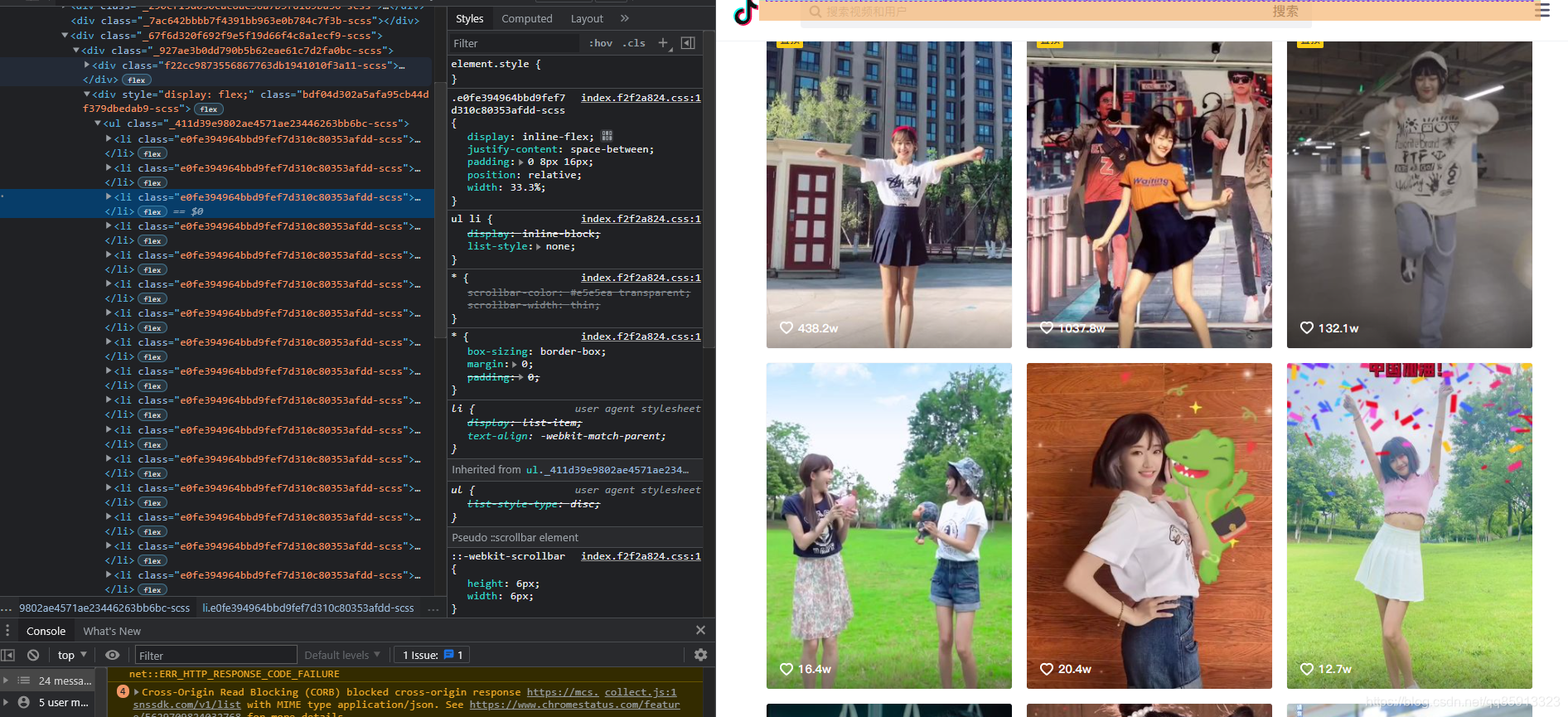
通过上图可以看到,它的每个视频都是li标签,并且class名都一样,我们可以通过命令
document.getElementsByClassName("e0fe394964bbd9fef7d310c80353afdd-scss")
获取到它当前页面加载的所有作品,有人可能会问,那我想下载全部作品怎么办?
那简单,因为它采用滑动式加载的视频,无需翻页,可以直接往下滚动,滚动出所有作品(当然身为IT的我们,是通过代码来自动滚动的),之后在执行这条命令,就能获取到所有作品。
通过数组遍历出该作品的视频页面链接,以下部分代码:
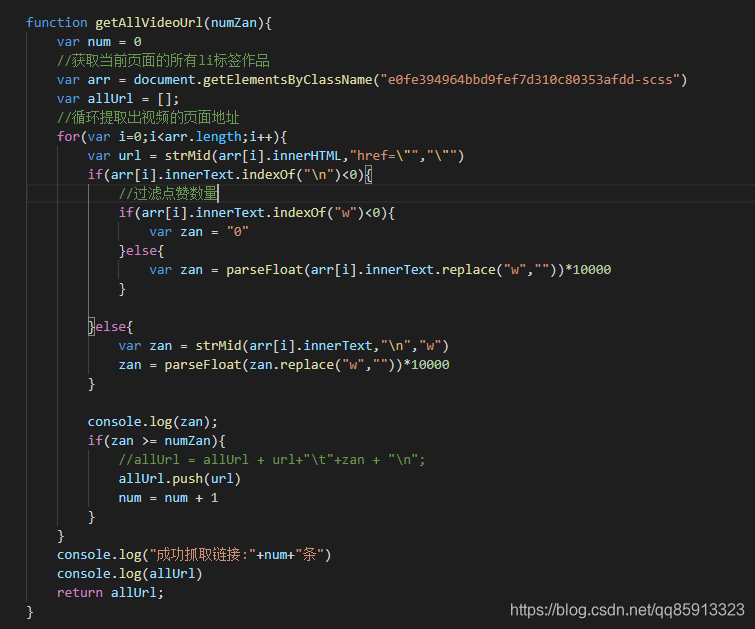
这里我还加上了获取点赞数量的判断,过滤出最低的点赞作品,打造爆款不是梦,是不是美滋滋?
如果目前你也在跟着文章内容操作,你会发现获取的链接,还不是最终的mp4链接啊,那我怎么保存成mp4视频文件?
所以到这里,事情远远还没完,我们先随便进到一个作品里面,然后查看它的mp4视频文件。
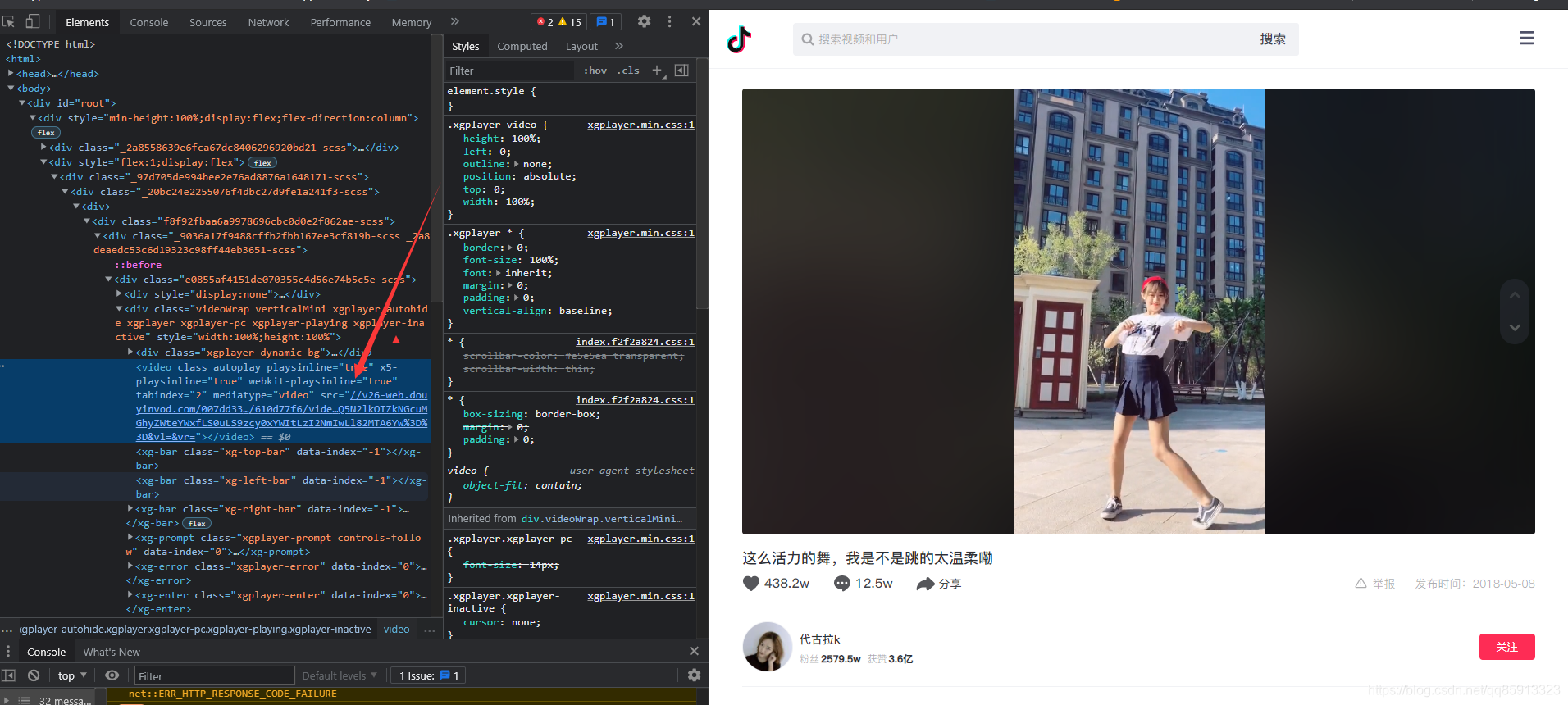
上面图标所指的地方,才是mp4最终的文件地址,我们可以通过js代码,提取出来:
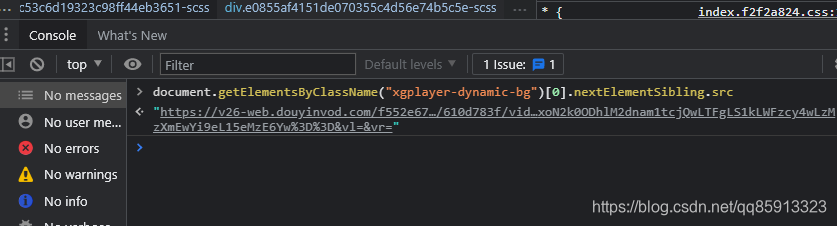
但是,如果你在编写的过程中,你是不是又发现新问题了,那我应该如何让他自动跳转到视频播放页面,又如何自动执行这行代码提取?
所以说,如果你对HTML有比较深的了解,你可以通过iframe操作,也就是在用户的作品列表里面,插入一个iframe框架,然后在通过js来加载视频详细页面,在通过js来提取出mp4链接,即可达到全自动了!!
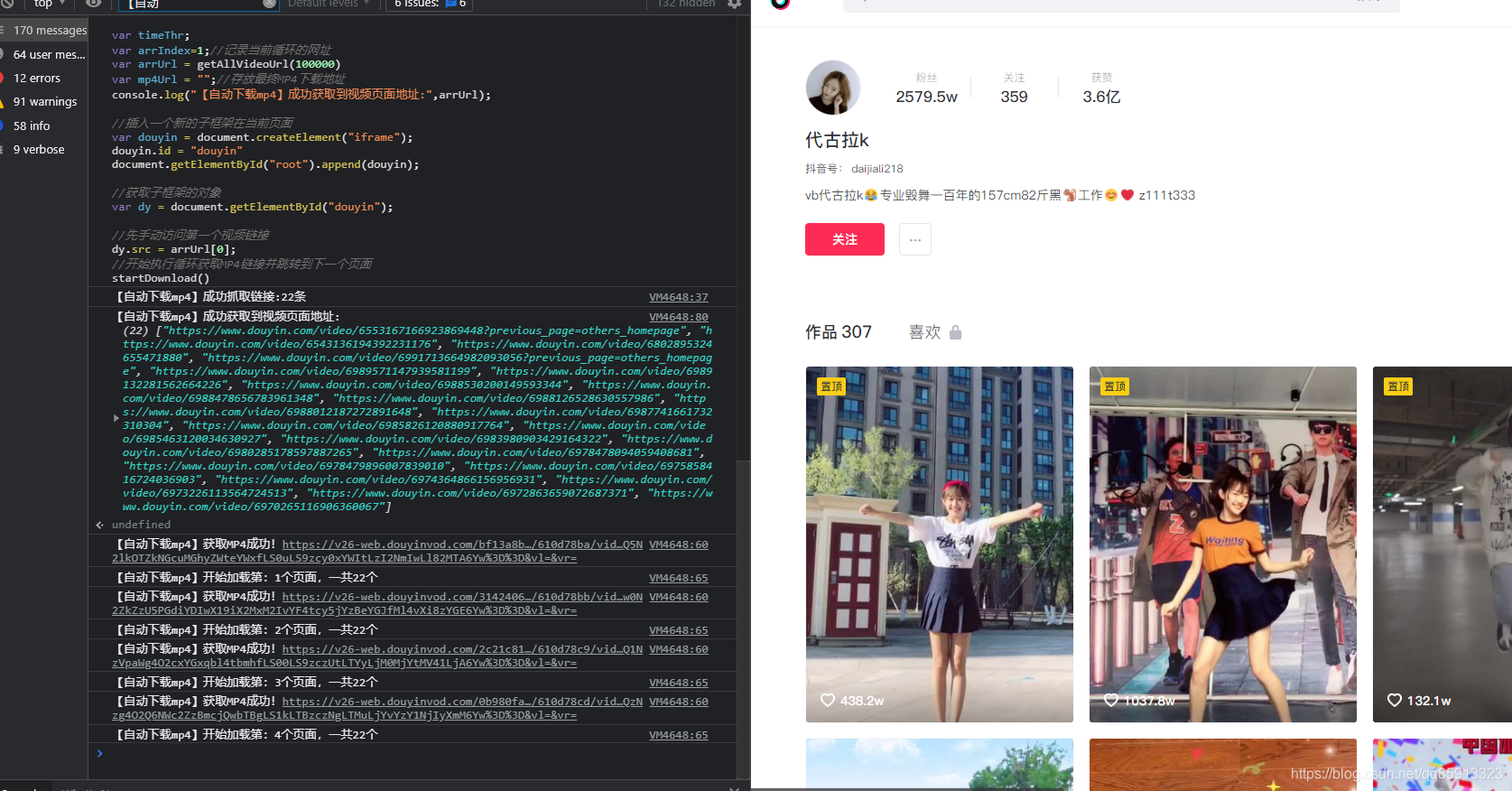
至此,我们可以看到左侧,它通过操作iframe框架来实现了全自动获取MP4播放链接,后面你就可以通过,python或者c#等其它语言将它批量保存成mp4文件啦!


















 2751
2751

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











