







集成学习( Ensemble Learning )
- 定义:集成学习是使用一系列学习器进行学习,并使用某种规则把各个学习结果进行整合从而获得比单个学习器更好的学习效果的一种机器学习方法。一般情况下,集成学习中的多个学习器都是同质的"弱学习器"。
- 介绍:机器学习在生产、科研和生活中有着广泛应用,而集成学习则是机器学习的首要热门方向。
- 思想:集成学习是训练一系列学习器,并使用某种结合策略把各个学习结果进行整合,从而获得比单个学习器更好的学习效果的一种方法。如果把单个学习器比作一个决策者的话,集成学习的方法就相当于多个决策者共同进行一项决策。集成模型不是单独的ML模型,而是通过先构建后结合多个ML模型来完成学习任务。
集成学习的两个问题
- 先构建:如何得到若干个个体学习器、弱学习器、基础学习器、基学习器(同质的,异质的,主流的)
- 后结合:如何选择一种结合策略,将这些个体学习器集合成一个强学习器
回归
Boosting:直接叠加、正则后叠加、学习法(Stacking)
Bagging :平均法、带权平均法、学习法
分类
Boosting :直接叠加、正则后叠加、学习法
Bagging :投票法、带权投票法、学习法
集成学习的两种思想
Boosting思想
- 个体学习器之间存在强依赖关系,一系列个体学习器基本都需要串行生成,然后使用组合策略,得到最终的集成模型,这就是boosting的思想

Bagging思想( Bootstrap AGGregatING )拔靴
- 个体学习器之间不存在强依赖关系,一系列个体学习器可以并行生成,然后使用组合策略,得到最终的集成模型,这就是Bagging的思想

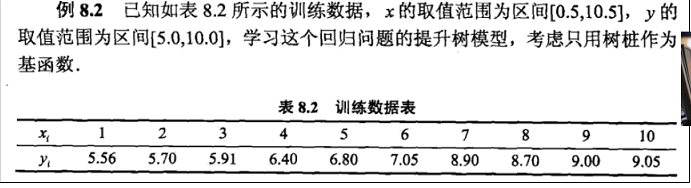
基于Bagging的回归的例题
代码实现如下
import pandas as pd
from sklearn.tree import DecisionTreeRegressor
import numpy as np
# 上述数据
df = pd.DataFrame([[1,5.56],[2,5.7],[3,5.91],[4,6.4],[5,6.8],[6,7.05],[7,8.9],[8,8.7],[9,9],[10,9.05]])
M = []# 存储决策树模型的数组
n_trees = 20 # 设置树的颗数
for i in range(20): # 训练多棵树
tmp = df.sample(frac=1,replace=True)# 对样本进行采样,目的是建造不同的树
X = tmp.iloc[:,:-1] # 构造X
Y = tmp.iloc[:,-1] # 构造Y
model = DecisionTreeRegressor(max_depth=1) # 新建决策树模型
# 将决策树模型加入数组
model.fit(X,Y)
M.append(model)
# 打印每个基础模型的效果
print(model.score(X,Y))
X = df.iloc[:,:-1]# 获取全部数据的X
Y = df.iloc[:,-1]# 获取全部数据的Y
res = np.zeros(len(X))# 初始化全零向量
for i in M: # 遍历模型数组
res += i.predict(X) #将每个模型预测值叠加到res变量
#取平均输出最终对每个样本标签的预测值
print(res/len(M))
'''
# 效果如下
0.9174312129413125
0.9933611875456895
0.8834052788835288
0.9790699506984106
0.9283118374340684
0.8590321059602172
0.9159507153079276
0.8995985226717107
0.9087798506403157
0.7801729763892038
0.9224175713033511
0.9071987434636697
0.8830137295487387
0.8597925404878746
0.893260566409407
0.9243444301530738
0.8819039973866
0.8474055206398489
0.8433414796024934
0.8164014870065539
>>[6.24846369 6.24846369 6.24846369 6.24846369 6.41153512 6.56273512
8.24609524 8.90065476 8.90065476 8.90065476]
'''















 523
523











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









