









 本文总结了四篇关于多模态个性分析的论文,探讨了视频、语音和文本三种模态在个性分析中的应用。文章详细介绍了每种模态的特征提取方法,包括OpenFace、VGG-16、3D-CNN+LSTM、word2vec+CNN、MFCC特征和BERT等,并讨论了特征融合的技术。
本文总结了四篇关于多模态个性分析的论文,探讨了视频、语音和文本三种模态在个性分析中的应用。文章详细介绍了每种模态的特征提取方法,包括OpenFace、VGG-16、3D-CNN+LSTM、word2vec+CNN、MFCC特征和BERT等,并讨论了特征融合的技术。
前言
上周我阅读了4篇关于多模态的个性分析论文,其实这些多么他的个性论文和多模态的情感分析都是一个道理,都是通过多个模态来进行分类,这是我的4篇论文的阅读笔记地址。
- Automatic Extraction of Personality from Text Challenges and Opportunities
https://blog.csdn.net/qq874455953/article/details/106441504 - Investigating Audio,Video,and Text Fusion Methods for End-to-End Automatic Personality
https://blog.csdn.net/qq874455953/article/details/106491738 - Automated Screening of Job Candidate Based on Multimodal Video Processing
https://blog.csdn.net/qq874455953/article/details/106536797 - Context-Dependent Sentiment Analysis in User-Generated Videos
https://blog.csdn.net/qq874455953/article/details/106521878
个性分析综述地址:
- Recent Trends in Deep Learning Based Personality Detection
https://blog.csdn.net/qq874455953/article/details/104762978
总结
这4篇个性分析论文都是使用三个模态,他们的整个模型框架大致相似, 如下:
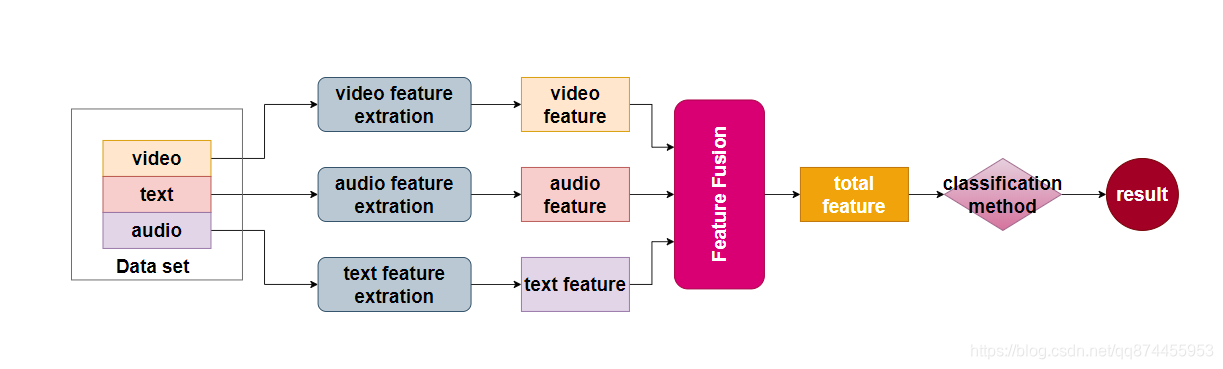
对于三模态, 视频, 语音, 文本 一般的处理步骤如下
对于video
对于video为两种做法
- 只对画面进行提取 使用过 Open Face、VGG-16的预训练模型
- 对视频进行提取 使用过: 3D-CNN + LSTM
对于text使用过:
- word2vec + CNN
- SentiWordNet 情感词标记 不是深度学习方法
- CNN + LSTM
对于audio 使用过
- MFCC特征 (较为死板, 人为制定的)
- openSmile
- 多层的CNN
对于特征提取
- 层次化特征融合 LSTM
- 多层神经感知网络 +权重
- 全连接层 连接三个模态得到的特征, 包括固定特征提取的网络参数, 和不固定特征提取的网络参数
总结
-
对于多模态的视频和语音方面的特征提取,这些方面我并不是很了解,到现在应该会有一些比较新的方法,所以我需要去找一些这些新的方法,找到他们的改进空间。
-
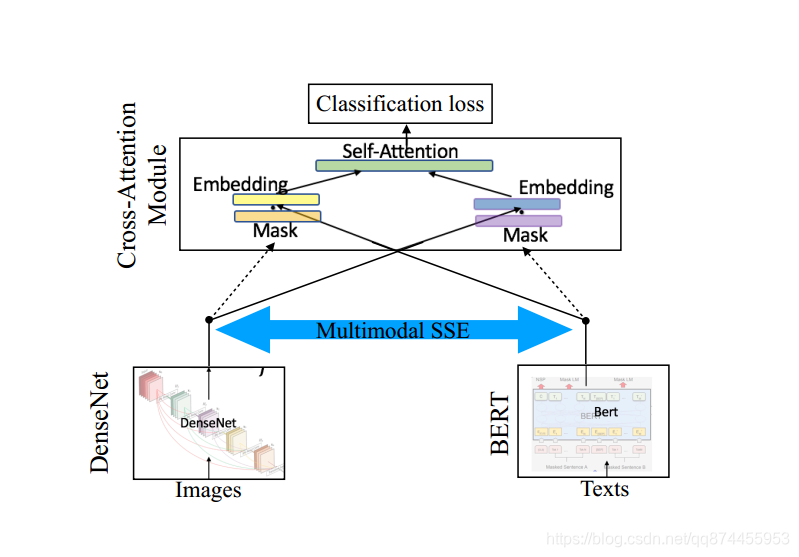
对于文本方向的特征提取,应该可以使用一些最新的模型来提高结果,例如BERT,等, 例如 在Multimodal Categorization of Crisis Events in Social Media 里面其实用到了BERT,上层加入Attention, 提升结果, 而图像方面用一些经典的方法 DenseNet ResNet等等,应该可以提升效果


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









