








虽然这篇论文的投的期刊IF不是很高,但仍有一些值得学习和借鉴的地方,2020年的最新多模态情感分析
1.模型结构
1.1 面部特征
特征提取
用OpenFace 提取68个脸部的坐标点,脸部边界(20),眼睛眉毛(22),鼻子(9),嘴巴(20)

然后对坐标点进行线性的变换,把它规划,去掉旋转角度、平移角度,得到面部的正脸照片。resize到224*224
建模
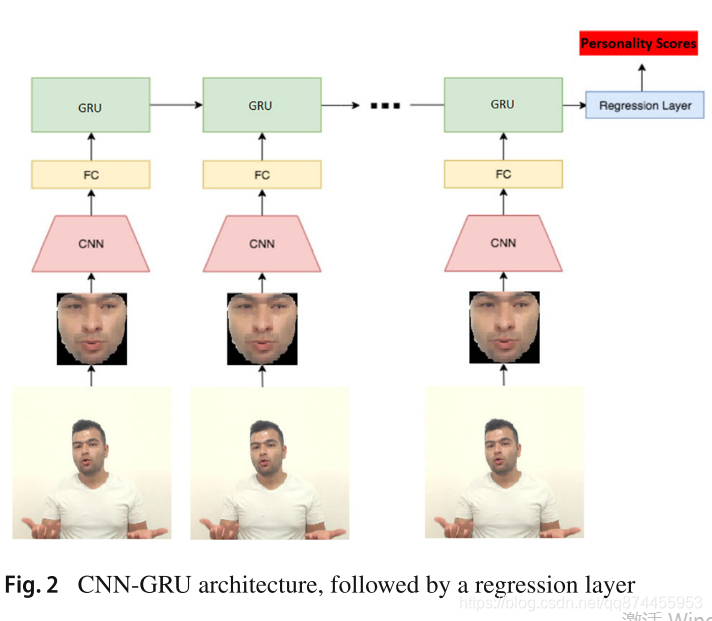
对生成的连续的人脸照片进行建模,
使用两种模型结构:
-
ResNeXt网络
-
CNN-GRU网络
其中CNN是AlexNet,
模型结构如图:
1.2 面部动作单元以及头部姿势
特征提取
使用OpenFace 提取action units (AU)
- 18个AU是否出现
- 17个AU的密度
- 3个维度的头部旋转角度(俯仰等)
- 3D gaze direction, 使用了左眼和右眼的3D注视方向(产生6个特征值)以及每只眼睛的28个眼睛标志的2D坐标(产生112个特征值)
建模
提取上面的特征,它也是作为一个持续的序列特征,所以作者采用两种网络来进行分别的建模
- LSTNet
- RCNN
1.3 身体姿态特征
特征提取
使用OpenPose对输入视频进行处理,
- 跟踪关节(如手腕和肘部)、颈部和面部的25个标记点
- 以跟踪的标记点的二维坐标作为姿态特征,如在回答问题和观看视频时如何坐和移动。
- 除了其他视觉形式,这是唯一一种我们不关注脸部的视觉形式,而是关注参与者的身体/姿势。
建模
- 使用LSTNet建模50维的身体特征,以使其最小化
1.4 声音特征
特征提取
使用pyAudioAnalysis工具提取 34维度特征 包括:
- MFCC
- Chroma vector
- energy and entropy related features
建模
- 使用LSTNet建模34维的身体特征,以使其最小化
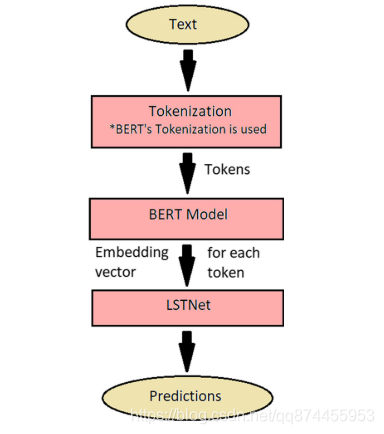
1.5 文本特征
- 用BERT 作为词嵌入
- LSTNet进行序列建模
1.6 Fusion
融合使用3种方式:early fusion,hybrid fusion,late fusion
-
early fusion:我们把每个模态最后提取的特征进行融合,有两种方式,第1种是直接拼接,第2种是基于attention的融合,
- 对于拼接我们把最后拼接的向量放到MLP中
- 对于基于attention, 首先特征过一个MLP 使得模态的特征维度相同。然后将得到的表示输入到attention 层, 得到加权特征 ,然后进行回归
hi表示 模态i 得到的特征表示
ai是权重
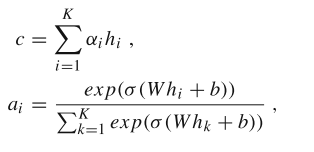
具体来说就是每个维度都进行加权
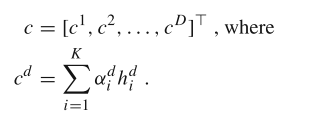
-
late fushion
把最后的得分分数平均即可 LSVR.
-
hybrid fusion
使用CentralNet, 具体可看
https://www.researchgate.net/publication/327173175_CentralNet_a_Multilayer_Approach_for_Multimodal_Fusion
2. new dataset
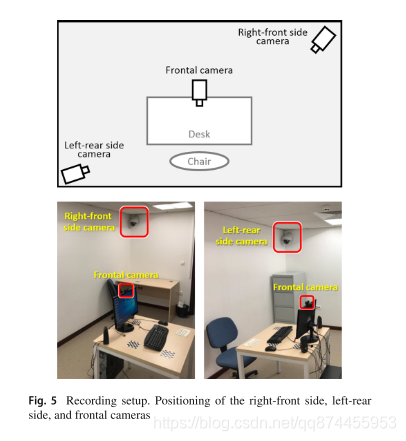
Self-presentation and induced behavior archive for personality analysis
3. 实验结果
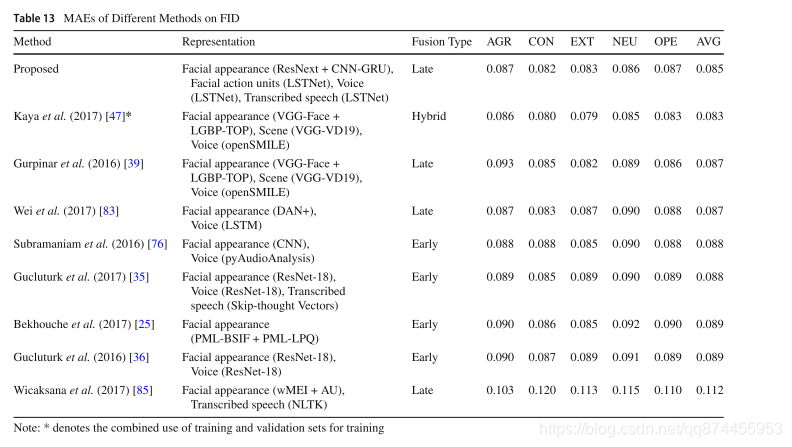
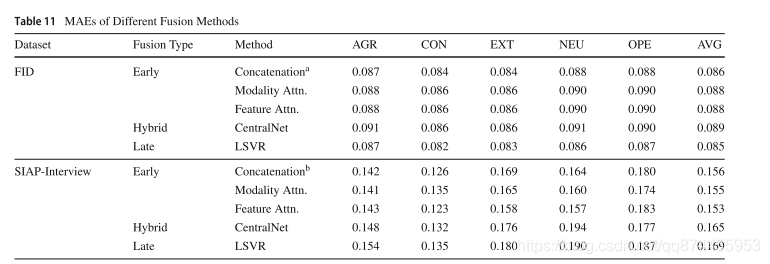
好的有点离谱, 需要查阅一下
first impression 结果论文
-
Multi-modal score fusion and decision trees for explainable automatic job candidate screening from video CVS
-
Multimodal fusion of audio, scene, and face features for first impression estimation.
-
Deep bimodal regression of apparent personality traits from short video sequences
-
Bi-modal first impressions recognition using temporally ordered deep audio and stochastic visual features.
-
Multimodal first impression analysis with deep residual networks
-
A Personality traits and job candidate screening via analyzing facial videos.
-
Deep impression: audiovisual deep residual networks for multimodal apparent personality trait recognition
-
Human-explainable features for job candidate screening prediction.
总结
-
脸部的这个效果挺不错 感觉后面可以尝试一下
-
这篇文章的优点我认为在于首先它的特征提取,非常的好,特征提取的非常的多,包括了5个方面的特征,例如脸部特征,身体自带特征,视觉特征以及声音和文本特征,
-
而它的融合的话,则使用的就是一些比较简单的方法,包括了三种融合方式
-
文章给了一个新的数据集以及自评估和其他人评估的一个区别


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









