







 本文介绍了在获取文章标题标签后,利用nltk进行分词分类,并在过程中解决Python与MongoDB交互时遇到的问题。针对Text.collocations()方法返回none的情况,通过查看源码和文档找到了解决方案,即利用_text._collocations属性存储结果。同时,为确保标签不重复添加到数据库,应用了特定的数据库操作,如文本索引和updateMany命令。测试结果显示,400多篇文章标题被快速处理并打上了标签。
本文介绍了在获取文章标题标签后,利用nltk进行分词分类,并在过程中解决Python与MongoDB交互时遇到的问题。针对Text.collocations()方法返回none的情况,通过查看源码和文档找到了解决方案,即利用_text._collocations属性存储结果。同时,为确保标签不重复添加到数据库,应用了特定的数据库操作,如文本索引和updateMany命令。测试结果显示,400多篇文章标题被快速处理并打上了标签。
紧接着之前获取完文章标题标签完之后的操作
使用完nltk分词对文章标题分类之后
延续之前的思路开始实现
过程中遇到的一些问题
获取方法的问题
python方面
如果是采用方法1手写的ngram标签采集方法,那么可以很方便的获取词频以及标签
如果是方法2,Text.collocations()方法返回的是none
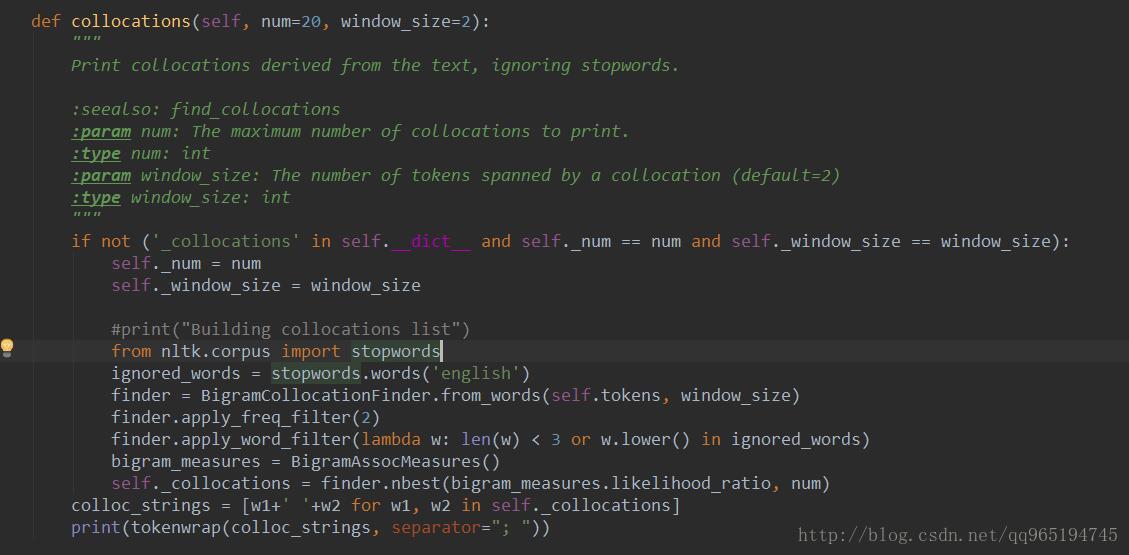
源码中可以很清楚的看到其实现用了比方法1更科学的分析方法,但是其并没有返回那个2gram集合出来,而是打印到了控制台上。
mongo方面
要求对文章标题精确检索到含有标签的,不重复的加上标签
解决方法
对于Text.collocations(),在百度获取控制台的输出无果之后,研究了两个英文文档
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 962
962

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









