







摘 要
本课题的主要目的是设计面向定向网站的网络爬虫程序,同时需要满足不同的性能要求,详细涉及到定向网络爬虫的各个细节与应用环节。
搜索引擎作为一个辅助人们检索信息的工具。但是,这些通用性搜索引擎也存在着一定的局限性。不同领域、不同背景的用户往往具有不同的检索目的和需求,通用搜索引擎所返回的结果包含大量用户不关心的网页。为了解决这个问题,一个灵活的爬虫有着无可替代的重要意义。
网络爬虫应用智能自构造技术,随着不同主题的网站,可以自动分析构造URL,去重。网络爬虫使用多线程技术,让爬虫具备更强大的抓取能力。对网络爬虫的连接网络设置连接及读取时间,避免无限制的等待。为了适应不同需求,使网络爬虫可以根据预先设定的主题实现对特定主题的爬取。研究网络爬虫的原理并实现爬虫的相关功能,并将爬去的数据清洗之后存入数据库,后期可视化显示。
关键词:网络爬虫,定向爬取,多线程,Mongodb
ABSTRACT
The main purpose of this project is to design subject-oriented web crawler process, which require to meet different performance and related to the various details of the targeted web crawler and application in detail.
Search engine is a tool to help people retrieve information. However, these general search engines also have some limitations. Users in different fields and backgrounds tend to have different purposes and needs, and the results returned by general search engines contain a large number of web pages that users don't care about. In order to solve this problem, it is of great significance for a flexible crawler.
Web crawler application of intelligent self construction technology, with the different themes of the site, you can automatically analyze the structure of URL, and cancel duplicate part. Web crawler use multi-threading technology, so that the crawler has a more powerful ability to grab. Setting connection and reading time of the network crawler is to avoid unlimited waiting. In order to adapt to the different needs, the web crawler can base on the preset themes to realize to filch the specific topics. What’s more, we should study the principle of the web crawler ,realize the relevant functions of reptiles, save the stolen data to the database after cleaning and in late achieve the visual display.
Keywords:Web crawler,Directional climb,multi-threading,mongodb
目 录
第一章 概述 1
1.1 课题背景 1
1.2 网络爬虫的历史和分类 1
第二章 文献综述 7
2.1 网络爬虫理论概述 7
2.2 网络爬虫框架介绍 8
第三章 研究方案 16
3.1 网络爬虫的模型分析 16
3.2 URL构造策略 19
3.3 数据提取与存储分析 19
第四章 网络爬虫模型的设计和实现 21
4.1 网络爬虫总体设计 21
4.2 网络爬虫具体设计 21
第五章 实验与结果分析 39
5.2 结果分析 42
参考文献 36
致谢 37
附录1 38
附录2 47
第一章 概述
1.1 课题背景
网络爬虫,是一种按照一定的规则,自动的抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁,自动索引,模拟程序或者蠕虫。
网络检索功能起于互联网内容爆炸性发展所带来的对内容检索的需求。搜索引擎不断的发展,人们的需求也在不断的提高,网络信息搜索已经成为人们每天都要进行的内容.如何使搜索引擎能时刻满足人们的需求。最初的检索功能通过索引站的方式实现,而有了网络机器人。但是,这些通用性搜索引擎也存在着一定的局限性。不同领域、不同背景的用户往往具有不同的检索目的和需求,通用搜索引擎所返回的结果包含大量用户不关心的网页。为了解决这个问题,一个灵活的爬虫有着无可替代的重要意义。
1.2 网络爬虫的历史和分类
1.2.1 网络爬虫的历史
在互联网发展初期,网站相对较少,信息查找比较容易。然而伴随互联网爆炸性的发展,普通网络用户想找到所需的资料简直如同大海捞针,这时为满足大众信息检索需求的专业搜索网站便应运而生了。
现代意义上的搜索引擎的祖先,是1990年由蒙特利尔大学学生Alan Emtage发明的Archie。虽然当时World Wide Web还未出现,但网络中文件传输还是相当频繁的,而且由于大量的文件散布在各个分散的FTP主机中,查询起来非常不便,因此Alan Archie工作原理与现在的搜索引擎已经很接近,它依靠脚本程序自动搜索网上的文件,然后对有关信息进行索引,供使用者以一定的表达式查询。由于 Archie深受用户欢迎,受其启发,美国内华达System Computing Services大学于1993年开发了另一个与之非常相似的搜索工具,不过此时的搜索工具除了索引文件外,已能检索网页。
当时,“机器人”一词在编程者中十分流行。电脑“机器人”(Computer Robot)是指某个能以人类无法达到的速度不间断地执行某项任务的软件程序。由于专门用于检索信息的“机器人”程序象蜘蛛一样在网络间爬来爬去,因此, 搜索引擎的“机器人”程序就被称为“蜘蛛”程序。世界上第一个用于监测互联网发展规模的“机器人”程序是Matthew Gray开发的World wide Web Wanderer。刚开始它只用来统计互联网上的服务器数量,后来则发展为能够检索网站域名。与Wanderer相对应,Martin Koster于1993年10月创建了ALIWEB,它是Archie的HTTP版本。ALIWEB不使用“机器人”程序,而是靠网站主动提交信息来建立 自己的链接索引,类似于现在我们熟知的Yahoo。
随着互联网的迅速发展,使得检索所有新出现的网页变得越来越困难,因此,在Matthew Gray的Wanderer基础上,一些编程者将传统的“蜘蛛”程序工作原理作了些改进。其设想是,既然所有网页都可能有连向其他网站的链接,那么从跟踪 一个网站的链接开始,就有可能检索整个互联网。到1993年底,一些基于此原理的搜索引擎开始纷纷涌现,其中以JumpStation、The World Wide Web Worm(Goto的前身,也就是今天Overture),和Repository-Based Software Engineering (RBSE) spider最负盛名。
然而JumpStation和WWW Worm只是以搜索工具在数据库中找到匹配信息的先后次序排列搜索结果,因此毫无信息关联度可言。而RBSE是第一个在搜索结果排列中引入关键字串匹配程 度概念的引擎 最早现代意义上的搜索引擎出现于1994年7月。当时Michael Mauldin将John Leavitt的蜘蛛程序接入到其索引程序中,创建了大家现在熟知的Lycos。同年4月,斯坦福(Stanford)大学的两名博士生,David Filo和美籍华人杨致远(Gerry Yang)共同创办了超级目录索引Yahoo,并成功地使搜索引擎的概念深入人心。从此搜索引擎进入了高速发展时期。目前,互联网上有名有姓的搜索引擎已 达数百家,其检索的信息量也与从前不可同日而语。比如最近风头正劲的Google,其数据库中存放的网页已达30亿之巨。
随着互联网规模的急剧膨胀,一家搜索引擎光靠自己单打独斗已无法适应目前的市场状况,因此现在搜索引擎之间开始出现了分工协作,并有了专业的搜索引 擎技术和搜索数据库服务提供商。象国外的Inktomi,它本身并不是直接面向用户的搜索引擎,但向包括Overture(原GoTo)、 LookSmart、MSN、HotBot等在内的其他搜索引擎提供全文网页搜索服务。国内的百度也属于这一类(注),搜狐和新浪用的就是它的技术。 从这个意义上说,它们是搜索引擎的搜索引擎。
1.2.2 网络爬虫的分类
网络爬虫种类繁多,如果按照部署在哪里分,可以分成:
1,服务器侧:一般是一个多线程程序,同时下载多个目标HTML,可以用PHP, Java, Python等做,一般综合搜索引擎的爬虫这样做。但是,如果对方讨厌爬虫,很可能封掉服务器的IP,服务器IP又不容易改,另外耗用的带宽也是较贵。
2,客户端:很适合部署定题爬虫,或者叫聚焦爬虫。做一个与Google,百度等竞争的综合搜索引擎成功的机会微乎其微,而垂直搜索或者竞价服务或者推 荐引擎,机会要多得多,这类爬虫不是什么页面都取的,而是只取关心的页面,而且只取页面上关心的内容,例如提取黄页信息,商品价格信息,还有提取竞争对手 广告信息的。这类爬虫可以部署很多,而且可以很有侵略性。可以低成本大量部署,由于客户端IP地址是动态的,所以很难被目标网站封锁。
1.3 网络爬虫的发展趋势
目前,大多数的搜索引擎都是基于关键词的搜索引擎。基于关键字匹配的搜索技术有较大的局限性:首先,它不能区分同形异义。其次,不能联想到关键字的同义词。
Web商业化至今,搜索引擎始终保持着网络上被使用最多的服务项目的地位,然而,随着网上内容的爆炸式增长和内容形式花样的不断翻新,搜索引擎越来越不能满足挑剔的网民们的各种信息需求。
搜索引擎的发展面临着两大难题:一是如何跟上Internet的发展速度,二是如何为用户提供更精确的查询结果。所以,传统的引擎不能适应信息 技术的高速发展,新一代智能搜索引擎作为一种高效搜索引擎技术的在当今的网络信息时代日益引起业界人士的关注。搜索引擎己成为一个新的研究、开发领域。因为它要用到信息检索、人工智能、计算机网络、分布式处理、数据库、数据挖掘、数字图书馆、自然语言处理等多领域的理论和技术,所以具有综合性和挑战性。又 由于搜索引擎有大量的用户,有很好的经济价值,所以引起了世界各国计算机科学界和信息产业界的高度关注,目前的研究、开发十分活跃,并出现了很多值得注意的动向。
目前传统搜索引擎下,百度、谷歌等大厂商垄断了网络索引市场,因为它们的存在,日益庞大的互联网内容才能突破网络黑暗状态,变成可知的一个世界。然而,传统搜索引擎并不能支持定制搜索和信息处理、挖掘,只能以WEB1.0的形式存在。
可以预见将来互联网信息抓取、挖掘和再处理,将成为人们越来越多的需求,而满足这种需求的,就是各种各样的爬虫与相关的信息处理工具。现在网络上流 行的信息采集工具、网站聚合工具,都是未来新一代爬虫的先驱,甚至已经具备其特点。但是互联网本身,不管1.0还是2.0,还没有为爬虫时代的到来做好充分准备。现在流行的SEO,就是强势搜索引擎条件下对网站结构产生的影响。爬虫时代到来之后,互联网上会出现专门的信息站点,就是提供给爬虫看的站点。
传统的网络爬虫技术主要应用于抓取静态Web 网页,随着AJAX/Web2.0的流行,如何抓取AJAX 等动态页面成了搜索引擎急需解决的问题,因为AJAX颠覆了传统的纯HTTP 请求/响应协议机制,如果搜索引擎依旧采用“爬”的机制,是无法抓取到AJAX 页面的有效数据的。
AJAX 采用了JavaScript 驱动的异步请求/响应机制,以往的爬虫们缺乏JavaScript语义上的理解,基本上无法模拟触发JavaScript的异步调用并解析返回的异步回调逻辑和内容。
另外,在AJAX的应用中,JavaScript 会对DOM结构进行大量变动,甚至页面所有内容都通过JavaScript 直接从服务器端读取并动态绘制出来。这对习惯了DOM 结构相对不变的静态页面简直是无法理解的。由此可以看出,以往的爬虫是基于协议驱动的,而对于AJAX 这样的技术,所需要的爬虫引擎必须是基于事件驱动的。
第二章 文献综述
2.1 网络爬虫理论概述
网络爬虫是一个自动提取网页的程序,它为搜索引擎从Web上下载网页,是搜索引擎的重要组成部分。通用网络爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL列表;在抓取网页的过程中,不断从当前页面上抽取新的URL放入待爬行队列,直到满足系统的停止条件。
主题网络爬虫就是根据一定的网页分析算法过滤与主题无关的链接,保留主题相关的链接并将其放入待抓取的URL队列中;然后根据一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止。所有被网络爬虫抓取的网页将会被系统存储,进行一定的分析、过滤,并建立索引,对于主题网络爬虫来说,这一过程所得到的分析结果还可能对后续的抓取过程进行反馈和指导。
如果网页p中包含超链接l,则p称为链接l的父网页。如果超链接l指向网页t,则网页t称为子网页,又称为目标网页。
主题网络爬虫的基本思路就是按照事先给出的主题,分超链接和已经下载的网页内容,预测下一个待抓取的URL及当前网页的主题相关度,保证尽可能多地爬行、下载与主相关的网页,尽可能少地下载无关网页[1]。
2.2 网络爬虫框架介绍
2.2.1 Scrapy
Scrapy 是一套基于Twisted的异步处理框架,是纯python实现的爬虫框架,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容或者各种图片。如图2-1显示了Scrapy的大体架构,其中包含了scheduler、item pipeline、downloader、spider以及engine这几个组件模块,而其中的绿色箭头则说明了整套系统的数据处理流程。

图2-1Scrapy大体架构
组件说明:
Scrapy Engine(Scrapy引擎)
Scrapy引擎是用来控制整个系统的数据处理流程,并进行事务处理的触发。更多的详细内容可以看下面的数据处理流程。
Scheduler(调度)
调度程序从Scrapy引擎接受请求并排序列入队列,并在Scrapy引擎发出请求后返还给他们。
Downloader(下载器)
下载器的主要职责是抓取网页并将网页内容返还给蜘蛛( Spiders)。
Spiders(蜘蛛)
蜘蛛是有Scrapy用户自己定义用来解析网页并抓取制定URL返回的内容的类,每个蜘蛛都能处理一个域名或一组域名。换句话说就是用来定义特定网站的抓取和解析规则。
蜘蛛的整个抓取流程(周期)是这样的:
1)首先获取第一个URL的初始请求,当请求返回后调取一个回调函数。第一个请求是通过调用start_requests()方法。该方法默认从start_urls中的Url中生成请求,并执行解析来调用回调函数。
2)在回调函数中,你可以解析网页响应并返回项目对象和请求对象或两者的迭代。这些请求也将包含一个回调,然后被Scrapy下载,然后有指定的回调处理。
3)在回调函数中,你解析网站的内容,同程使用的是Xpath选择器(但是你也可以使用BeautifuSoup, lxml或其他任何你喜欢的程序),并生成解析的数据项。
4)最后,从蜘蛛返回的项目通常会进驻到项目管道。
Item Pipeline(项目管道)
项目管道的主要责任是负责处理有蜘蛛从网页中抽取的项目,他的主要任务是清晰、验证和存储数据。当页面被蜘蛛解析后,将被发送到项目管道,并经过几个特定的次序处理数据。每个项目管道的组件都是有一个简单的方法组成的Python类。他们获取了项目并执行他们的方法,同时他们还需要确定的是是否需要在项目管道中继续执行下一步或是直接丢弃掉不处理。
项目管道通常执行的过程有:
- 清洗HTML数据
- 验证解析到的数据(检查项目是否包含必要的字段)
- 检查是否是重复数据(如果重复就删除)
- 将解析到的数据存储到数据库中
Downloader middlewares(下载器中间件)
下载中间件是位于Scrapy引擎和下载器之间的钩子框架,主要是处理Scrapy引擎与下载器之间的请求及响应。它提供了一个自定义的代码的方式来拓展 Scrapy的功能。下载中间器是一个处理请求和响应的钩子框架。他是轻量级的,对Scrapy尽享全局控制的底层的系统。
Spider middlewares(蜘蛛中间件)
蜘蛛中间件是介于Scrapy引擎和蜘蛛之间的钩子框架,主要工作是处理蜘蛛的响应输入和请求输出。它提供一个自定义代码的方式来拓展Scrapy的功能。蛛中间件是一个挂接到Scrapy的蜘蛛处理机制的框架,你可以插入自定义的代码来处理发送给蜘蛛的请求和返回蜘蛛获取的响应内容和项目。
Scheduler middlewares(调度中间件)
调度中间件是介于Scrapy引擎和调度之间的中间件,主要工作是处从Scrapy引擎发送到调度的请求和响应。他提供了一个自定义的代码来拓展Scrapy的功能。
数据处理流程
Scrapy的整个数据处理流程由Scrapy引擎进行控制,其主要的运行方式为: - 引擎打开一个域名,时蜘蛛处理这个域名,并让蜘蛛获取第一个爬取的URL。
- 引擎从蜘蛛那获取第一个需要爬取的URL,然后作为请求在调度中进行调度。
- 引擎从调度那获取接下来进行爬取的页面。
- 调度将下一个爬取的URL返回给引擎,引擎将他们通过下载中间件发送到下载器。
- 当网页被下载器下载完成以后,响应内容通过下载中间件被发送到引擎。
- 引擎收到下载器的响应并将它通过蜘蛛中间件发送到蜘蛛进行处理。
- 蜘蛛处理响应并返回爬取到的项目,然后给引擎发送新的请求。
- 引擎将抓取到的项目项目管道,并向调度发送请求。
- 系统重复第二部后面的操作,直到调度中没有请求,然后断开引擎与域之间的联系[2]。
2.2.2 Xpath
它是一种用来确定XML(标准通用标记语言的子集)文档中某部分位置的语言。XPath基于XML的树状结构,提供在数据结构树中找寻节点的能力。起初 XPath 的提出的初衷是将其作为一个通用的、介于XPointer与XSLT间的语法模型。但是 XPath 用起来非常顺手很快的被开发者采用来当作小型查询语言来使用。
XPath 使用路径表达式来选取 XML 文档中的节点或者节点集。这些路径表达式和我们在常规的电脑文件系统中看到的表达式非常相似。路径表达式是从一个XML节点(当前的上下文节点)到另一个节点、或一组节点的书面步骤顺序。这些步骤以“/”字符分开,每一步有三个构成成分:
- 轴描述(用最直接的方式接近目标节点)
- 节点测试(用于筛选节点位置和名称)
- 节点描述(用于筛选节点的属性和子节点特征)
一般情况下,我们使用简写后的语法。虽然完整的轴描述是一种更加贴近人类语言,利用自然语言的单词和语法来书写的描述方式,但是相比之下也更加啰嗦[3]。
2.2.3 Mongodb
对于大数据量、高并发、弱事务的互联网应用,MongoDB则是一个如瑞士军刀般的利剑。
例如:为了产品中的某个实体的查询操作,我们需要把一个本属于该实体的数据拆分至另一个表中,以便进行连接查询。于是无论是创建,删除还是更新,我们要涉及的操作便增加了许多。更别说互联网项目时刻都在发展和变动,改变一个存储单元结果是常事,至今关系型数据库的在线模式更新依旧不是件简单的事情。
选择MongoDB,是因为它的集合支持松散的模式,易于灵活调整;支持复杂的属性,并可为之建立索引,作为查询条件。
MongoDB的系统管理员上辈子是折翼的天使,使他们牺牲自己,方便了整个团队
2.3 数据可视化
2.3.1 Laravel
Laravel是一套web应用开发框架,它具有富于表达性且简洁的语法。我们相信,开发过程应该是愉悦、创造性的体验。Laravel努力剔除开发过程中的痛苦,因此我们提供了验证(authentication)、路由(routing)、session和缓存(caching)等开发过程中经常用到的工具或功能。
Laravel的目标是给开发者创造一个愉快的开发过程,并且不牺牲应用的功能性。快乐的开发者才能创造最棒的代码!为了这个目的,我们博取众框架之长处集中到Laravel中,这些框架甚至是基于Ruby on Rails、ASP.NET MVC、和Sinatra等开发语言或工具的。
Laravel是易于理解并且强大的,它提供了强大的工具用以开发大型、健壮的应用。杰出的IoC、数据库迁移工具和紧密集成的单元测试支持,这些工具赋予你构建任何应用的能力。我学习过很多框架,但laravel是目前最前面最灵活的一个,所以选择此框架完成数据可视化。
2.3.2 Bootstrap
Bootstrap 是一个用于快速开发 Web 应用程序和网站的前端框架。在现代 Web 开发中,有几个几乎所有的 Web 项目中都需要的组件。Bootstrap 为您提供了所有这些基本的模块 - Grid、Typography、Tables、Forms、Buttons 和 Responsiveness。此外,还有大量其他有用的前端组件,比如 Dropdowns、Navigation、Modals、Typehead、Pagination、Carousal、Breadcrumb、Tab、Thumbnails、Headers 等等。有了这些,你可以搭建一个 Web 项目,并让它运行地更快速更轻松。此外,由于整个框架是基于模块的,您可以通过您自己的 CSS 位,甚至是项目开始后的一个大整改,来进行自定义。
它是基于几种最佳实践,我们认为这是一个很好的开始学习现代 Web 开发的时机,一旦您掌握了 HTML 和 JavaScript/jQuery 的基本知识,您就可以在 Web 开发中运用这些知识。虽然,也有批评,所有通过 Bootstrap 构建的项目看起来相同,您可以不需要知道太多的 HTML + CSS 知识就可以构建一个网站。但是,我们需要明白,Bootstrap 是一个通用的框架,就像任何其他通用的东西,您需要定制才能让它具有独特性。当您要定制时,您需要深入研究,没有良好的 HTML + CSS 基础是不可行的[4]。
当然除了 Bootstrap,还有很多其他好的前端框架,但是laravel与Bootstrap就是绝配,在之前开发过的几个项目中,Bootstrap的前台效果惊艳绝伦。
第三章 研究方案
3.1 网络爬虫的模型分析
本网络爬虫的开发目的,通过网络爬虫技术一个自动提取网页的程序,实现搜索引擎从自己想访问的网上下载网页,再根据已下载的网页上继续访问其它的网页,并将其下载直到满足用户的需求。
根据现实中不同用户的实际上的各种需求,本项目简单实现主题爬虫,本网络爬虫需要达到如下几个目标:
- 设计基于多线程的网络爬虫,客户端向服务器发送自己设定好请求。如图3-1所示

图3-1 多线程网络爬虫概要设计图模型
- 通过 http将Web服务器上协议站点的网页代码提取出来。
- 根据xpath提取出客户端所需要的信息。
- 通过构造url发起新的http请求。
本网络爬虫最终将设计成一个能够在后台自动执行的网络爬虫程序。网络爬虫工作流程图如图3-2所示。

图3-2 网络爬虫工作流程图
3.2 URL构造策略
目标网站URL:www.jb51.net
爬取文章URL:www.jb51.net/article/1.htm
根据网站自身的特性我们为该网站(脚本之家),设计了自动构造URL。我们发现网站的后缀中,最后一位数字表示了该网页的唯一标示。我们一次为基准,初始化变量控制爬取范围。通过字符串拼接来构造在爬取范围内的URL,并自动修改配置文件中的变量。
3.3 数据提取与存储分析
为了便于提取数据我们对目标网站进行了简要的分析。爬取文章URL:www.jb51.net/article/1.htm。打开所爬取的任意网页,按F12打开调试窗口可见如图3-3,然后锁定所要提取信息的class一遍在xpath中进行定位。

图3-3 目标网站网页图
首次存储信息。我们选择mongodb数据库,它属于Nosql。不需要解析sql语句,执行速度非常快。对于我们这个依赖关系比较若得项目非常实用。在后期的可视化中我们会加入RBAC机制,所以在在依赖关系上会显得比较复杂。为了方便我们在可视化中使用MySQL。但是从Mongodb数据库中将数据导入MySQL又是一个比较棘手的问题。因为自带CSV方式或者json方式在单个字段过大的情况下都显得很乏力。很多时候都会造成数据的截取,丢失,有时就连字符编码不统一都会出现乱码的情况。不得已我们需要自己编写数据转换脚本程序,已完成数据的全面转换。
3.4 可视化显示与搜索策略
1)可视化框架
为了将导入MySQL中的数据做一些简单的应用,我们将其通过网页的形式可视化,我们选用的是目前国外最火的Laravel、Bootstrap框架,laravel用于后台逻辑控制,bootstrap用于前台友好的显示。网页的结构我们依旧选用经典的MVC结构,有底层操作数据库的模型,控制模型的控制器,和显示层。
2)搜索策略
在web中我们加入了搜索功能,多个字段的模糊搜索。但是有多搜索字段过多,MySQL对于中文的模糊搜索做的很不尽人意。当然也有解决方案,要么放弃MySQL,或者使用插件sphinx,建立分词查询机制,这样就可以在大数据中快速的模糊查询中文关键词了。由于文章的特性我们分别为数据库中的“title”、“tag”、“desc”建立模糊查询,以提高搜索的精准度,但是会增加我们服务器的压力。所以我们只能用硬件来换取软件上的缺陷了。
第四章 网络爬虫模型的设计和实现
4.1 网络爬虫总体设计
根据本网络爬虫的概要设计本网络爬虫是一个自动提取网页的程序,根据设定的主题判断是否与主题相关,再根据配置文件中的页面配置继续访问其它的网页,并将其下载直到满足用户的需求。
1)设计基于多线程的网络爬虫的基本配置。
2)通过 http将自动构造的URL中的网页代码提取出来。
3)提取出所需要的信息并且通过管道技术将其存储之mongodb中。
4)通过url构造算法自动构造下一个URL,再通过递归算法实现下一URL的访问,重复以上步骤。
总的来说爬虫程序根据配置获得初始URL种子,把初始种子保存在临界区中,按照构造URL算法,自动构造URL,返回到临届区中,判断是否继续,从而使整个爬虫程序循环运行下去。
4.2 网络爬虫具体设计
4.2.1 爬取网页
主要用到的技术如下:
- 继承scrapy.Spider类,通过scrapy.Spider内部封装的start_requests()方法。该方法默认从start_urls中的Url中生成请求,初始化地址:www.jb51.net/article/80000.htm,并执行解析来调用回调函数函数。设置爬虫爬取域名范围:script:start_urls,可构造url原模型,设置爬取网页范围80000~85000,后期作为拼接新的URL使用,引入ITEM文件,作为保存数据模型的容器。
#主要代码如下:
import scrapy
from script_2.items import Script2Item
from scrapy.http import Request
class src2Spider(scrapy.Spider):
name = ‘script_2’
redis_key = ‘script:start_urls’
start_urls= [‘http://www.jb51.net/article/80000.htm’
url = ‘http://www.jb51.net/article/’
pageNum = 80000
2)设置连接延迟(AUTHTHROTTLE_START_DELAY)时间为5秒,超时时间(AUTOTHROTTLE_MAX_DELAY)设置为60,如果连接超时,则自动跳过该页面,并在shell端显示出提示信息,自适应排错(AUTHTHROTTLE_DEBUG)功能如果出现404或505等未知错误,自动处理,将程序设为工厂模式。配置mongodb的连接信息,并在本地打开mongodb服务器端,供后期数据存储使用,引入管道文件(script_2.pipelines.Script2Pipeline)为其他文件使用,初始化Spider模型,并为递归初始化自身模型’script_2.spiders’
#主要代码如下:
BOT_NAME = ‘script_2’
SPIDER_MODULES = [‘script_2.spiders’]
NEWSPIDER_MODULE = ‘script_2.spiders’
ITEM_PIPELINES = [‘script_2.pipelines.Script2Pipeline’]
#mongodb config
MONGODB_HOST = ‘127.0.0.1’
MONGODB_PORT = 27017
MONGODB_DBNAME = ‘script’
MONGODB_DOCNAME = ‘script_8’
The initial download delay
AUTOTHROTTLE_START_DELAY=5
Enable showing throttling stats for every response received:
AUTOTHROTTLE_DEBUG=Ture
The maximum download delay to be set in case of high latencies
AUTOTHROTTLE_MAX_DELAY=60
4.2.2 提取网页信息
算法实现步骤和算法描述:
Parse是Spider默认调用函数,start_requests()方法会将下载下来的网页信息,以response类为参数的方式传入该函数。使用的是Xpath选择器,首先实例化选择器,并将下载器下载到的response作为初始参数传入选择器,通过选择器中的xpath方法,提取出我们所需要的信息,使用extract()方法将其文本化,然后返回存储至python变量中。
#主要代码如下:
def parse(self, response):
sel = scrapy.selector.Selector(response)
title = sel.xpath(‘//div[@class=“title”]/h1/text()’).extract()
desc = sel.xpath(‘//div[@id=“art_demo”]/text()’).extract()
content = sel.xpath(‘//div[@id=“content”]’).extract()
tag = sel.xpath(‘//div[@class=“tags mt10”]/a/text()’).extract()
4.2.3 自动构造URL
判断目前爬取页面(pageNum)是否在允许爬取范围内(total),如果是,修改配置信息pageNum,利用初始化url模型拼接出新的URL(new_url),并调用,Request()方法递归的调用自身,再次爬取新的内容,直到将允许范围内的所有页面全部爬取完毕,则停止构造,退出程序。
#主要代码如下:
pageNum = 80000
total = 85000
self.pageNum = self.pageNum + 1
if(self.pageNum < self.total):
new_url = self.url + str(self.pageNum) + “.htm”
yield Request(new_url, callback = self.parse)
4.2.4 多线程的实现
最大请求线程数(CONCURRENT_REQUESTS),通过该配置项,调度器中间件(Scheduler middlewares)会同时调取32个http请求头信息,同时发出请求,调度下载器,将下载下来的数据以response类作为参数传递给默认初始化方法parse(),由于分析数据非常简单,所以实现多线程请求,单线程分析。COOKIES_ENABLED设为开启状态,在每次的http请求中会检查js、css、图片、等静态信息,判断如果文件名相同则直接使用,不必重复下载,以此来减少网络带宽、内存、I/O系统和CPU的占用,提高爬取效率。
#主要代码如下:
Disable cookies (enabled by default)
COOKIES_ENABLED = True
Configure maximum concurrent requests performed by Scrapy (default: 16)
CONCURRENT_REQUESTS=32
4.2.5 伪造头信息和开启HTTPCACHE
1)为了防止目标网站具有反扒功能,经过单个IP的测试发现目标网站没有添加IP反扒功能,我们使用简单的代理信息就可以了。我们添加了代理信息(USER_AGENT)、头信息(DEFAULT_REQUEST_HEADERS),这两项信息会包含到http请求的头文件中,一块发送到目标网站的服务器中,既可以获得该页面的网页代码。
2)开启了http缓存(HTTPCACHE_ENABLED)机制,每次发送http请求时,则不用再去配置文件中读取配置头信息,可直接读取缓存中的http头信息,减少I/O开销,提高爬取速度。
#主要代码如下:
Crawl responsibly by identifying yourself (and your website)
on the user-agent
USER_AGENT = ‘Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_3) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.54 Safari/536.5’
Enable and configure HTTP caching (disabled by default)
HTTPCACHE_ENABLED=True
Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
‘Accept’: ‘text/html,application/xhtml+xml,application/xml;q=0.9,/;q=0.8’,
‘Accept-Language’: ‘en’,
}
4.2.6 数据库设计和存储转换
1)存储数据容器的定义:我们的容器继承于scrapy.Item类,使用scrapy.Field()方法初始化我们所需要的字段变量,我们所提取的字段一共四个,分别表示:标题(title)、描述(desc)、内容(content)、类别或标签(tag)。
#主要代码如下:
class Script2Item(scrapy.Item):
title = scrapy.Field()
desc = scrapy.Field()
content = scrapy.Field()
tag = scrapy.Field()
2)返回并增强数据适应能力:将Xpath提取出来的集合信息经过判断复制,如果为空或为假,则为其复制空字符串,tag集合中的多个集合通过join()方法,以“,”为分隔符,转换为一个集合,并使用yield返回到管道中。
#主要代码如下:
item = Script2Item()
if title:
title = title[0]
else:
title = “”
if content:
content = content[0]
else:
content = “”
if desc:
desc = desc[0]
else:
desc = “”
if tag:
tag = tag
else:
tag = “”
item[‘title’] = title
item[‘desc’] = desc
item[‘tag’] = ‘,’.join(tag)
item[‘content’] = content
yield item
3)启动mongodb服务器端:编写简单的启动bat脚本,将数据存储至,服务器目录上一文件夹中的data文件夹中,以BSON格式存储在磁盘上,每次启动真的很方便。
#主要代码如下:
mongod --dbpath …/data
4)数据处理的管道类:需要引入pymongo包才能在python中操作mongodb数据库,初始化函数(init)的编写,读出settings文件中的初始化信息,并赋予变量,用pymongo。MongoClient()方法连接到mongodb数据库,选择数据库名称(client[dbName]),选择操作表(tdb[setting[‘MONGODB_DOCNAME]]), 数据库连接完毕后,由于mongodb是以字典的形式存储的,所有将主爬虫文件返回的item容器里的信息,强制转换为字典(dict),并使用插入语句将该字典插入数据库。
5)
#主要代码如下:
from scrapy.conf import settings
import pymongo
class Script2Pipeline(object):
def init(self):
host = settings[‘MONGODB_HOST’]
port = settings[‘MONGODB_PORT’]
dbName = settings[‘MONGODB_DBNAME’]
client = pymongo.MongoClient(host=host, port=port)
tdb = client[dbName]
self.post = tdb[settings[‘MONGODB_DOCNAME’]]
def process_item(self, item, spider):
scriptInfo = dict(item)
self.post.insert(scriptInfo)
return item
5)数据存储形式转换:由于可视化中依赖关系较强,所以将Mongodb中的数据转换至MySQL中,连接Mongodb数据库,连接MySQL数据库,并取出Mongodb表里所有的信息,然后经过增强适应程序的处理后,拼接sql语句,将其插入到MySQL数据库中。
#主要代码如下:
"; }else{ echo "fail!
"; } } 4.2.7 可视化 1)首页文章智能推荐控制器:更具查询浏览量来推荐出经典文章,更具喜欢量来推荐出最好的文章,更具不同的关键字查询出不同类别的文章,并在前台友好的显示。 #主要代码如下: class IndexController extends Controller { public function index(){ $featured = Artical::where('scans', '>', '20')->orderBy('scans')->take(6)->get(); $latest = Artical::where('favorite', '>', '50')->orderBy('favorite')->take(6)->get(); $php = Artical::where('title', 'like' ,'%php%')->orderBy('favorite')->take(4)->get(); $js = Artical::where('title', 'like', '%JavaScript%')->orderBy('favorite')->take(4)->get(); $asp = Artical::where('title', 'like', '%asp%')->orderBy('favorite')->take(4)->get(); $python = Artical::where('title', 'like', '%python%')->orderBy('favorite')->take(4)->get(); $linux = Artical::where('title', 'like', '%linux%')->orderBy('favorite')->take(4)->get(); $Android = Artical::where('title', 'like', '%Android%')->orderBy('favorite')->take(4)->get(); return view('index', [ 'featured' => $featured, 'latest' => $latest, 'php' => $php, 'js' => $js, 'linux' => $linux, 'android' => $Android, 'asp' => $asp, 'python' => $python, ]); } } 2)详细页面主控制器:通过传过来的被加密的id(作为反扒机制,和安全机制的考虑),进行解密之后,在数据库中查询该文章,并返回给前台有好的显示。Search()方法,是为用户提供了良好的搜索接口。首先验证输入信息的合法性,然后通过多个字段的模糊查询,提高文章精准率,然后返回给用户。 #主要代码如下: class ArticalController extends Controller{ public function articalInfo($id){ $id = Crypt::d return view('artical', [ 'info' => $artical ]); } public function search(Request $req){ $this->validate($req, [ 'search' => 'required|max:255', ]); $info = Artical::where('title', 'like', "%".$req->search."%")->orWhere('desc', 'like', "%".$req->search."%")->orderBy('scans')->take(15)->get(); return view('artical-list', [ 'info' => $info, ]); } } ecrypt($id); $artical = Artical::findOrfail($id); 4.2.8 整体流程 1)爬虫代码文件构成如图4-1: 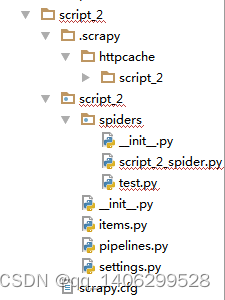 图4-1 代码结构构成截图 Script_2/.scrapy/httpcache/sript_2是提供相似http请求缓存文件。 Script_2/script_2/spiders/script_2spider.py 是主爬虫文件,发起http请求,返回网页信息,分析提取有用信息,返回构造URL。 Script_2/script_2/items.py为定义数据存储容器,存储提取出来的信息 Script_2/script_2/pipelines.py连接数据库,处理数据的管道文件,将数据插入到mongodb中。 Script_2/script_2/settings.pg自定义配置文件,根据每个爬虫的特性不同,配置文件也不同。 2)可视化代码文件构成如图4-2: 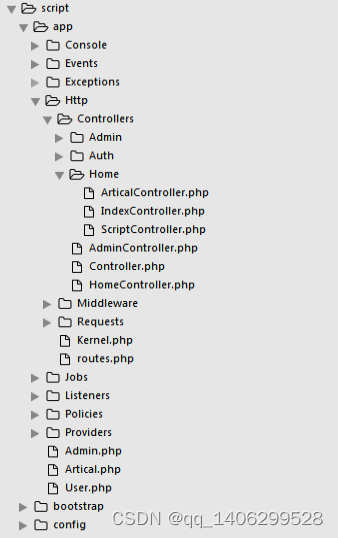 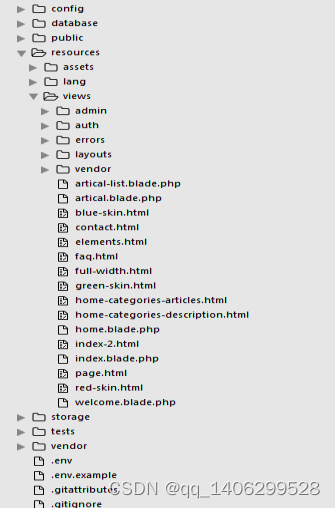  图4-2 代码结构构成截图 Script/app/Http/Controllers是整个可视化项目里的控制器模块。 Script/app/Http/route.php是整个想项目的路由文件,所有的所有接口都编写在该文件中。 Script/app/Artical.php、Admin.php、User.php是项目里的部分重要的模型 Script/public/js、css、image、为整个项目的图片、js、css文件存储的地方,为整个前台提供各种静态文件。 Scriptt/resources/views是整个可视化项目里的前台静态页面,通过后台传递过来的数据,和js的控制,使得前台页面更有生机。 Script/composer.json是项目里各种依赖包管理文件,可以随时导入新的依赖包。 具体流程: 第一步: 调用script_2spider.py主爬虫文件,获得配置信息中的内容,然后开始爬取。 第二步:将爬取到的网页信息以response类的形式,传递给默认方法parse(),parse方法提取出有效信息,然后存储到Item容器中。 第三步:管道文件(pipelines.py)连接mongodb数据库,将Item中的数据插入到数据库中。 第四步:主爬虫文件返回数据后,进入自动构造URL模块,判断是否在爬取范围内后,继续构造URL,并使用Request()方法,以自身为回调函数,继续爬取新的URL,知道没有新的URL产生为止。 第五步:编写数据转换脚本程序将mongodb中各个表中的数据,转换存储至MySQL中。 第六步:编写现实化模块,调用MySQL中的数据,并提供简单的推荐模块,和精准的搜索模块。 ## 第五章 实验与结果分析 5.1实验测试 1)在shell窗口开启爬虫命令如下:程序运行后的界面如图5-1 #主要代码如下: Scrapy crawl script_2  图5-1 测试图1爬虫爬取页面 2)开启mongodb数据库查看爬取数据,总数据可见如图5-2: 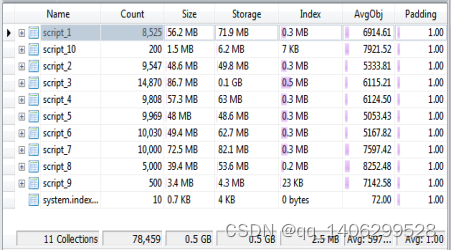 图5-2 测试图2mongodb数据库总数据展示 3)详细表格数据可见如图5-3: 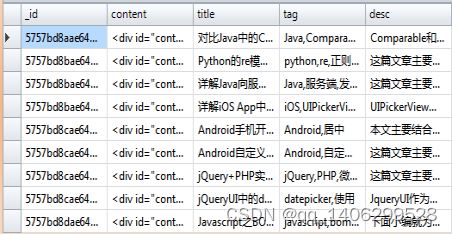 5-3 测试图3mongodb数据库详细数据展示 4)在本地存储格式可见如图5-4:  图5-4 测试图4本地json存储格式 5)MySQL数据库中表格形式展示数据可见如图5-5: 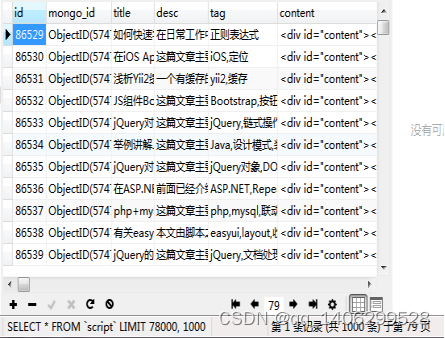 图5-5 测试图5mysql数据库存储详细图 : 5.2 结果分析 爬取参数: 爬取网页数目为:50 爬取环境 :Windows 存储数据库:Mongodb 带宽:50M 爬取时间相差不超过五分钟 5.2.1多线程与单线程比较 依据变量控制法,改变请求线程数(CONCURRENT_REQUEST = 1),用时约为27秒,实验结果可见如图5-6: 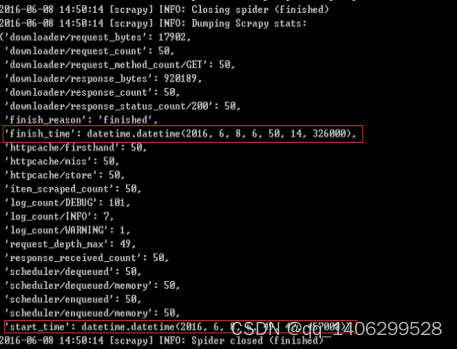 图5-6 测试图6改变请求线程数 依据变量控制法,改变请求线程数(CONCURRENT_REQUEST = 32),用时约为26秒,实验结果可见如图5-7: 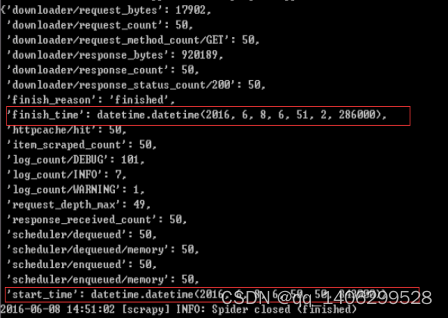 图5-7 测试图7改变请求线程数 5.2.2开启HTTPCHACE与不开启HTTPCACHE比较 依据变量控制法,改变http请求缓存(HTTPCHACE = False),用时约为18秒,实验结果可见如图5-8: 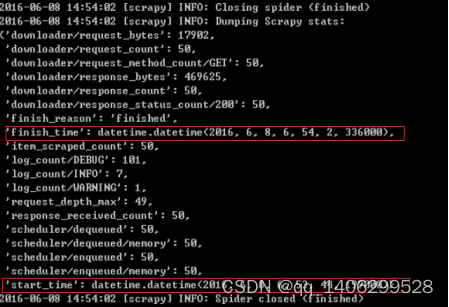 图5-8 测试图8改变http请求缓存 依据变量控制法,改变http请求缓存(HTTPCHACE = True),用时约为11秒,实验结果可见如图5-9: 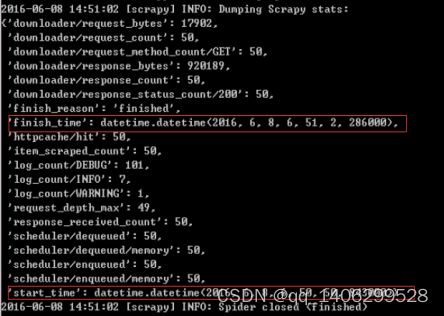 图5-9 测试图9改变http请求缓存 5.2.3开启COOKIES_ENABLE与不开启COOKIES_ENABLE比较 依据变量控制法,改变http请求不直接读取缓存数据(COOKIES_ENABLE = False),用时约为12秒,实验结果可见如图5-10: 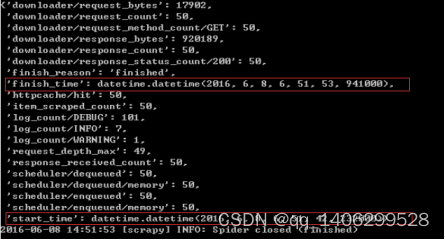 图5-10 测试图10改变http请求不直接读取缓存数据 依据变量控制法,改变http请求直接读取缓存数据(COOKIES_ENABLE = True),用时约为11秒,实验结果可见如图5-11:  图5-11 测试图11改变http请求直接读取缓存数据 总结:综上数据是在较为公平的环境下测试的,但数据量较小,仅代表个人测试。综上数据可得,在多线程与单线程、COOKIE_ENABLE开启与不开启的比较中,虽然不是非常明显,但是也有所差距,当在大量的数据爬取工程中会显得更为实用。开启HTTPCACHE与不开启HTTPCACHE在爬取速度上有着较明的比较,速度提高了五分之二,如果在大量的数据爬取中则显得尤为重要。 ## 第六章 总结和展望 2016年4月,我开始了我的毕业论文工作,时至今日,论文基本完成。从最初的茫然,到慢慢的进入状态,再到对思路逐渐的清晰,整个开发过程难以用语言 来表达。历经了几个月的奋战,紧张而又充实的毕业设计终于落下了帷幕。回想这段日子的经历和感受,我感慨万千,在这次毕业设计的过程中,我拥有了无数难忘的回忆和收获。 4月初,在与导师的交流讨论中我的题目定了下来,是面向主题的网络爬虫。当选题报告,开题报告定下来的时候,我当时便立刻坠入着手资料的收集工作中,当时面对浩瀚的书海真是有些茫然,不知如何下手。我将这一困难告诉了导师,在导师细心的指导下,终于使我对自己现在的开发方向和方法有了掌握。 在搜集资料的过程中。我在学校图书馆,360图书馆搜集资料,还在网上查找各类相关资料,将这些宝贵的资料全部记在电脑上,尽量使我的资料完整、精确、数量多,这有利于论文的撰写。然后我将收集到的资料仔细整理分类,及时拿给导师进行沟通。 4月中,资料已经查找完毕了,我开始着手论文的写作。在写作过程中遇到困难我就及时和导师联系,并和同学互相交流,请教专业课老师。在大家的帮助下,困难一个一个解决掉,论文也慢慢成型。 4月底,平台设计已经完成。5月开始相关代码编写工作。为了完成满意的项目设计,我仔细温习了计算机网络的相关知识。深入了解并掌握网络协议基础知识,挖掘出计算机网络课程中的难点和重点。在设计平台中,要注意平台的可行性和有效性,选择既重要又适合,以软件工程中出现的知识点作为材料,参考优秀的国内外学习辅助平台,又考虑到计算机网络课程的特殊性。在设计初期,由于没有设计经验,觉得无从下手,空有很多设计思想,却不知道应该选哪个,经过导师的指导,我的设计渐渐有了头绪,通过查阅资料,逐渐确立系统方案。在整个过程中,我学到了新知识,增长了见识。 在今后的日子里,我仍然要不断地充实自己,争取在所学领域有所作为。 脚踏实地,认真严谨,实事求是的学习态度,不怕困难、坚持不懈、吃苦耐劳的精神是我在这次设计中最大的收益。我想这是一次意志的磨练,是对我实际能力的一次提升,也会对我未来的学习和工作有很大的帮助。 ## 参考文献 [1]http://baike.baidu.com/link?url=EdHY1vcvYqlz32EfYu91TViHpf9vknfEtjhwoIHuH0nq54T1rXfBWHjKTJMGB2xm13RwGd_5P8dkjWPBjNh-ja. [2]http://www.360doc.com/content/14/0325/22/9482_363730690.shtml. [3]http://baike.baidu.com/link?url=HEK-9lVNug8ccN9z8KE43SZTIlF5ojvWJ0cjG46TY5Yjf8h1t5Cu4LYoZ_rht5jfwjnFohp0xNPZaxMGIsGC7_. [4]http://blog.jobbole.com/53961/. [5]罗刚 王振东.自己动手写网络爬虫[M].北京:清华大学出版社,2010年10月. [6]李晓明,闫宏飞,王继民.搜索引擎:原理、技术与系统——华夏英才基金学术文库[M].北京:科学出版社,2005年04月. [7] J.I.Herlocker,J.A.Konstan,A.Borchers,and J.Riedl,"An algorithmic for performing collaborative filtering," in Proceedings of the Conference on Research and Development in Information Retrieval(SigIR'99),pp.230-237,1999. [8] R. Salakhutdinov and A. Mnih,Probabilistic Matrix Factorization. In Proceedings of NIPS. 2007. [9] R. Salakhutdinov and A. Mnih,Bayesian probabilistic matrix factorization using Markov chain Monte Carlo.In Proceedings of ICML. 2008, 880-887. [10] Mohsen Jamali, Gholamreza Haffari, Martin Ester. Modeling the temporal dynamics of social rating networks using bidirectional effects of social relations and rating patterns. WWW 2011, 527-536. [11]TianjunFu,AhmedAbbasi,HsinchunChen. A focused crawler for Dark Web forums[J]. J. Am. Soc. Inf. Sci.,2010,6,16. [12]Punam Bedi,Anjali Thukral,Hema Banati,Abhishek Behl,Varun Mendiratta. A Multi-Threaded Semantic Focused Crawler[J]. Journal of Computer Science and Technology,2012,2,16. [13]Winter.中文搜索引擎技术解密:网络蜘蛛 [M].北京:人民邮电出版社,2004年. ## 致 谢 在这次毕业设计中也使我们的同学关系更进一步了,同学之间互相帮助,有什么不懂的大家在一起商量,听听不同的看法对我们更好的理解知识,所以在这里非常感谢帮助我的同学。 在此更要感谢我的导师和专业老师,是你们的息心指导和关怀,使我能够顺利的完成毕业论文。在我的学业和论文的研究工作中无不倾注着老师们辛勤的汗水和心血。老师的严谨治学态度、渊博的知识、无私的奉献精神使我深受启迪。从尊敬的导师身上,我不仅学到了扎实、宽广的专业知识,也学到了做人的道理。在此我要 向我的导师致以最衷心的感谢和深深的敬意。 附录1 英文原文 Efficient URL Caching for World Wide Web Crawling Andrei Z. Broder ABSTRACT Crawling the web is deceptively simple: the basic algorithm is (a)Fetch a page (b) Parse it to extract all linked URLs (c) For all the URLs not seen before, repeat (a)–(c). However, the size of the web (estimated at over 4 billion pages) and its rate of change (estimated at 7% per week) move this plan from a trivial programming exercise to a serious algorithmic and system design challenge. Indeed, these two factors alone imply that for a reasonably fresh and complete crawl of the web, step (a) must be executed about a thousand times per second, and thus the membership test (c) must be done well over ten thousand times per second against a set too large to store in main memory. This requires a distributed architecture, which further complicates the membership test. A crucial way to speed up the test is to cache, that is, to store in main memory a (dynamic) subset of the “seen” URLs. The main goal of this paper is to carefully investigate several URL caching techniques for web crawling. We consider both practical algorithms: random replacement, static cache, LRU, and CLOCK, and theoretical limits: clairvoyant caching and infinite cache. We performed about 1,800 simulations using these algorithms with various cache sizes, using actual log data extracted from a massive 33 day web crawl that issued over one billion HTTP requests. Our main conclusion is that caching is very effective – in our setup, a cache of roughly 50,000 entries can achieve a hit rate of almost 80%. Interestingly, this cache size falls at a critical point: a substantially smaller cache is much less effective while a substantially larger cache brings little additional benefit. We conjecture that such critical points are inherent to our problem and venture an explanation for this phenomenon. 1. INTRODUCTION A recent Pew Foundation study [31] states that “Search engines have become an indispensable utility for Internet users” and estimates that as of mid-2002, slightly over 50% of all Americans have used web search to find information. Hence, the technology that powers web search is of enormous practical interest. In this paper, we concentrate on one aspect of the search technology, namely the process of collecting web pages that eventually constitute the search engine corpus. Search engines collect pages in many ways, among them direct URL submission, paid inclusion, and URL extraction from nonweb sources, but the bulk of the corpus is obtained by recursively exploring the web, a process known as crawling or SPIDERing. The basic algorithm is (a) Fetch a page (b) Parse it to extract all linked URLs (c) For all the URLs not seen before, repeat (a)–(c) Crawling typically starts from a set of seed URLs, made up of URLs obtained by other means as described above and/or made up of URLs collected during previous crawls. Sometimes crawls are started from a single well connected page, or a directory such as yahoo.com, but in this case a relatively large portion of the web (estimated at over 20%) is never reached. See [9] for a discussion of the graph structure of the web that leads to this phenomenon. If we view web pages as nodes in a graph, and hyperlinks as directed edges among these nodes, then crawling becomes a process known in mathematical circles as graph traversal. Various strategies for graph traversal differ in their choice of which node among the nodes not yet explored to explore next. Two standard strategies for graph traversal are Depth First Search (DFS) and Breadth First Search (BFS) – they are easy to implement and taught in many introductory algorithms classes. (See for instance [34]). However, crawling the web is not a trivial programming exercise but a serious algorithmic and system design challenge because of the following two factors. 1. The web is very large. Currently, Google [20] claims to have indexed over 3 billion pages. Various studies [3, 27, 28] have indicated that, historically, the web has doubled every 9-12 months. 2. Web pages are changing rapidly. If “change” means “any change”, then about 40% of all web pages change weekly [12]. Even if we consider only pages that change by a third or more, about 7% of all web pages change weekly [17]. These two factors imply that to obtain a reasonably fresh and 679 complete snapshot of the web, a search engine must crawl at least 100 million pages per day. Therefore, step (a) must be executed about 1,000 times per second, and the membership test in step (c) must be done well over ten thousand times per second, against a set of URLs that is too large to store in main memory. In addition, crawlers typically use a distributed architecture to crawl more pages in parallel, which further complicates the membership test: it is possible that the membership question can only be answered by a peer node, not locally. A crucial way to speed up the membership test is to cache a (dynamic) subset of the “seen” URLs in main memory. The main goal of this paper is to investigate in depth several URL caching techniques for web crawling. We examined four practical techniques: random replacement, static cache, LRU, and CLOCK, and compared them against two theoretical limits: clairvoyant caching and infinite cache when run against a trace of a web crawl that issued over one billion HTTP requests. We found that simple caching techniques are extremely effective even at relatively small cache sizes such as 50,000 entries and show how these caches can be implemented very efficiently. The paper is organized as follows: Section 2 discusses the various crawling solutions proposed in the literature and how caching fits in their model. Section 3 presents an introduction to caching techniques and describes several theoretical and practical algorithms for caching. We implemented these algorithms under the experimental setup described in Section 4. The results of our simulations are depicted and discussed in Section 5, and our recommendations for practical algorithms and data structures for URL caching are presented in Section 6. Section 7 contains our conclusions and directions for further research. 2. CRAWLING Web crawlers are almost as old as the web itself, and numerous crawling systems have been described in the literature. In this section, we present a brief survey of these crawlers (in historical order) and then discuss why most of these crawlers could benefit from URL caching. The crawler used by the Internet Archive [10] employs multiple crawling processes, each of which performs an exhaustive crawl of 64 hosts at a time. The crawling processes save non-local URLs to disk; at the end of a crawl, a batch job adds these URLs to the per-host seed sets of the next crawl. The original Google crawler, described in [7], implements the different crawler components as different processes. A single URL server process maintains the set of URLs to download; crawling processes fetch pages; indexing processes extract words and links; and URL resolver processes convert relative into absolute URLs, which are then fed to the URL Server. The various processes communicate via the file system. For the experiments described in this paper, we used the Mercator web crawler [22, 29]. Mercator uses a set of independent, communicating web crawler processes. Each crawler process is responsible for a subset of all web servers; the assignment of URLs to crawler processes is based on a hash of the URL’s host component. A crawler that discovers an URL for which it is not responsible sends this URL via TCP to the crawler that is responsible for it, batching URLs together to minimize TCP overhead. We describe Mercator in more detail in Section 4. Cho and Garcia-Molina’s crawler [13] is similar to Mercator. The system is composed of multiple independent, communicating web crawler processes (called “C-procs”). Cho and Garcia-Molina consider different schemes for partitioning the URL space, including URL-based (assigning an URL to a C-proc based on a hash of the entire URL), site-based (assigning an URL to a C-proc based on a hash of the URL’s host part), and hierarchical (assigning an URL to a C-proc based on some property of the URL, such as its top-level domain). The WebFountain crawler [16] is also composed of a set of independent, communicating crawling processes (the “ants”). An ant that discovers an URL for which it is not responsible, sends this URL to a dedicated process (the “controller”), which forwards the URL to the appropriate ant. UbiCrawler (formerly known as Trovatore) [4, 5] is again composed of multiple independent, communicating web crawler processes. It also employs a controller process which oversees the crawling processes, detects process failures, and initiates fail-over to other crawling processes. Shkapenyuk and Suel’s crawler [35] is similar to Google’s; the different crawler components are implemented as different processes. A “crawling application” maintains the set of URLs to be downloaded, and schedules the order in which to download them. It sends download requests to a “crawl manager”, which forwards them to a pool of “downloader” processes. The downloader processes fetch the pages and save them to an NFS-mounted file system. The crawling application reads those saved pages, extracts any links contained within them, and adds them to the set of URLs to be downloaded. Any web crawler must maintain a collection of URLs that are to be downloaded. Moreover, since it would be unacceptable to download the same URL over and over, it must have a way to avoid adding URLs to the collection more than once. Typically, avoidance is achieved by maintaining a set of discovered URLs, covering the URLs in the frontier as well as those that have already been downloaded. If this set is too large to fit in memory (which it often is, given that there are billions of valid URLs), it is stored on disk and caching popular URLs in memory is a win: Caching allows the crawler to discard a large fraction of the URLs without having to consult the disk-based set. Many of the distributed web crawlers described above, namely Mercator [29], WebFountain [16], UbiCrawler[4], and Cho and Molina’s crawler [13], are comprised of cooperating crawling processes, each of which downloads web pages, extracts their links, and sends these links to the peer crawling process responsible for it. However, there is no need to send a URL to a peer crawling process more than once. Maintaining a cache of URLs and consulting that cache before sending a URL to a peer crawler goes a long way toward reducing transmissions to peer crawlers, as we show in the remainder of this paper. 3. CACHING In most computer systems, memory is hierarchical, that is, there exist two or more levels of memory, representing different tradeoffs between size and speed. For instance, in a typical workstation there is a very small but very fast on-chip memory, a larger but slower RAM memory, and a very large and much slower disk memory. In a network environment, the hierarchy continues with network accessible storage and so on. Caching is the idea of storing frequently used items from a slower memory in a faster memory. In the right circumstances, caching greatly improves the performance of the overall system and hence it is a fundamental technique in the design of operating systems, discussed at length in any standard textbook [21, 37]. In the web context, caching is often mentioned in the context of a web proxy caching web pages [26, Chapter 11]. In our web crawler context, since the number of visited URLs becomes too large to store in main memory, we store the collection of visited URLs on disk, and cache a small portion in main memory. Caching terminology is as follows: the cache is memory used to store equal sized atomic items. A cache has size k if it can store at most k items.1 At each unit of time, the cache receives a request for an item. If the requested item is in the cache, the situation is called a hit and no further action is needed. Otherwise, the situation is called a miss or a fault. If the cache has fewer than k items, the missed item is added to the cache. Otherwise, the algorithm must choose either to evict an item from the cache to make room for the missed item, or not to add the missed item. The caching policy or caching algorithm decides which item to evict. The goal of the caching algorithm is to minimize the number of misses. Clearly, the larger the cache, the easier it is to avoid misses. Therefore, the performance of a caching algorithm is characterized by the miss ratio for a given size cache. In general, caching is successful for two reasons: _ Non-uniformity of requests. Some requests are much more popular than others. In our context, for instance, a link to yahoo.com is a much more common occurrence than a link to the authors’ home pages. _ Temporal correlation or locality of reference. Current requests are more likely to duplicate requests made in the recent past than requests made long ago. The latter terminology comes from the computer memory model – data needed now is likely to be close in the address space to data recently needed. In our context, temporal correlation occurs first because links tend to be repeated on the same page – we found that on average about 30% are duplicates, cf. Section 4.2, and second, because pages on a given host tend to be explored sequentially and they tend to share many links. For example, many pages on a Computer Science department server are likely to share links to other Computer Science departments in the world, notorious papers, etc. Because of these two factors, a cache that contains popular requests and recent requests is likely to perform better than an arbitrary cache. Caching algorithms try to capture this intuition in various ways. We now describe some standard caching algorithms, whose performance we evaluate in Section 5. 3.1 Infinite cache (INFINITE) This is a theoretical algorithm that assumes that the size of the cache is larger than the number of distinct requests. 3.2 Clairvoyant caching (MIN) More than 35 years ago, L´aszl´o Belady [2] showed that if the entire sequence of requests is known in advance (in other words, the algorithm is clairvoyant), then the best strategy is to evict the item whose next request is farthest away in time. This theoretical algorithm is denoted MIN because it achieves the minimum number of misses on any sequence and thus it provides a tight bound on performance. 3.3 Least recently used (LRU) The LRU algorithm evicts the item in the cache that has not been requested for the longest time. The intuition for LRU is that an item that has not been needed for a long time in the past will likely not be needed for a long time in the future, and therefore the number of misses will be minimized in the spirit of Belady’s algorithm. Despite the admonition that “past performance is no guarantee of future results”, sadly verified by the current state of the stock markets, in practice, LRU is generally very effective. However, it requires maintaining a priority queue of requests. This queue has a processing time cost and a memory cost. The latter is usually ignored in caching situations where the items are large. 3.4 CLOCK CLOCK is a popular approximation of LRU, invented in the late sixties [15]. An array of mark bits M0;M1; : : : ;Mk corresponds to the items currently in the cache of size k. The array is viewed as a circle, that is, the first location follows the last. A clock handle points to one item in the cache. When a request X arrives, if the item X is in the cache, then its mark bit is turned on. Otherwise, the handle moves sequentially through the array, turning the mark bits off, until an unmarked location is found. The cache item corresponding to the unmarked location is evicted and replaced by X. 3.5 Random replacement (RANDOM) Random replacement (RANDOM) completely ignores the past. If the item requested is not in the cache, then a random item from the cache is evicted and replaced. In most practical situations, random replacement performs worse than CLOCK but not much worse. Our results exhibit a similar pattern, as we show in Section 5. RANDOM can be implemented without any extra space cost; see Section 6. 3.6 Static caching (STATIC) If we assume that each item has a certain fixed probability of being requested, independently of the previous history of requests, then at any point in time the probability of a hit in a cache of size k is maximized if the cache contains the k items that have the highest probability of being requested. There are two issues with this approach: the first is that in general these probabilities are not known in advance; the second is that the independence of requests, although mathematically appealing, is antithetical to the locality of reference present in most practical situations. In our case, the first issue can be finessed: we might assume that the most popular k URLs discovered in a previous crawl are pretty much the k most popular URLs in the current crawl. (There are also efficient techniques for discovering the most popular items in a stream of data [18, 1, 11]. Therefore, an on-line approach might work as well.) Of course, for simulation purposes we can do a first pass over our input to determine the k most popular URLs, and then preload the cache with these URLs, which is what we did in our experiments. The second issue above is the very reason we decided to test STATIC: if STATIC performs well, then the conclusion is that there is little locality of reference. If STATIC performs relatively poorly, then we can conclude that our data manifests substantial locality of reference, that is, successive requests are highly correlated. 附录2 中文翻译 基于网络爬虫的有效URL缓存 要在网络上爬行非常简单:基本的算法是:(a)取得一个网页(b)解析它提取所有的链接URLs(c)对于所有没有见过的URLs重复执行 (a)-(c)。但是,网络的大小(估计有超过40亿的网页)和他们变化的频率(估计每周有7%的变化)使这个计划由一个微不足道的设计习题变成一个非常 严峻的算法和系统设计挑战。实际上,光是这两个要素就意味着如果要进行及时地,完全地爬行网络,步骤(a)必须每秒钟执行大约1000次,因此,成员检测 (c)必须每秒钟执行超过10000次,并有非常大的数据储存到主内存中。这个要求有一个分布式构造,使得成员检测更加复杂。 一个非常重要的方法加速这个检测就是用cache(高速缓存),这个是把见过的URLs存入主内存中的一个(动态)子集中。这个论文最主要的成果就是仔细 的研究了几种关于网络爬虫的URL缓存技术。我们考虑所有实际的算法:随机置换,静态cache,LRU,和CLOCK,和理论极限:透视cache和极 大的cache。我们执行了大约1800次模拟,用不同的cache大小执行这些算法,用真实的log日志数据,获取自一个非常大的33天的网络爬行,大 约执行了超过10亿次的http请求。 我们的主要的结论是 cache是非常高效的-在我们的机制里,一个有大约50000个入口的cache可以完成80%的速率。有趣的是,这cache的大小下降到一个临界 点:一个足够的小一点的cache更有效当一个足够的大一点的cache只能带来很小的额外好处。我们推测这个临界点是固有的并且冒昧的解释一下这个现 象。 1.介绍 皮尤基金会最新的研究指出:“搜索引擎已经成为互联网用户不可或缺的工具”,估计在2002年中期,初略有超过1半的美国人用网络搜索获取信息。因此,一 个强大的搜索引擎技术有巨大的实际利益,在这个论文中,我们集中于一方面的搜索技术,也就是搜集网页的过程,最终组成一个搜索引擎的文集。 搜索引擎搜集网页通过很多途径,他们中,直接提交URL,回馈内含物,然后从非web源文件中提取URL,但是大量的文集包含一个进程叫 crawling 或者 SPIDERing,他们递归的探索互联网。基本的算法是: Fetch a page Parse it to extract all linked URLs For all the URLs not seen before,repeat(a)-(c) 网络怕从一般开始于一些 种子URLs。有些时候网络爬虫开始于一个正确连接的页面,或者一个目录就像:yahoo.com,但是因为这个原因相关的巨大的部分网络资源无法被访问到。(估计有超过20%) 如果把网页看作图中的节点,把超链接看作定向的移动在这些节点之间,那么网络爬虫就变成了一个进程就像数学中的图的遍历一样。不同的遍历策略决定 着先不访问哪个节点,下一个访问哪个节点。2种标准的策略是深度优先算法和广度优先算法-他们容易被实现所以在很多入门的算法课中都有教。 但是,在网络上爬行并不是一个微不足道的设计习题,而是一个非常严峻的算法和系统设计挑战因为以下2点原因: 网络非常的庞大。现在,Google需要索引超过30亿的网页。很多研究都指出,在历史上,网络每9-12个月都会增长一倍。 网络的页面改变很频繁。如果这个改变指的是任何改变,那么有40%的网页每周会改变。如果我们认为页面改变三分之一或者更多,那么有大约7%的页面每周会变。 这2个要素意味着,要获得及时的,完全的网页快照,一个搜索引擎必须访问1亿个网页每天。因此,步骤(a)必须执行大约每秒1000次,成员检测 的步骤(c)必须每秒执行超过10000次,并有非常大的数据储存到主内存中。另外,网络爬虫一般使用一个分布式的构造来平行地爬行更多的网页,这使成员 检测更为复杂:这是可能的成员问题只能回答了一个同行节点,而不是当地。 一个非常重要的方法加速这个检测就是用cache(高速缓存),这个是把见过的URLs存入主内存中的一个(动态)子集中。这个论文最主要的成果就是仔细 的研究了几种关于网络爬虫的URL缓存技术。我们考虑所有实际的算法:随机置换,静态cache,LRU,和CLOCK,和理论极限:透视cache和极 大的cache。我们执行了大约1800次模拟,用不同的cache大小执行这些算法,用真实的log日志数据,获取自一个非常大的33天的网络爬行,大 约执行了超过10亿次的http请求。 这个论文像这样组织的:第2部分讨论在文学著作中几种不同的爬行解决方案和什么样的cache最适合他们。第3部分介绍关于一些cache的技术和介绍了 关于cache几种理论和实际算法。第4部分我们实现这些算法,在实验机制中。第5部分描述和讨论模拟的结果。第6部分是我们推荐的实际算法和数据结构关 于URLcache。第7部分是结论和指导关于促进研究。 2.CRAWLING 网络爬虫的出现几乎和网络同期,而且有很多的文献描述了网络爬虫。在这个部分,我们呈现一个摘要关于这些爬虫程序,并讨论问什么大多数的网络爬虫会受益于URL cache。 网络爬虫用网络存档雇员多个爬行进程,每个一次性完成一个彻底的爬行对于64个hosts 。爬虫进程储存非本地的URLs到磁盘;在爬行的最后,一批工作将这些URLs加入到下个爬虫的每个host的种子sets中。 最初的google 爬虫,实现不同的爬虫组件通过不同的进程。一个单独的URL服务器进行维护需要下载的URL的集合;爬虫程序获取的网页;索引进程提取关键字和超链接;URL解决进程将相对路径转换给绝对路径。这些不同的进程通过文件系统通信。 这个论文的中实验我们使用的meractor网络爬虫。Mercator使用了一个独立的集合,通信网络爬虫进程。每个爬虫进程都是一个有效的web服务 器子集;URLs的分配基于URLs主机组件。没有责任通过TCP传送这个URL给网络爬虫,有责任把这些URLs绑在一起减少TCP开销。我们描述 mercator很多的细节在第4部分。 任何网络爬虫必须维护一个集合,装那些需要被下载的URLs。此外,不能重复地下载同一个URL,必须要个方法避免加入URLs到集合中超过一次。一般的,达到避免可以用维护一个发现URLs的集合。如果数据太多,可以存入磁盘,或者储存经常被访问的URLs。 3.CACHING 在大多数的计算机系统里面,内存是分等级的,意思是,存在2级或更多级的内存,表现出不同的空间和速度。举个例,在一个典型的工作站里,有一个非常小但是 非常快的内存,一个大,但是比较慢的RAM内存,一个非常大胆是很慢的disk内存。在一个网络环境中,也是分层的。Caching就是一种想法储存经常 用到的项目从慢速内存到快速内存。 Caching术语就像下面:cache是内存用来储存同等大小的元素。一个cache有k的大小,那么可以储存k个项目.在每个时间段,cache接受 到来自一个项目的请求.如果这个请求项目在这个cache中,这种情况将会引发一个碰撞并且不需要进一步的动作。另一方面,这种情况叫做 丢失或者失败。如果cache没有k个项目,那个丢失的项目被加入cache。另一方面,算法必须选择驱逐一个项目来空出空间来存放那个丢失的项目,或者 不加入那个丢失的项目。Caching算法的目标是最小化丢失的个数。 清楚的,cache越大,越容易避免丢失。因此,一个caching算法的性能要在看在一个给定大小的cache中的丢失率。 一般的,caching成功有2个原因: 不一致的请求。一些请求比其他一些请求多。 时间相关性或地方的职权范围。 3.1 无限cache(INFINITE) 这是一个理论的算法,假想这个cache的大小要大于明显的请求数。 3.2 透视cache(MIN) 超过35年以前,L?aszl?o Belady表示如果能提前知道完整的请求序列,就能剔除下一个请求最远的项目。这个理论的算法叫MIN,因为他达到了最小的数量关于丢失在任何序列中,而且能带来一个飞跃性的性能提升。 3.3 最近被用到(LRU) LRU算法剔除最长时间没用被用到的项目。LRU的直觉是一个项目如果很久都没被用过,那么在将来它也会在很长时间里不被用到。 尽管有警告“过去的执行不能保证未来的结果”,实际上,LRU一般是非常有效的。但是,他需要维护一个关于请求的优先权队列。这个队列将会有一个时间浪费和空间浪费。 3.4 CLOCK CLOCK是一个非常流行的接近于LRU,被发明与20世纪60年代末。一个排列标记着M0,M1,….Mk对应那些项目在一个大小为k的cache中。 这个排列可以看作一个圈,第一个位置跟着最后一个位置。CLOCK控制指针对一个项目在cache中。当一个请求X到达,如果项目X在cache中,然后 他的标志打开。否则,关闭标记,知道一个未标记的位置被剔除然后用X置换。 3.5 随机置换(RANDOM) 随机置换完全忽视过去。如果一个项目请求没在cache中,然后一个随机的项目将被从cache中剔除然后置换. 在大多数实际的情况下,随机替换比CLOCK要差,但并不是差很多。 3.6 静态caching(STATIC) 如果我们假设每个项目有一个确定的固定的可能性被请求,独立的先前的访问历史,然后在任何时间一个撞击在大小为k的cache里的概率最大,如果一个cache中包含那k个项目有非常大的概率被请求。 有2个问题关于这个步骤:第一,一般这个概率不能被提前知道;第二,独立的请求,虽然理论上有吸引力,是对立的地方参考目前在大多数实际情况。 在我们的情况中,第一种情况可以被解决:我们可以猜想上次爬行发现的最常用的k个URLs适合于这次的爬行的最常用的k个URLs。(也有有效的技术可以 发现最常用的项目在一个流数据中。因此,一个在线的步骤可以运行的很好)当然,为了达到模拟的目的,我们可以首先忽略我们的输入,去确定那个k个最常用 URLs,然后预装这些URLs到我们做实验的cache中。 第二个情况是我们决定测试STATIC的很大的原因:如果STATIC运行的很好,Sname结论是这里有很少的位置被涉及。如果STATIC运行的相对差,那么我们可以推断我们的数据显然是真实被提及的位置,连续的请求是密切相关的。


















 417
417

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











