




内容摘要
基于深度学习的手势识别处理计算机视觉领域中的关键技术之一,
深度学习技术在近20年得到了快速的发展,其中在2014年就提出了VGG和GoogleNet这两大高精度高准确率的网络模型。
手势识别是在图像中捕抓到手部关键信息再通过手势给机器传达信息。手势识别大多数情况下都是在实时视频作为应用环境,这就对模型有着实时处理和准确性这两个基本要求。
随着科技的发展和5G时代的到来,身处于深度学习领域的手势识别技术越来越完善,在技术层面上相对现在一定会有了很大的进步,但同时也面临更加深层的困难,例如各个种群的人类肤色、背景复杂度、光照条件、多人情况下的手部重叠这类打击性很大的干预因素,是每个开发手势识别技术人员都会面临的难题。
本次论文将以近年来较为流行的深度学习领域中的卷积神经网络等等神经算法展开,将获取到的手部信息关键点给予逻辑处理得到准确无误的信息。
关键词:手势识别 深度学习 卷积神经网络 手部关键信息点
Abstract
One of the key technologies in the field of computer vision in gesture recognition processing based on deep learning,
Deep learning technology has developed rapidly in the past 20 years. Among them, the two high-precision and high-accuracy network models of VGG and GoogleNet were proposed in 2014.
Gesture recognition is to capture the key information of the hand in the image and then convey the information to the machine through the gesture. Gesture recognition is in most cases using real-time video as the application environment, which has two basic requirements for real-time processing and accuracy of the model.
With the development of technology and the advent of the 5G era, the gesture recognition technology in the field of deep learning is becoming more and more perfect. There must be a lot of progress on the technical level compared with the present, but it also faces deeper difficulties, such as The striking intervention factors such as human skin color, background complexity, lighting conditions, and hand overlap in the case of multiple people are challenges faced by everyone who develops gesture recognition technology.
This paper will be developed with neural algorithms such as convolutional neural networks, which are more popular in the field of deep learning in recent years, and the key points of the hand information obtained will be logically processed to obtain accurate information.
.
Key words: gesture recognition deep learning convolutional neural network key information points of hand
目 录
第一章 绪论 1
1.1 技术背景及研究目的和意义 1
1.2 手势识别研究相撞 2
1.3 主要研究内容及论文结构 3
第二章 肤色切割 4
2.1 YCrCb颜色空间 4
2.2 图片阈值化 4
第三章 神经网络理论 6
3.1 向前传播 6
3.2 梯度下降和反向传播算法 6
3.3.1 梯度下降算法 6
3.3.2 反向传播算法 8
3.3 GoogLeNet基础结构 9
第四章 数GoogLeNet手势识别应用 12
4.1算法实现 12
4.1.1 实现步骤 12
4.1.2 环境与过程 15
第五章 结论 18
参考文献 19
致谢 20
第一章 绪论
1.1 课堂背景及研究目的和意义
从2000年以来深度学习理论和技术逐渐完善,人工智能中的手势识别这项技术从被提出开始就一直受到来自不同职业群体的广泛关注。其中的商业价值更是让人垂涎欲滴,以至于久久霸占着大众的视野同时也一直备受科研人员的关注。
手势识别之所以一直热度不减。这主要得益于两个原因,第一个原因是理论和科技已经能足够支撑起手势识别这个项目。第二个原因是手势交流是除了语言交流外第二种便捷交流的方式,以至于科普由手势识别衍生的产品的困难程度远远低于同为人工智能的其他技术产品。
现如今该技术随着时代的发展已经越来越成熟,已经开始运用在广泛的领域中有汽车行业、消费电子领域、运输部门、游戏行业、智能手机、家庭自动化等等。其中在手机领域中的华为已将该手势识别技术带入Mate30系列手机当中,可见其商业潜力!
但是手势识别这项技术一直有一个或多或少会困扰开发人员的难点,因为无接触手势识别技术是主要依靠光学等进行手势探测,当光照程度不良好时、背景复杂时或像素值于手部像素接近时、手部被物品遮挡时等等都会给模型造成相当大的干扰。
尽管如此,这些难点都可以去避免和修复。优化数据和网络等处理,例如进行灰度化和色域转换、肤色切割、阈值化、手部关键信息点、判断逻辑化、神经网络层进行调参和验证。对设备进行升级,例如给摄像头补光、使用RPG高清摄像头等等。都可以达到理想的效果。以至于人们依然十分乐意从这个研究方向进行切入。本次实验我也会利用到上述讲到的理论技术进行研究达到在各种环境下的最优化效果。
最后5G时代的来临一定是属于人工智能大树下手势识别的一股春风,其商业用途之广、惠及人群之多不言而喻。其实这句话早已被验证,而我相信凡是一项技术被越来越多的人关注时,无论他是处于何种目的所驱动,都说明了一点它是当下人们最需要的一项功能系统。
1.2 手势识别研究现状
随着科技和经济的发展,使用计算机的用户还是广度都有了很大的提升。属于人机交互领域的手势识别也在这20年间逐渐走向了大众的视野。在这里我将从实现手势识别的技术和前人所研究的成果进行一个概况。
手势识别在系统中主要包括三个基本阶段检测,跟踪和识别,就目前来看实现手势识别最主流的技术是利用深度学习的卷积神经网络对目的数据进行关键信息提取以及训练。但在这项技术的早期是难以做到让人满意的效果,主要的原因是当时的技术处于起步阶段和计算机综合能力有限所限制的。
随着时代的发展,理论越发完善的同时和计算机的综合能力有着显著提升,在2014年就提出了GoogleNet和Vgg这种深层次和高参数量特性的网络,而这种网络带来的就是高准确性。而这一切在深度学习领域种取得的成功主要原因是这项技术引起了众多广泛的关注。
在2002年Bretzner[1]等人提出的使用RGB摄像头对手部进行多尺寸特征收集。
2010年沙亮[2]等人研究了基于无标记全手势视觉的人机交互技术,并提供了相应的解决方案。
2011年微软公司[3]公布了Kinect,使用有红外线摄像头对手势进行识别和跟踪。
2015年江南大学的姜克[4]等人基于Kinect的研究实现了3D手势识别
2015年,谷歌ATAP部门[5]公布了Project Soli,它是采用了微小型雷达来识别手势。
手势识别这项技术的进步得益于的深度学习的发展,正所谓工欲善其事必先利其器。而输入的数据也由最初的2D逐渐变为3D、准确度和实时性也在逐渐升高。
放眼看去,手势识别随着时间的向前、科技的发展,一路推陈出新。
1.3 主要研究内容及论文结构
本文共分为五章,具体结构如下:
第一章 绪论。主要介绍在现阶段手势识别的研究背景、目的和意义,研究现状、社会价值,并介绍本文的组织结构
第二章肤色分割,主要解释YCrCb的作用和针对正常黄种人的肤色的范围进行分割。
第三章 卷积神经网络基础理论[6]。介绍了卷积神经网络主要组成部分的理论知识,简要阐明卷积神经网络的相关算法,并在手势识别中起到的作用。
第四章GoogleNet在手势识别上的应用,这一节将主要关注模型和实现手势识别的细节,并为了清晰整个过程会绘画出流程图。
第五章总结,在本章中对本次论文做出总结和引用的其他论文,并提出存在的问题和改进的方向,且希望日后能对其中做出完善。此外对我有过帮助的人将表示感谢。
第二章 肤色切割
2.1 YCrCb颜色空间
其实预处理对手部进行肤色切割时可以用的色域不止一种,相信有所了解的人也知道这一点,本次论文将使用YCrCb[7]空间。
一般的图像都是基于RGB空间的,在RGB空间里皮肤会受亮度影响相当大,当亮度足够好时肤色可以在正常的范围内,但是亮度低时肤色就无法呈现出来。因此我们需要将肤色和亮度分离开来,也就是说图像在此空间时肤色点是离散的点。中间嵌有很多的非肤色,这为肤色区域标定带来了难题。如果把RGB转为YCrCb空间的话,该问题就可以较为轻松的解决掉。
YCrCb又称为YUV,之所以使用该色域空间是因为它能将亮度和色度分离开来,这也是RGB空间难以处理的一点。

图2-1梯度下降示例图
上图2-1中Y表示为亮度(Luminance或Luma),通俗的讲就是灰阶值。而cr和cb表示的则是色度(Chrominance或Chroma),作用是描述影像色彩及饱和度,用于指定像素的色彩。其中,cr和cb它们两个受亮度的影响很小。
因此这就是我选用YCrCb而不是使用其他颜色空间进行肤色检测的依据,此外正常的黄种人的Cr分量大约在140175之间,而Cb分量大约在100120之间。这也就为后续的阈值化提供了很好的切入点。
当然我这种做法也有很明显的缺点,因为我们是将图片的RGB颜色空间转换为YCrCb空间,如果图片在RGB空间时由于受到了各种因素的影响导致肤色过于差劲,那么将其转换为YCrCb空间也是无用之举。
所以这种算法还是无法完全避光照的强度等因素产生的影响,因此不算特别完美的算法。当然如果该系统设备将来会应用到特殊的环境下的话则需要加上滤波操作,例如中值滤波等等,效果会更好。
2.2 图像阈值化
在符合某种人为定义的规则之下的像素点便称之为像素点分布规律。图像阈值化就是利用了图像素点分布规律进行切割的。所谓的阈值化往简单方向说就是划分成黑和白,通过设定一个标准如果该像素点符合这个标准则设置为白或不变,如果像素点不符合这个标准就设置为黑,这就是本次阈值化的大致原理。
设f(i,j)表示图像中的像素值区间[i,j],而i和j代表着正常亚洲人的像素值。当像素值落在[i,j]之间就设置为255(白色),如果不在此区间设置为0(黑色)
对图像进行像素点分割大致可以分为三步。
第一步,在实现阈值化之前先读取图片,并保存在一个变量名为frame中,frame变量的类型为numpy.ndarray。这一步的目的是获取整张图像的像素值。为后续判断和修改提供原材料。
第二步,利用opencv库中cvtColor函数将frame变量将RGB空间转换成YCrCb空间。并单独取出Cr和Cb两个变量出来。
第三步,我没有使用opencv库中的内置阈值化函数,而是自己利用for7if对该图像进行处逻辑理,当Cr变量处于133和175区间之间并且Cb变量处于77和127区间之间时像素点,其值不变(在此区间的像素值是正常亚洲人肤色的像素值,保留不变),而不在此区间的像素值统一设置为0(其效果为黑色)。
效果如下(图2-2):

图2-2阈值化效果图
经过阈值化处理后的图像仅保留了手部原始图像且其余背景均大致被剔除。这一步的主要目的是将不必要的图像噪音点尽可能的除掉,为后续处理提供最干净的数据。当然将图像数据交付给神经层时还需要将图像灰度化,把RGB图像的三层变为灰度化两层,以减少神经层不必要的计算压力。
但是这样做也不能完全不免无噪音的情况,因为黑色的像素点它其实也是一个噪音,只不过被我们统一化了而已。
第三章 神经网络理论
3.1 向前传播
一个刚刚建立好的神经网络,在还没输入数据去运行训练时,各个神经元之间的参数是随机的,前向传播过程,向输入层输入特征向量时,经过权重参数w和偏置参数b的处理后再经过一个激活函数处理得到中间隐含层1,同理再经过第二个参数处理和激活函数得到中间隐含层2,依次类推。最后通过输出处理得到输出的过程。

图3-1 前向传播示意图
卷积神经网络的前向传播需要三个信息,其一是卷积核提取的特征向量,其二是神经元的连接关系(包含了卷积核、池化层和神经元与神经元之间的关系等等),其三是神经网络各神经元的参数,其中包括权重w和偏置b。
3.2 向梯度下降和方向传播算法
在说后向传播之前有必要的先讲一下梯度下降,因为梯度下降(gradient descent)和反向传播就像连体婴儿一样缺一不可的。在机器学习中应用十分的广泛,它的主要目的是通过迭代找到目标函数的最小值,或者收敛到极小值。
3.2.1 梯度下降算法
梯度下降算法的基本思想可以类比为一个人在山顶到山底的过程。首先,我们有一个可微分的函数。这个函数就代表着一座山。我们的目标就是找到这个函数的最小值,也就是山底。可以想象一下,一般而言最快下山的方式就是找到当前位置最陡峭的方向并沿着这个方向下去。
对于函数而言有三种策略去实现。
方法1:随机寻找(不太实用),类似暴力算法一样用许多参数一一带入,然后从里面选一个损失函数做小的参数组,这种做法费时费力且效果不理想。
方法2:随机局部搜索,在现有的参数基础上,随机搜索一下周边的参数吗,查看有没有比现在更好的参数,然后用新的参数替换现有的参数,不断迭代。
方法3:梯度下降,通俗的讲就是计算可微函数极小值(无条件约束),找到最陡峭的方向从高点逐一小步下降。注意如果每一次的步长如果过大则会错过最陡峭的方向甚至最佳点,但步长过小则会频繁计算去寻找下降的方向会造成耗时过长。所以需要合理的调整参数才能既保证不偏离方向的去寻找最佳点且耗时相对较短。
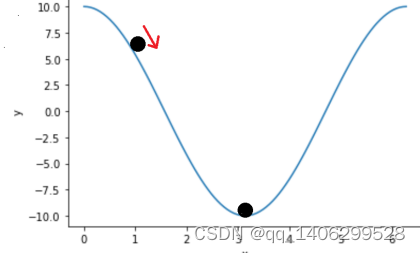
图3-2梯度下降示例图
假设,y轴表示为损失函数的值而x轴表示取值。梯度下降算法的目的是将参数向右侧移动使圆点向下降落使得损失最小。而参数的梯度可以通过求偏导的方式计算。参数X,其梯度公式为3.3,再确定一个学习率(步长)n。那么就可以实现参数梯度下降(公式3.4)从而求出损失的最小值。
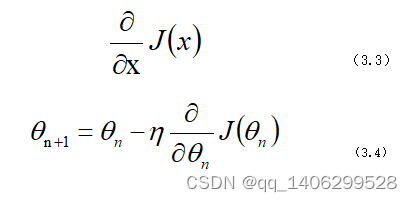
例如:损失函数为3.5,那么参数x的更新公式为如图3-6。假设步长为0.3且初始值为5,那么优化过程为表3-7所示。
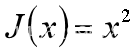
(3.5)
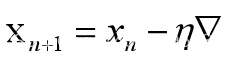
(3.6)
、
表3-7 梯度下降优化过程
次数 当前值 梯度学习率 更新后参数值
1 5 250.3=3 5-3=2
2 2 220.3=1.2 2-1.2=0.8
3 0.8 20.80.3=0.48 0.8-0.48=0.32
4 0.32 20.320.3=0.192 0.32-0.192=0.128
5 0.128 20.128*0.3=0.0768 0.128-0.0768=0.0512
3.2.2 反向传播算法
根据前面我们介绍了梯度下降算法,但是在实际的开发中往往是面对海量的数据,如果没有一种合理的机制去快速利用这些数据实现梯度下降算法的话,那么这个开发的成本是相当昂贵的。在20世纪中后期便提出了反向传播算法来为此解决梯度下降算法的问题。
反向传播,通俗的讲它是一个神经网络调整误差并修正的学习过程。在机器学习中会反复的执行正向传播和反向传播这个过程。执行的顺序为先正向后反向。
在神经网络运行时正向传播在输入层接收到数据并逐层传递(其中就包含了隐含层),最终由输出层输出结果。如果输出层输出的结果与预期不一致则会进入反向传播,对各层的权值参数等进行修改使得与预期期望值之间的误差最小化。然后接着正向传播…,以此类推。
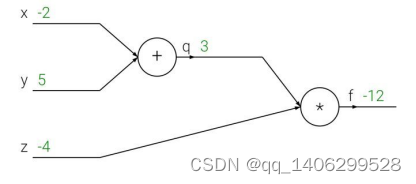
图3-8 一次正向传播
如图3-8所示,向x神经元输入-2、y神经元输入5和z神经元输入-4,最终整个网络的输出为-12。那么假如目标值为-11呢?这时就需要方向传播进行修成。
计算误差为实际输出值减去目标值,接着计算出图3-8中的x、y、z的偏导数,如3.9、3.10、3.11结果所示
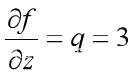
(3.9)
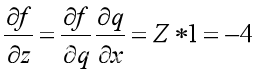
(3.10)
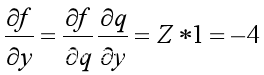
(3.11)
假设设置为1,就可以求出。然后就更新x、y和z的值(如公式3.12、3.13、3.14所示)。
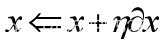
(3.12)
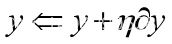
(3.13)
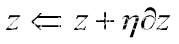
(3.14)
3.3 Google InceptionNet网络结构
在说明本次使用的模型之前,有必要先介绍一下Google InceptionNet网络(也可称为GoogleNet)。
Google InceptionNet网络模型的出现是在2014年的ILSVRC比赛中,有趣的是同时期也出现了VGG网络模型,但本文主角不是VGG也就不过多讨论。
Google InceptionNet网络的创新是属于结构体系上的创新。
纵观前三个版本的模型结构,最主要的改动有两点,第一点在Inception v1中摒弃了全连接网络层改而使用全局平均池化层来代替。第二点在Inception v3中分别对卷积层和池化层进行了很大的改动,其中对大卷积核分解成多个小卷积核、池化层和卷积层改为并联方式的结构。
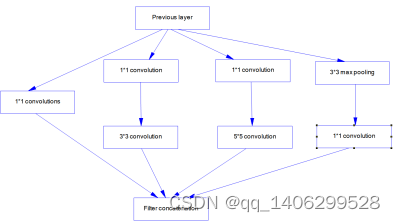
图3-15 Inception v3结构图
这一系列的改动其最直接的效果是准确率和错误率分别有了很明显的提升和降低。此外在Google InceptionNet网络模型中给我们最大的特点是它在控制计算量和参数量的同时有效的提高网络的性能。
因此在内存和计算机计算能力都有限的情况下,选择Google InceptionNet是明智地。况且由于计算量和参数量的降低在实时性的性能上也很使我钟意。
而在本次使用的模型结构是基于GoogleNet来构建的如3-5图[8]所示。
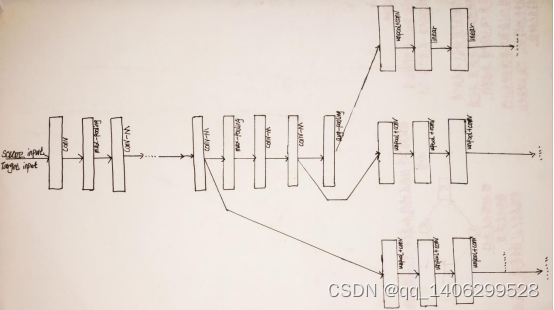
图3-16 模型结构
在Conv-M模块是包含着两个结构Inception-v3[9]、反褶积和ReLU。
Inception-v3结构。该结构的特点是增加了模型的宽度和深度,虽然在3-5图中由于省略了很多内部细节不能很好的直观感受。大卷积核被分解成多个小卷积核。比如77的卷积核拆分成71卷积核核17卷积核,或者将55卷积核拆分成两个33的卷积核。这样做的结果,一方面因为卷积数目的增加导致获取的特征数据信息有所增多,另一方面模型的参数有所减少(55的参数为25个而33核和33核的参数和为18个,降低了大约30%。)。
但是该层在面对阴影等杂音时卷积核很有可能也会照样采集导致特征数据信息中会有杂音[10],所有为了避免过度采集使用了反褶积[11]进行一些反补机制,特别是对于小规模和中等规模的卷积核的问题上采用的较多。
此外传统的卷积层和池化层串联的方式也进行了革新改为并联方式,极大的缓解了表达瓶颈使特征数据的卷积处理和池化处理都单独分开,很大程度上降低了池化层的运算量且更重要的是将数据特征的表达能力发挥的淋漓尽致。需要注意的是卷积层和池化层生成的特征数据的尺寸需要一致,以至于后续处理时能够合并将数据交给下一层网络。
为了增加模型非线性能力,还包含着relu激活函数,对非对称性结构的数据具有处理能力。
linear结构是辅助分类器。网络的深度相对较大,为了以有效的方式将梯度传播给所有神经层的能力是值得我们关注的。一个有趣的发现当网络层处于中间这段的时候产生的特征数据信息是非常有识别力的。增加辅助分类器linear是
希望模型在较低层就有识别的作用。这些辅助分类器的防止形式一般在Inception(4a)和(4d)模块输出之上。在整个训练期间它们产生的损失都会叠在在一起被作为总损失(辅助分类器的损失加权值一般为0.3)。
在该模型的结尾处也遵循了GoogLeNet的基本理念,抛弃了全连接层。这也是GoogLeNet极具惹人注目的特色。在传统的卷积网络中,往往会加上全连接层。但在数据集庞大的实验中这样的做法反而弊大于利。
第一,参数量呈现爆炸时增长,例如输入100100尺寸的数据,假设输入层中有100100个节点,那么第一个隐含层有100节点那么在该层中含有的参数为(100*100+1)*100=1百万个参数。可以想象后续的全连接层参数会是一个怎样的数量级。这对于计算机来说是一个很大的负担。
第二,就拿图片数据来说往往具有空间性,而当这些数据进入到全连接层后会直接将这些数据变为1维的数据形式。这很大程度上摧毁了数据的表达能力。
第三,由于全连接层给计算机带的负担过于巨大,且对数据的损坏程度显著。一般很难在CNN网络中有多层全连接网络,也就很难弄成一个深层次全连接网络,限制了模型的表达能力。
在GoogLeNet网络中抛弃了全连接网络。在代替的方法中用AveragePool池化层代替了,是为了保证特征数据进入softmax分类器之前,特征数据依然保留着最初的空间性(不被粗鲁的压成一维数据形式),最后进行分类。
所以GoogleNet网络模型在面对庞大的数据集时,控制计算量和参数量的同时也获得了非常好的性能,是一个非常优秀且实用的模型。
第四章 GoogLeNet手势识别应用
无论在实时视频中还是已经录制好的视频中,往往都是先对每一帧图片都进行了手掌检测并实现跟踪,但是在现实情况中我们会常常遇到两大类难点。第一类,每一帧图片中存在未知数量的手部,我们到底需要确定哪一个手部为数据的基准呢。第二类,手部经常会有自我遮挡或相互遮挡(例如手指的弯曲)或物体遮挡(手因抓住物体而被遮挡)等等,使得手部的信息有所残缺。
通用的解决方法主要由手部跟踪(Hand tracking)和手掌检测(Palm detection)两个组成,手部跟踪器对视频中的每一帧图片进行边界框检测对人体手部实时跟踪,再对边界框中的手掌进行手掌检测并描绘关键点。因此在后续的处理识别功能时仅仅对信息关键点进行操作即可。
4.1 算法实现
4.1.1 实现步骤
1、导入训练有素的GoogleNet的模型,使用手部图像数据进行训练,训练出合乎理想的手势模型。由于此数据集是用48个视频中每30帧截取下来,用720*1280的尺寸和jpg格式将这些海量数据保存下来,将近20000张,因此碍于数据庞大,在这里先展示一部分数据。

图4-1 数据集展示
再将这些数据投给一句设置好的GoogleNet网络classifier.caffemodel和type_classifier.caffemodel模型,训练出hand_landmark.tflite手部追踪器和palm_detection_without_custom_op.tflite手掌检测器。由于这一过程已被官方人员所实现,接下来我将着重讲解怎么使用。
此外为了对比一下性能,我将在这里另外使用Vgg19和LeNet网络模型进行对同样的数据进行训练和测试。实验过程将会使用训练准确率、测试准确率和训练时间这三个标准来进行对比。
表4-2 性能比较
模型 训练集准确率 测试集准确率 训练时间
GoogLeNet 100% 94.4% 38min
Vgg模型 100% 91.3% 47min
LeNet模型 92.3% 84.3% 26min
如表4-2所示,可以看出在训练集准确率上其实三个模型都相差不多,尤其是GoogleNet和Vgg这两个网络最为接近,在训练集准确率上都达到了100%,但是在测试集准确率上GoogleNet比Vgg高3.1%。单从准确率这一方面的数据来看,可以体现出GoogleNet的泛化性会来的更好。而LeNet是比较旧式的卷积网络,在综合能力上比不上前两个网络模型属于意料之中。
最后从训练时间来看由于Vgg的包含全连接层,而全连接层带来的问题就是参数会急剧增多导致运算量增加,所以在时间上GoogleNet会占据优势。而LeNet模型相对于前两个层次为浅模型,因此花费的时间肯定会比前两个会少。单单从这一点来看LeNet为最优但是综合能力上它是三个里面最不理想的。
2、读入视频文件,弹出相应界面。在界面中通过摄像头获取输入信息并将逐帧图片输入给程序[12],如果检测到手掌数据就进行后续的处理,如果没有则继续读帧。如图4-3所示,在仅仅露出手臂等其他情况下,是没有检测出手掌的。
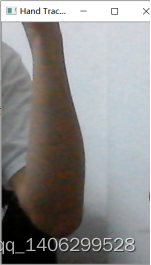
图4-3 无检测出手部
3、手掌传入给程序中,紧接着就是阈值化,对肤色进行分割并灰度化交给网络层并得到关键点信息。
4、得到手部信息关键点后,根据5个手势各个分布的关键点进行逻辑处理。
先从食指判断它的关键点,依次为中指、无名指、尾指、大拇指。如果5号至8号关键点的坐标呈现一个线性的。那么我们有理由预判它为1。再对中指、无名指、尾指、拇指轮流进行判断,假设此时中指的关键点坐标呈现一个非线性,那么无名指、尾指、拇指进行逻辑处理时只要其中有一个是呈现线性的,就不给予输出(因为已经超出了预设的手势)。如果除了食指而其他的手指均不呈现线性,那么输出1数字。

图4-4 手掌关键点信息
5、将输出信号传给视频界面显给当前做出手势的结果。为了方便查看在这里画出了实现手势识别的流程图。
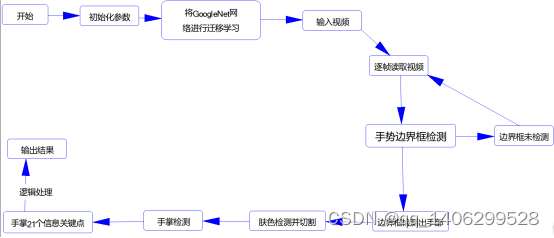
图4-5 实现的流程图
4.1.2 环境与过程
(a) 实验环境
硬件设备:
CPU:Intel Core i7 7500U 2.70GHz
内存:8G
显卡:NVIDIA GEFORCE 940MX
开发环境:Windows 10
开发语言及其编程软件:Python + Jupyter notebook
(b) 实验过程
本次论文使用手部跟踪器和手掌检测器来提取特征图。本次论文中实验视频均为本人所自行拍摄的手势视频。但是在实际运用过程中周围的环境一定比开发时更加广泛和复杂。所以为了统一数据尺寸将其设置为2562563格式。
此外也为了避免在识别的过程中出现多个边界框的重叠的现象,我使用SSD瞄点和非最大抑制算法[13],在找到局部极大值时抑制非极大值元素。并将阈值设置为0.7才能进入候选框,在候选框选取局部极大值,查看图4-3。

图4-6 非最大值抑制算法
在对每一帧(间隔5帧)图片进行检测时,检测到手部时将会对其进行肤色分割并灰度化,预处理结束后才会交给卷积网络。
手掌检测器检测到手掌并设置其中的关键点[14]后,因为事先知道手部跟踪器跟踪手掌在图片中的坐标并记录下来,将这些关键点返回到原本图片的坐标上并将这些点相连(关键点信息为红色,线段为黄色)。

图4-7 效果图
剩下的就是对这些关键点进行逻辑处理得出该手势的含义[15]。其中判断手势的规则,当表示1时只能竖起一个食指,表示2时需要同时竖起食指和中指,表示3时需要竖起食指、中指和无名指,表示4时需要竖起食指、中指、无名指和尾指,表示5时需要摊开手掌正对摄像头。
就拿2手势而言,8号关键点减去6号关键点,6号关键点减去0号关键点。然后除以各自的范数将向量单元化避免数据过大或者过小有溢出现象,再进行点积运算,如果大于预设好的阈值那么就显示手势2(1手势成功的前提下)。
需要注意的是用户使用了预设好的手势时就输出结果,如果用户使用的手势是我们没有预设的手势,虽然运算关键点会正常运行但因为没有与之匹配的类型则将不输出结果。
在实时性方面,由于将图片数据经过一系列的处理才能输出结果,这一过程是需要一些时间的,当然如果cpu和gpu的配置相当高的话,那么这一过程的时间可以忽略不记。但如果硬件配置一般的话是不能立刻将结果返回到界面中以至于有延时效果,因此在计算本帧图片的结果后,我将其输出到下一帧的图片上。

图4-8 手势识别效果图
第五章 结论
随着技术的发展,实现手势识别这项系统已经不仅仅局限于本篇论文所提及的技术。我之所以使用卷积网络来作为本片的基础。两个原因,第一个原因是因为在近几年卷积网络的发展越来越趋向于高准确率和低参数量,这对于实时性和设备限制都有着很大的帮助。第二个原因是个人对这一领域有着相当不错的兴趣,这就是我做手势识别的最初动机。
这里还有一些小插曲,我刚开始做的时候是用传统的卷积网络但效果是相当让人沮丧,无论在实时响应性还是准确率上。以至于我不得不寻找新的解决办法,这就有了现在的GoogleNet网络。因为GoogleNet的改善了卷积层和池化层,其中的全连接层跟是直接抛弃掉,一边让网络深层次的同时还防止了参数量不爆炸。
得益于站在巨人的肩膀上,在光照等因素良好的情况下准确率会高达92%。但尽管如此我的手势识别系统还是存在这问题。例如在没有手掌的情况下总是会时不时的弹出关键点信息,这可能与网络的错判或非最大抑制算法存在的缺陷有关,而且因为对图片的计算和预处理导致了实时性的性能有所下降。并且在有手掌的情况下关键点会存在不能准确显示的情况导致输入正确手势时会显示不出正确的结果。而且该系统也非常容易环境因素的干扰,如果手部是处于黑暗环境下,那么我所作的一切将不会奏效。这些将是我后续需要解决的部分。
参考文献
[1]Bretzner L, Laptev I, Lindeberg T. Hand gesture recognition using multi-scale colour features, hierarchical models and particle filtering [J]. Fifth IEEE international conference on automatic face and gesture recognition, 2002:405–410.
[2]沙亮. 基于无标记全手势视觉的人机交互技术[D].清华大学,2010.
[3]https://developer.microsoft.com/en-us/windows/kinect
[4]姜克. 基于深度图像的3D手势识别[D].江南大学,2015.
[5]https://atap.google.com/
[6]周飞燕, 金林鹏, 董军. 卷积神经网络研究综述[J]. 计算机学报, 2017(6).
[7]曹建秋, 王华清, 蓝章礼. 基于改进YCrCb颜色空间的肤色分割[J]. 重庆交通大学学报:自然科学版, 2010, 29(3):488-492.
[8]P. Aswathy, Siddhartha and D. Mishra, “Deep GoogLeNet Features for Visual Object Tracking,” 2018 IEEE 13th International Conference on Industrial and Information Systems (ICIIS), Rupnagar, India, 2018, pp. 60-66.
[9]https://arxiv.org/pdf/1409.4842v1.pdf
[10]于凡。李文。李青。刘Y.时兴。严燕。(2016)POI:具有高性能检测和外观特征的多目标跟踪。在:Hua G.,JégouH.(eds)Computer Vision – ECCV 2016 Workshops。ECCV2016。计算机科学讲座,第9914卷。ChamSpringer
[11]H. Noh, S. Hong, and B. Han. Learning Deconvolution Net work for Semantic Segmentation. International Conference on Computer Vision (ICCV), 2015.
[12]王福斌, 李迎燕, 刘杰,等. 基于OpenCV的机器视觉图像处理技术实现[J]. 机械与电子, 2010(06):56-59.
[13]李旭, 王正勇, 吴晓红, et al. 一种改进非极大值抑制的Canny边缘检测算法[J]. 成都信息工程学院学报, 2011(05):107-112.
[14]娄会东, 肖强. 基于HDC提取关键点的手势识别算法[J]. 安阳工学院学报, 2007(04):75-78.
[15]苏九林, 葛元, 王林泉. Gesture Recognition Algorithm Based on Feature Pixels%基于关键点的一种字母手势识别算法[J]. 计算机工程, 2004, 030(022):149-151.
致谢
本次论文在这里也就算告一段落了,在这里我由衷的感谢商丽娟老师。这段时间对我来说很重要同时也很辛苦。
就毕业设计而言,当我拿不准方向时、格式和内容都存在问题时,商老师都会及时帮我揪住方向并给予指点。让我少走了很多弯路,在此我再一次表示感谢。
此外还要感谢知网研学,在理论上对我的帮助也起到了相当重要。
最后感谢广东东软学院对我四年的培养。


















 970
970

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











