






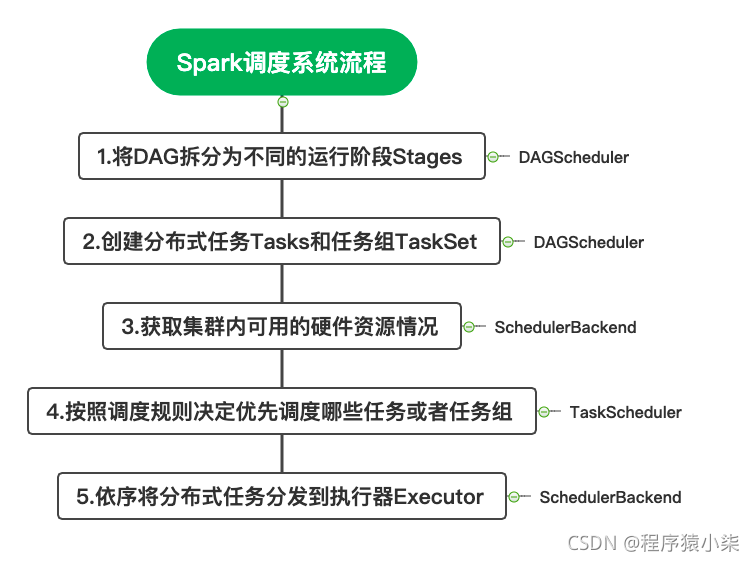
Spark调度系统包含3个核心组件,分别是DAGScheduler、TaskScheduler和SchedulerBackend。这3个组 件都运行在Driver进程中,它们通力合作将用戶构建的DAG转化为分布式任务,再把这些任务分发给集群中 的Executors去执行。














04-04
 358
358
358
03-15
3089
3089
02-26
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









