









不得不说Spark是一款优秀的计算引擎,继承Spark-ML、Spark-Graphx机器学习和图计算框架,Spark-ML一般用于离线分析和挖掘,生成模型。
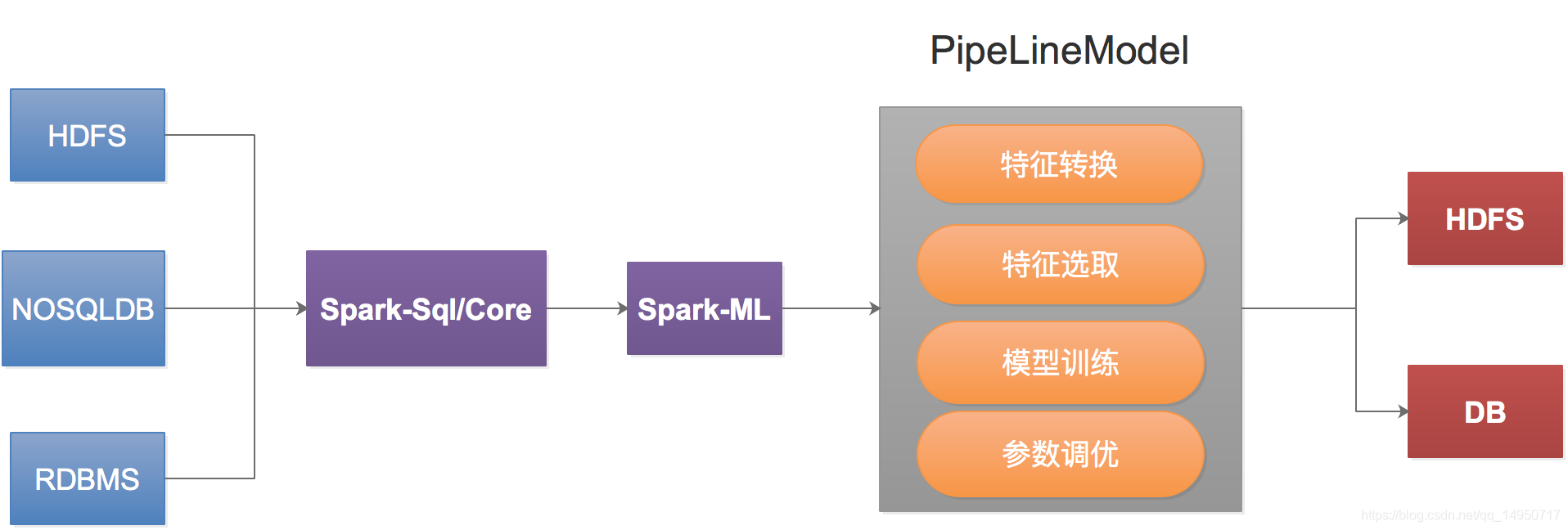 如果我们把模型保存在HDFS,需要在实时计算里面使用提前训练好的模型,
如果我们把模型保存在HDFS,需要在实时计算里面使用提前训练好的模型,
解决方案如下:
1、通过转换序列化方式,把模型转换成可以被其他语言调用的方式,如:java、python
2、在spark-streaming中使用
具体读取kafak的配置信息和保证EOS的不在这里体现,主要体现如何使用Spark-ML训练好的模型,具体代码如下:
val spark = SparkSession.builder().
appName("StreamingMLModel").
getOrCreate()
import spark.implicits._
val ssc = new StreamingContext(spark.sparkContext, Seconds(2))
val bootstrapServer = ""
val groupId = "E30E62E2-8B73-BBB0-AA8C-1A53E400646F-1"
val kafkaParams = Map(
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> bootstrapServer,
ConsumerConfig.GROUP_ID_CONFIG -> groupId,
ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer],
ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer],
ConsumerConfig.AUTO_OFFSET_RESET_CONFIG -> "latest",
ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG -> "false",
ConsumerConfig.MAX_POLL_RECORDS_CONFIG -> "100000"
)
val newsTopic = ""
val topicSet = Set(newsTopic)
val kafkaStream = KafkaUtils.createDirectStream(ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](topicSet, kafkaParams)
)
val bayesPipeLineModelPath = ""
val pipeLine = PipelineModel.load(bayesPipeLineModelPath)
val source = kafkaStream.map(_.value()).map(JSON.parseObject)
source.foreachRDD(rdd => {
if (!rdd.isEmpty()) {
//除微博外的数据
val data = rdd.map(jsonObj => (jsonObj.getString("id"), jsonObj.getString("content"))).
toDF("id", "content")
val predict = pipeLine.transform(data)
val filterRdd = predict.select("id", "prediction").
map(row => (row.getString(0), row.getDouble(1)))
filterRdd.foreachPartition(records => {
val list = records.toList
val goodNews = list.filter { case (news, bayes) => bayes == 1.0 }
val badNews = list.filter { case (news, bayes) => bayes == 0.0 }
// todo 输出外部DB或缓存或kafka
})
}
})
1、当流计算首次启动的时候,一定要限速
2、在streaming页面或者给予StreamingListener添加监控类














 714
714











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









