







Redis基础信息
redis默认有16个数据库,每个数据库直接是隔离的,切换数据库命令select,可以根据不同的业务使用不同的数据库防止数据相互污染。数据库数量可以再配置文件中修改databases参数。
基础数据结构和底层实现
1. string类型:
key-value(string字符串类型),一个键key对应一个字符类型value值
1.1 常用操作
get
set
expire
ttl
#不存在直接创建值为1,限定64位有符号整型
INCR num
DECR num
#指定增加减少数量
INCRBY num 3
DECRBY num 2
#浮点型数据操作,只能增加
INCRBYFLOAT num2 1.1
k-v形式的数据,有限制是键值的大小最大都为512M
1.2 使用场景
1. 比较典型的应用是session共享,多个节点共享session,判断登录状态
2. 计数器:数字类型的字符串可以原子加减,类似java中的AtomicInteger,使用原子操作就可以在不损耗性能情况下有效避免线程安全问题。
计数器使用场景:
有一个课次号的获取功能,课次号规则yyyyMMdd-5位随机字母数字,之前逻辑是在每次上课前获取课次号在java程序中使用随机数生成,然生成之后查缓存验证重复,重复的化需要重新生成。
问题点在于
1、课次越来越多的话重复几率越来越大;2、多线程问题,需要加锁损耗性能。
所以后来使用redis计数器来解决:
1. 我们预生成固定的比如5万个5位字母数组混合的课次号放到数据库一张表中,表的主键id是从1~50000递增。
2. 然后redis做计数器从1~50000原子递增并获取值作为id,到5万时再从1开始循环,id做为主键从数据库中查询。这样就避免在多个线程同时获取课次号时,生成相同的课次号造成多线程安全问题;重复问题也可以解决。
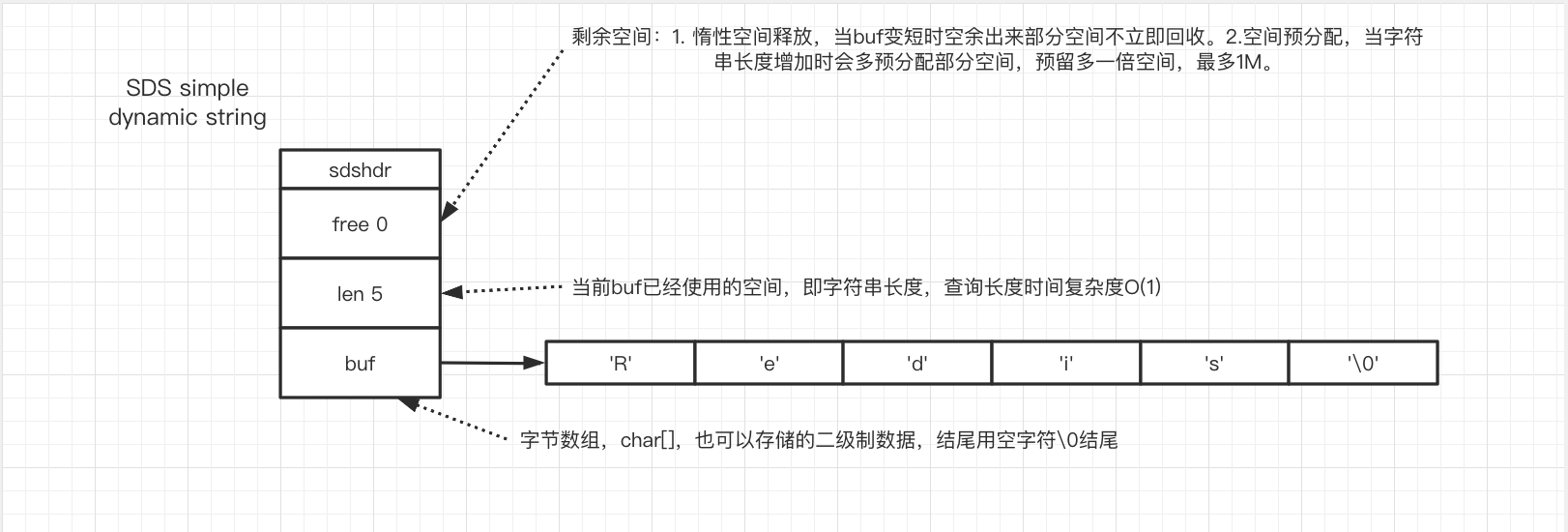
1.3 底层实现:SDS对象
- 内存预留:SDS对象,在初始化时不会预留空间,当使用修改API拼接时,检查空间不足会重分配内存,预留一倍的空间,最多1M,后续有修改操作就可以不用重分配内存;
- 惰性删除:当SDS修改并且缩短长度时,不会内存重分配将多余内存释放留待下次增长操作时防止内存重分配;
- 二进制安全:SDS定义了内存边界防止越界访问造成不安全,相比于C语言;
- 定义了字符串长度并且用二进制数据保存字符串,获取长度的时间复杂度O(1)。
2. list类型
#对列
lpush/rpop、rpush/lpop
#pop出栈会将元素从列表中删除
#栈
lpush/lpop
#阻塞出栈
blpop brpop
#查询
lrange
#设置指定位置的值
lset
#查询指定位置
lindex
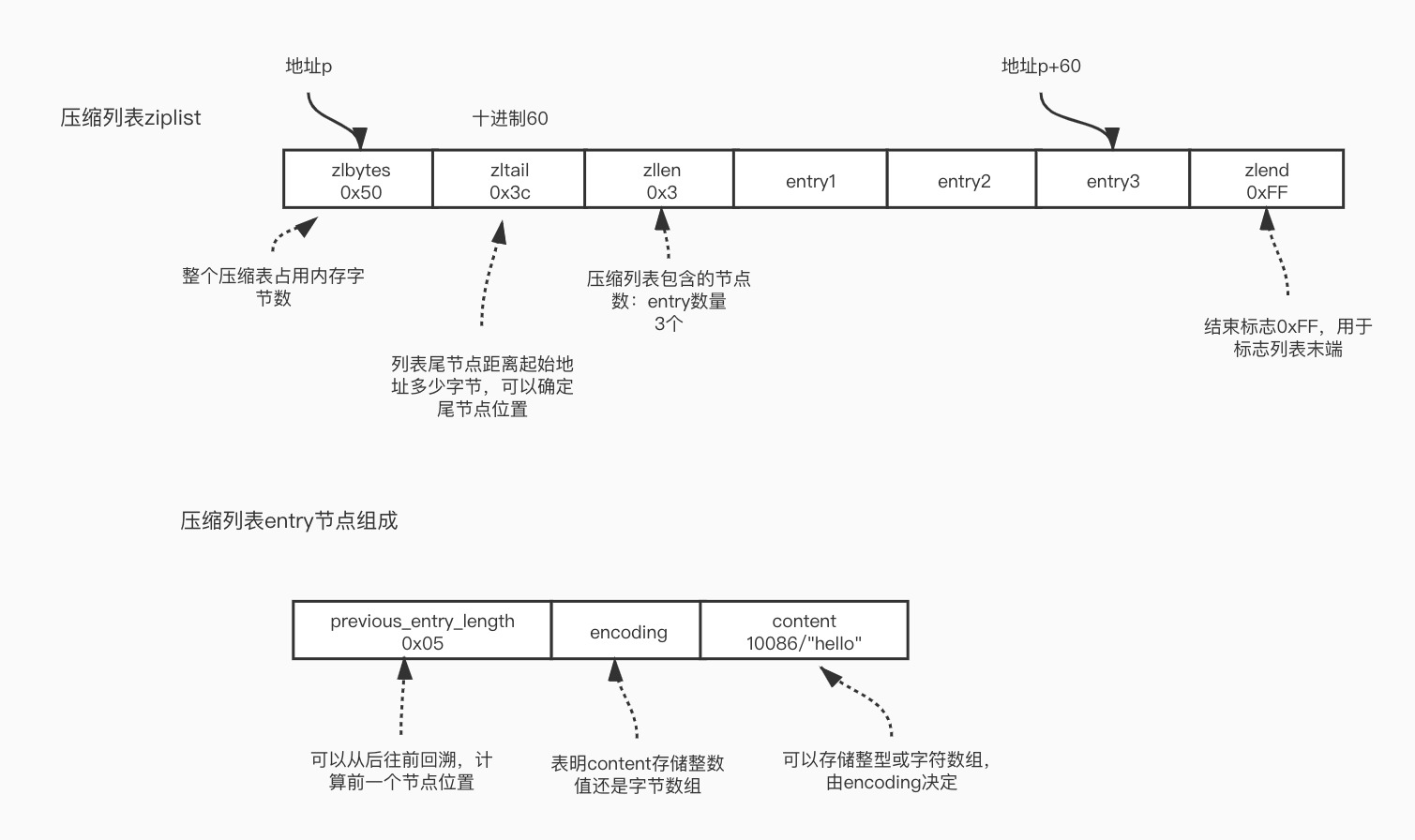
2.1 底层实现:
ziplist或双向链表(新版本使用quicklist,两者的结合-quicklistNode的链表,每个node对应一个ziplist)
双向链表:
ListNode节点,每个节点有prev、next指针指向前后节点,有void* value保存值指针,可以指向不同类型的值。
ziplist结构
3. 字典类型
key表示外层的键,fieldkey表示内层的键
3.1 常用操作:
hset
hget
hdel
hmget
hgetall
hscan
hlen
3.2 底层实现:ziplist或hashtable
ziplist方式,新来的节点key-value依次追加到ziplist的末尾
问题:那么ziplist如何去重的?
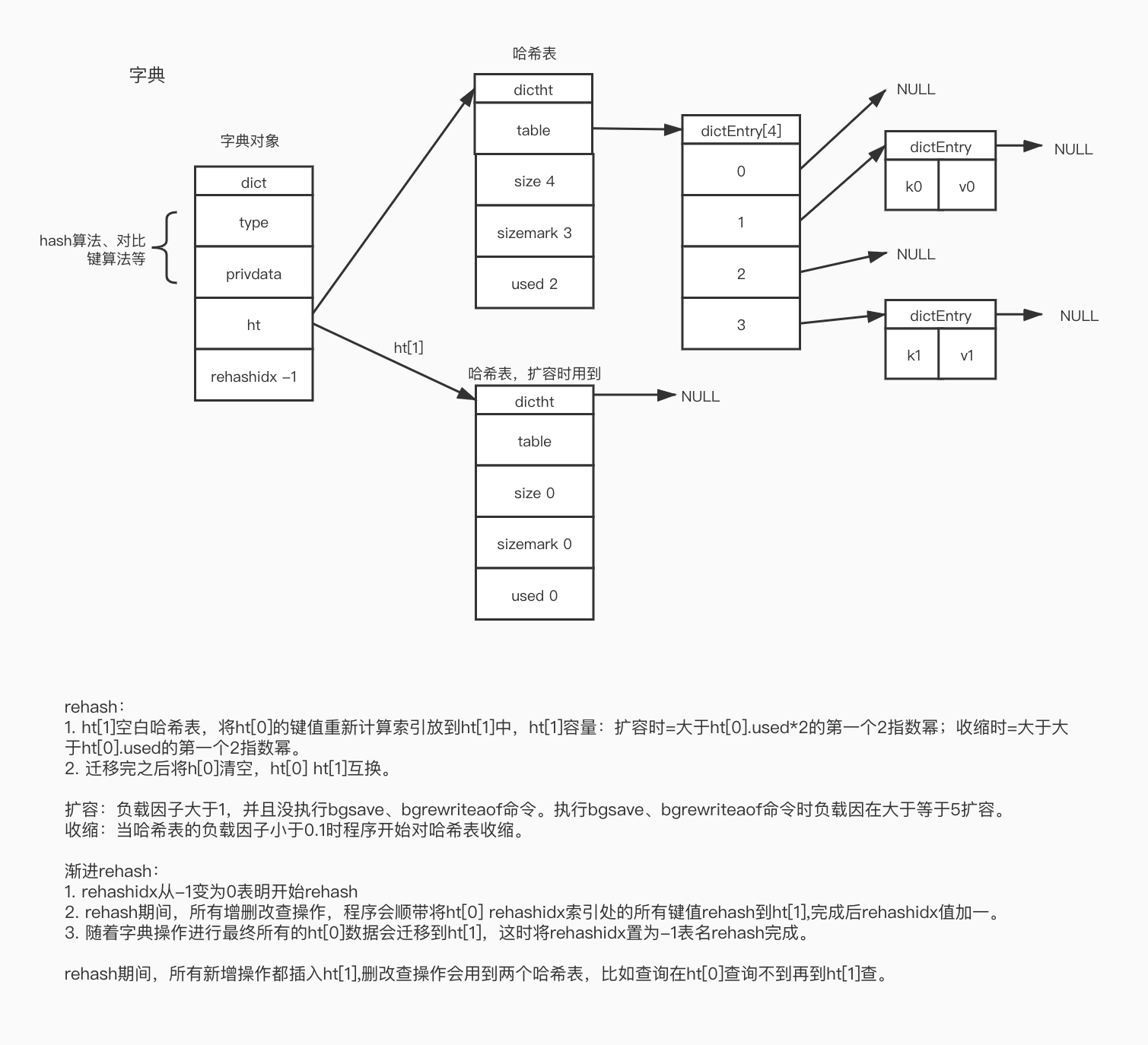
3.3 字典hashtable实现结构以及如何扩容:
渐进式扩容
字典中存在长度为2的hashtable数组ht,正常情况下ht[0]是存储数据,ht[1]为空。在扩容时,ht[1]初始化为ht[0].used*2长度的哈希表。字典中存在一个默认值-1的rehashIdx参数,扩容时置为0来标识数据迁移到的位置,从0位置开始递增,将ht[0]数组中的数据逐步迁移到ht[1]中。扩容过程中,查询操作在ht[0]找不到会去ht[1]中查找,写操作会只往ht[1]中写直到数据全部迁移完成,然后将ht1赋给ht[0],ht[1]再次置为空,rehashIdx置为-1。
扩容因子
不同于java的默认0.75,redis的扩容跟因子默认是1,即在元素个数等于数组长度时扩容;但是在bgsave或bgrewriteAof命令执行时,扩容因子变为5,尽量避免数据持久化时操作扩容。
示例图
4. zset类型
4.1 使用场景
有序性可以用在取top n的数据,比如点赞排行,使用点赞数作为score自动排序,然后zrange命令可以快速取出前n个数据
4.2 常用操作
zadd key score value
#根据分数段取数量
zcount key minscore maxscore
zrange key 0 -1 withscroes
#查看根据score排序
zrangebyscore key min max
zscore key value #返回 score
#根据score返回value的排名
zrank key value
#删除数据,根据排名
zremrangebyrank zs 0 0
4.3 底层实现:
1. 压缩列表ziplist
条件:所有元素长度小于64字节并且元素个数小于128个。entry对象第一个存score,第二个存value对象,顺序。
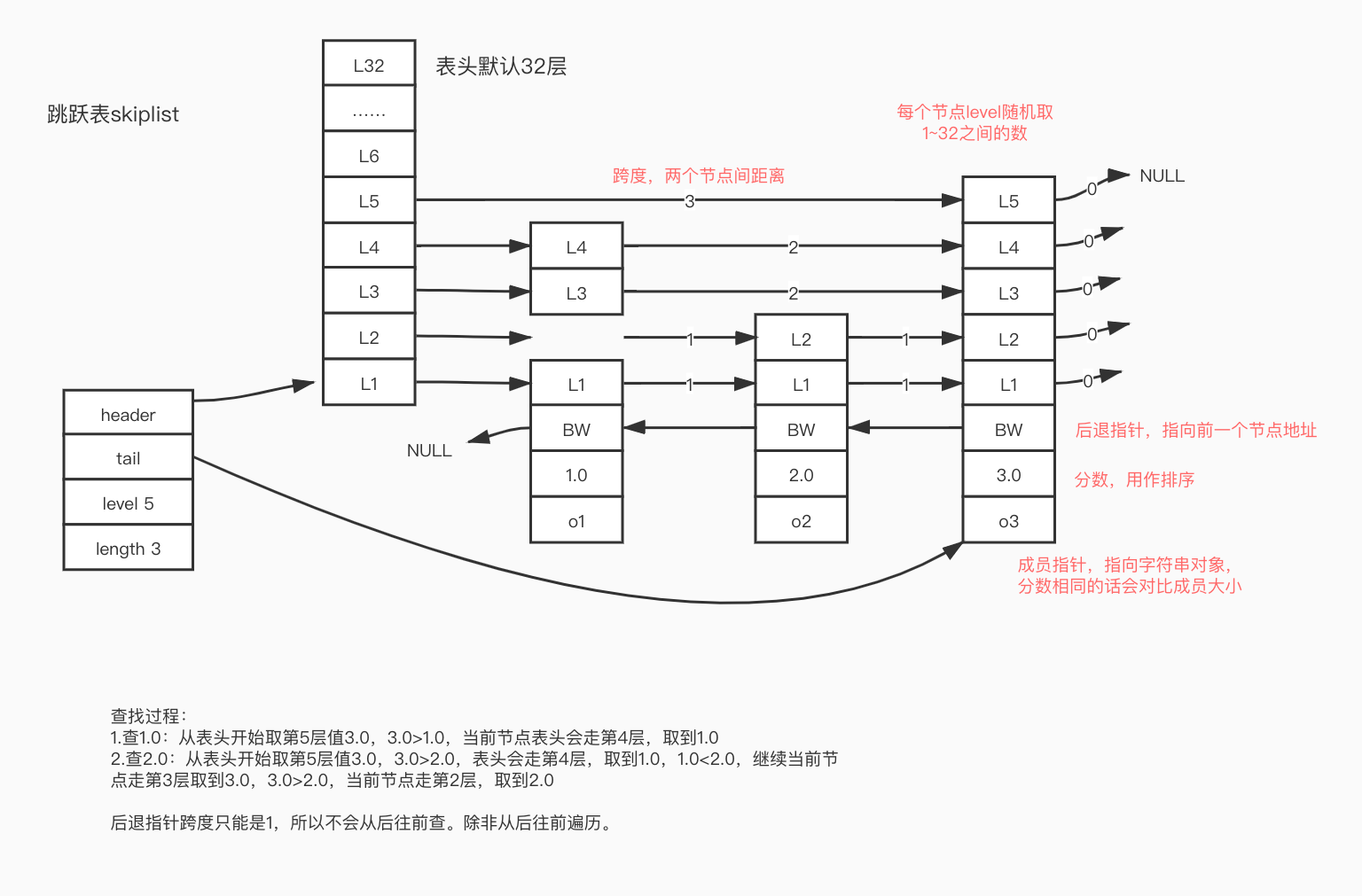
2. 跳跃表skiplist和字典(hashtable)共同实现
跳跃表存score-value对象,hashtable存value-score对象。目的是既可以O(1)复杂度根据对象查分数,又可以快速(O(logn)时间复杂度)根据分数区间查询对象。并且skiplist的score对象和value对象共享(两个指针指向同一对象),所以并不需要耗费过多的额外内存。
跳跃表
- 头节点不存数据,记录最高的层数level
- 每个节点的level随机,范围在1-32之间
- BW后退指针跨度1,正常查找不会用到BW指针,只会从前往后不会从后往前查找,如果发现后面节点已经大于目标值,则进入下一层后再往后查找。
结构如图:
5. set类型
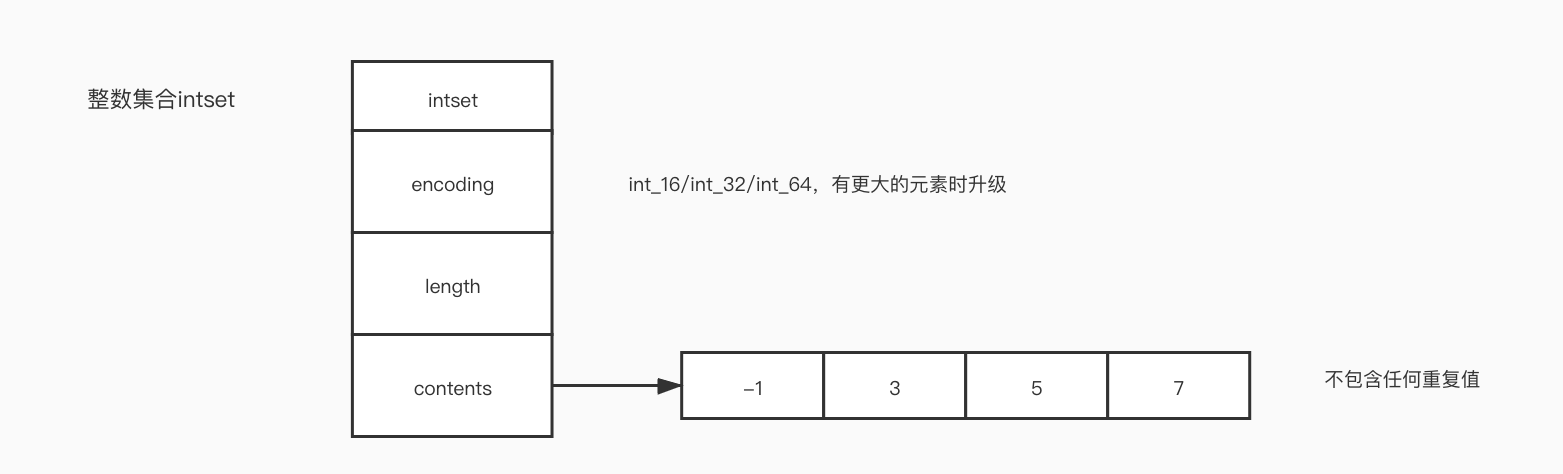
类似java的set去重无序集合。注意的是如果set中类型全部为整型的数据且数量小于等于512个,底层结构使用intset整数集合(有序、连续内存),操作比hashtable(字典类型,value为null)快
5.1 底层实现:intset或hashtable(hashtable见3.3)
intset结构
key过期
保存过期字典,过期字典键(key)是个指针指向某个键对象(数据库键对象),过期字典的值是一个long型,保存了键所指向的数据库键的过期时间,毫秒精度的UNIX时间戳。
expire操作往过期字典中添加对应key的数据。persist命令删除过期字典中的key对应数据。
过期删除策略:
- 定时删除,设置过期时间后,创建定时器timer,让定时器在键过期时间来临时删除键
- 惰性删除,过期不管,在每次从键空间获取键时检查是否过期,过期的话删除
- 定期删除,定时事件检过期字典删除过期的key删除,默认是100毫秒一次,一次检查100个键,如果过期比例高则再检查100个。
Jedis的pipline管道使用
开启pipline之后,一连串操作执行不会马上返回结果,在结束前获取结果时所有操作结果一同返回。为了一个连接执行多条命令,非原子性操作。














 695
695











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









