







Anaconda
开源的Python发行版本,其包含了conda、Python等180多个科学包及其依赖项
官网:https://www.anaconda.com
jupyter notebook
可视化网页开发工具
安装:
anacond自带或使用pip install jupyter notebook安装
启动:
命令行jupyter notebook
基础
数据类型
- int
- float
- bool True False
- 空值 None
- 字符串 str
- list列表可以变 [1,2,3]
- 元组tuple不可变 (1,2,3)
- 字段dict:
{"name":"xiao","age":10} - 集合set:set([1,2,3])
语法
除法运算符
"/"运算符
会得出小数
"//"整除运算符
向下取整
判断非空
if data is not None:
in / not in
list = [1,2,3]
a = 1
a in list 返回True
a not in list 返回False
or and not
#等价Java的& | !
a==b and a==c
a==b or a==c
not a==b
if elif else
python 中没有else if,只有elif
if a < 10:
b = 'small'
elif a < 20:
b = 'young'
else:
b = 'big'
print(b)
#简写
a = 3
b = 'big' if a > 2 else 'small'
print(b)
判断一个文件有没有其他进程占用
import os
resp = os.popen('fuser -f /tmp/file.txt','r')
print(len(resp.read()))
# 长度等于0则没有进程,否则有进程占用
平方 立方
i = 2
a=i**2
b=i**3
Range函数
range(100)会遍历0-99的数字
for i in range(100):
print(i)
range(2,5),会输出[2,3,4]
range(3,10,2),输出 [3,5,7,9],最后一个参数是步长
any函数
列表(list/set)中任意一个元素是True,返回True
pwd = 'asdd12a'
have_num = any(i.isdigit() for i in pwd)
print(have_num)
round函数
round(数字,2)会给保留小数点后两位数字
while
idx = 0
while idx < 100:
print(idx)
idx += 1
row-string
字符串前加r表示row-string,字符串中的反斜线\将会是正常字符而不是转义符
正则表达式
简单规则
1. []中的字符是可选择性的,+代表一个或多个,.代表任意字符,用\.代表.,{2,4}代表限制2-4个
2. ()代表分组,在re.sub的第二个参数,用\1和\2可以引用前面的两个分组
3. ^开始符号,$结束符号,有开始和结束符不会匹配到多余的字符串
re.match会给字符串匹配模式,匹配成功返回Match对象,不成功返回None
import re
datestr = "2022-06-28"
result = re.match(r'\d{4}-\d{2}-\d{2}',datestr)
print(result is not None)
re.findall可以搜索文本中所有匹配的模式
#提取11位电话号
import re
strs = '友情的骄傲开发17612231234大幅18814567892'
resus = re.findall(r'1\d{10}',strs)
for res in resus:
print(res)
re.compiler提前编译正则表达式,后续可以多次使用,性能更好
import re
emails = ["嗯12345@qq.com","唐asdf12dsa#abc.com代","接口的python666@163.cn交付","发哦python-abc@163com及","看得见法py_ant-666@sina.net看到"]
patterns = re.compile(r"[a-zA-Z0-9_-]+@[a-zA-Z0-9]+\.[a-zA-Z]{2,4}")
results = patterns.findall("".join(emails))
print(results)
re.sub可以实现正则替换字符串
import re
content = r"这个商品很好,质量最好,用起来不错,并且价格最低,绝对物美价廉"
#使用|分隔可以同时匹配多个字符串
pattern = r"最好|最低|绝对"
print(re.sub(pattern,"***",content))
替换手机号中间4位
import re
strs = '友情的骄傲开发17612231234大幅18814567892'
pattern = r'(1\d{2})\d{4}(\d{4})'
resu = re.sub(pattern,r"\1****\2",strs)
print(resu)
#输出 友情的骄傲开发176****1234大幅188****7892
引号
单引号和双引号几乎等价。单引号中放双引号或者双引号中放单引号不用转义
三引号
三个双引号或者三个单引号,可以包含多行数据,并且里面可以随便包含双引号和单引号。
sql = """
select *
from table
where name like '%li%'
order by id desc
"""
print(sql)
字符串
获取子串
- 使用数字下标可以直接获取字符,“abc”[0] == “a”
- 数字下标可以从-1开始,代表字符串最后开始数,“abc”[-1] == “c”
- 使用切片获取子串
- str[2:4],获取2~4的子字符串,包括第2个元素,不包括第4个元素
- str[:4],获取从开头0到第4个元素的子串
- str[4:],获取从第4个元素到最后的子串
字符串格式化
- 使用加号拼接,“hello”+s
- 使用百分号格式化符号
s = "buy %s,count=%d,price=%f"%("apple",10,1.5)
print(s)
%s 字符串
%d 整型数字
%f 浮点型数字
结果:
buy apple,count=10,price=1.500000
- format函数,键值对方式更直观
s = "{vara} and {varb}".format(vara="liming",varb="xiaomei")
print(s)
结果:
liming and xiaomei
- join函数
l = ['1','2','3']
s = "aa".join(l)
print(s)
#l集合总必须是字符类型,否则无效
结果:
1aa2aa3
- py3.6新的format方法
name = "zhangli"
age = 18
s = f"名字{name},age is {age}"
#name、age是前面已经定义好的参数
结果:
名字zhangli,age is 18
字符串常用方法(函数)
- len(s),字符串长度
- str(12),把对象变成字符串,返回个字符串
- s.endswith(“.txt”),判断是否.txt结尾
- s.startswith(“test”),判断是否以test_开头
- s.replace(old,new),将s中旧字符串替换为新字符串
- s.split(“,”),使用字符串分隔另一个字符串得到一个list集合。re模块的split函数可以使用多个分隔符拆分字符串,例如
import re re.split(r",| ",s)用逗号和空格分隔,加的r写正则时更好用 - s.strip(),去除字符串两边的空格,文件读取行时可以去掉换行符
- s.isnumeric(),判断字符串是不是数字
字符串是否包含
s='nihao,shijie'
t='nihao'
result = t in s
print result
#打印True
import string
s='nihao,shijie'
t='nihao'
result = string.find(s,t)!=-1
print result
#打印True
字符串截取
str = ‘0123456789’
print str[0:3] #截取第一位到第三位的字符
print str[:] #截取字符串的全部字符
print str[6:] #截取第七个字符到结尾
print str[:-3] #截取从头开始到倒数第三个字符之前
print str[2] #截取第三个字符
print str[-1] #截取倒数第一个字符
print str[::-1] #创造一个与原字符串顺序相反的字符串
print str[-3:-1] #截取倒数第三位与倒数第一位之前的字符
print str[-3:] #截取倒数第三位到结尾
print str[:-5:-3] #逆序截取,具体啥意思没搞明白?
--------------------------------------
输出结果:
012
0123456789
6789
0123456
2
9
9876543210
78
789
96
字符串反转
s[::-1]
集合list
data = ['a','b','c','d']
data[0] == 'a'
data[-1] == 'd'
data[2:3] == 'c'
#list可以修改
data[2:4] = [1,2,3]
data变成['a','b',1,2,3]
常用方法
- list.append(item),在末尾新增一个元素
- list.extend(list),在末尾新增一个列表
- list+list,返回一个新的合并的list
- list.clear(),清空列表
- len(list),返回列表元素个数
- for i in list;print(i),按顺序遍历列表
- for idx,value in enumerate(list):print(idx,value),用下标和述职遍历列表
- for idx in range(len(list)):print(idx,list[idx),用下标和述职遍历列表
- list.sort(key=None,reverse=False),对list进行排序,key可以指定对象中子元素,reverse指定正序还是倒序,True表示倒序
- list.reverse(),翻转list自身
- max、min、sum可以统计list的结果:
max(list) - 根据字符串创建list
list("abcd")创建['a','b','c','d']的list集合
列表推导式
squares = [x*x for x in list if x%2==0]
表示遍历list集合,其中元素取模2为零(偶数),则把元素放到squares集合中
例子:
data = [1,2,3,4,5]
print("\t.join([str(i) for i in data])")
#集合中是字符才能使用join方法,列表推导式的if条件可以不加
data = [1,2,3,4,5]
list = [i for i in data if i%2==0]
print(list)
# 结果 2,4
列表排序
- list.sort(key=None,reverse=False)
- new_list = sorted(list,key=None,reverse=False)
不会改变原来list顺序,生成一个新list
lambda简化传参
上面排序方法key可以传一个函数
对学生按成绩排序(学号,成绩)
sgrades = [(1001, 89), (1002, 77), (1003, 99)]
sgrades.sort(key=lambda x: x[1],reverse=True)
print(sgrades)
zip函数,可以将多个序列打包到一起,返回一个元组
l1 = [1,2,3]
l2 = [4,5,6]
for i,j in zip(l1,l2):
print(i+j)
# 结果打印
5
7
9
元组Tuple
元组相比列表list,不能改变元素值。比较安全,不担心被修改。
元组存异质元素,list存同质元素。即用元组存不同类型的数据,list存相同类型元素。
创建
tup = (1001,1002)
tup = 1001,1002 #括号省略
tup = ()
tup = (1001,) #单元素元组必须加上逗号
常用方法
大多数和列表list相同。
- tuple(list),将列表变为元组
- x,y,x=tuple,将tuple的元素挨个拆包赋值给x y z
字典dict
创建方式
key value结构
dict = {key1:val1,key2:value2}
#key必须是不可变的,如数字、字符串、元组,不能是可变的列表
获取数据
dict = {"id":1,"name":"zhang"}
print(dict["id"])
print(dict["name"])
# 如果key不存在会报错。
常用方法
- len(dict),key的个数
- str(dict),字典的字符串形式
- type(dict),字典类型,输出dict
- dict.clear(),清空
- dict.get(key,defaule),获取key的内容,如果key不存在,返回默认值default
- key in dict,判断key是否在dict的键中
- dict1.update(dict2),将dict2的所有键值对更新到dict1中
- {x:x*x for x in range(10)},字典推导式
- dict.items(),以列表返回可遍历的(键,值)元组数组,常常用于for遍历
dict = {"id": 1, "name": "zhang"}
for a,b in dict.items():
print(a,b)
- dict.keys(),列表返回字典所有键
- dict.values(),列表返回字段所有值
Set集合
创建
s = set()
s = {1,2,3}
s = set([1,2,3]) #参数可以是列表、元组、字符串(把里面字符变成集合元素)
常用方法
- len(set),集合元素个数
- for x in set ,集合遍历
- set.add(key),新增
- set.remove(key)
- set.clear()
- x in set,判断元素是否在集合中
- s1 & s2 或者 s1.intersection(s2),求两个集合的交集
- s1 | s2 或者 s1.union(s2),求两个集合的并集
- s1 - s2 或者s1.difference(s2),求两个集合的差集
- s1.update(s2),将s2所有key更新到s1中。
- 集合推导式:s = {x for x in ‘abcd’ if x not in ‘bc’}
Self
self作用是在方法(函数)中引用类对象
参数是否为指定类型
if isinstance(jsons, dict):
isinstance函数是Python的内部函数,他的作用是判断jsons这个参数是否为dict类型
*参数
https://blog.csdn.net/zkk9527/article/details/88675129
查看对象类型type函数
data = [1,2]
type(data)
#结果
<class 'list'>
类型转换
将返回值用类型名
list = getname()
强转 string->int
nu = "1"
int(nu)
文件读取
fin = open("./input.txt")
for line in fin:
#strip()可以去掉每行后的换行符,int()强转成int类型
number = int(line.strip())
print(number)
fin.close()
不用自己关闭流的方式
with open("./input.txt") as fin:
for line in fin:
number = int(line.strip())
print(number)
os.walk可以递归扫描目录
os.path.join可以拼接一个目录和一个文件名,得到一个结果路径
import os
dir = r"D:\tmp\zookeeper"
for root,dirs,files in os.walk(dir):
'''
os.walk会递归扫描所有目录
root表示当前目录
dirs表示root下的子目录名列表
files表示root下的文件名列表
os.path.join可以拼接一个目录和一个文件名,得到一个结果路径
'''
print("root:",root)
print("dirs:",dirs)
for file in files:
fpath = os.path.join(root,file)
print(fpath)
统计每个Python文件行数
dir = r"D:\work\workspace_python"
for root, dirs, files in os.walk(dir):
for file in files:
if file.endswith('.py'):
fpath = os.path.join(root,file)
with open(fpath,encoding="utf8") as fin:
print(fpath,len(fin.readlines()))
自动整理文件夹
将目录下文件按扩展名分类移动到各扩展名下的文件夹中
import shutil
import os
dir = r"D:\tmp\tmp"
# os.listdir列出目录下所有子目录和文件
for file in os.listdir(dir):
splits = os.path.splitext(file)
# splits,以file=1.mp3为例,splits=['1','.mp3']
print(splits)
ext = splits[1]
#去掉.
ext = ext[1:]
if not os.path.isdir(f"{dir}/{file}"):
#创建文件夹
os.mkdir(f"{dir}/{ext}")
sourcePath = f"{dir}/{file}"
targetPath = f"{dir}/{ext}/{file}"
#移动文件
shutil.move(sourcePath,targetPath)
自动压缩文件
zipfile模块
以~$字符串开头的是临时文件,可忽略
import zipfile
dir = r"D:\tmp\tmp"
output_name = f"{dir}.zip"
#获取父目录
parent_name = os.path.dirname(dir)
zip = zipfile.ZipFile(output_name,"w",zipfile.ZIP_DEFLATED)
for root,dirs,files in os.walk(dir):
for file in files:
#过滤临时文件
if str(file).startswith("~$"):
continue
filepath = os.path.join(root,file)
#取文件相对路径,写进压缩包时写相对路径
writepath = os.path.relpath(filepath,parent_name)
zip.write(filepath,writepath)
zip.close()
Requests模块
1.获取网页内容
import requests
url = "http://www.baidu.com"
r = requests.get(url)
"""
post方法请求
request.post(
'http://xxx.com/postMethod',
data={'key':'value'}
)
"""
if r.status_code == 200:
print(r.text)
else:
print("error",r.status_code)
2. 下载url的图片
def downloadImage():
url = r"http://image.suifengxing.cn/classloader.jpg"
r = requests.get(url)
#wb 写入byte文件
with open(r"D:\tmp\classloader.jpg","wb") as f:
#r.content二进制形式
f.write(r.content)
3. 附带cookies
cookies = {
"key1":"value1",
"key2":"value2"
}
r = requests.get(
"http://xxx",
"cookies"=cookies
)
webbrowser模块
webbrowser.open(url)可以直接在浏览器打开一个url
import webbrowser
def baiduSearch(wd):
url = r"https://www.baidu.com/s?wd="
webbrowser.open(url+wd)
glob模块
glob.glob("p054/*.txt")可以匹配p054目录下符合规则得所有文件列表,*号通配符
变量
全局变量要在函数中更改必须加上global关键字
函数
函数传参
- 函数name=value格式传参顺序可变,如果普通传参,顺序不可变
- 函数传参可以定义默认值
def func(a,b,c=11):
函数返回值
- 使用return返回结果
- 可以使用逗号分隔返回多个值,调用时拆包获取各值
lambda函数
定义形式
lambda 参数:操作(参数)
# 定义
sum = lambda x,y: x+y
# 调用
sum(1,2)
查看模块的所有方法和某个方法的注释
dir和help
import math
print(dir(math))
print(help(math.cos))
类
自定义
# 类名驼峰形式,首字符大写
class Student:
"""类注释"""
# 类变量
total_cnt = 0
def __init__(self,name,age):
"""初始化方法"""
# 普通实例变量,每个实例独有
self.name = name
self.age = age
Student.total_cnt += 1
def set_grade(self,grade):
"""普通方法"""
self.grade = grade
使用
s1 = Student("zhang",20)
s2 = Student("li",25)
#访问类属性
print(Student.total_cnt)
#访问实例属性
print(s1.name,s1.age)
#调用实例方法
s1.set_grade(100)
模块
包package下的.py结尾的文件
__init__.py用于区分普通目录和package包
引入模块
import module1,module2
# 从包中引入模块
from pkg1.pkg2 import module3
# 从模块中引入函数/类
from pkg1.pkg2.module3 import func/class
模块引入时,先找当前目录,找不到去PYTHONPATH中路径列表中找。
如何引入自己的模块
把自己模块路径写入Pythonpath中
- 在.bash_profile环境变量中写PYTHONPATH=“目录”
- 在Python代码开始,用sys.path.append(“目录”)添加
import sys
sys.path.append("目录")
__name__变量
- 默认该变量的值是当前module的名称
- 如果执行这个module,即将文件当脚本使用执行时,Python修改该值为
__main__。所以可以判断if __name__ == "__main__"时,执行测试代码,这样别人引用module不会执行,自己又可以测试。
Python常见模块
标准库(不用额外安装)
- Python解释器相关:sys
- 操作系统:os
- json加载生成:json
- 正则表达式:re
- 随机数:random
- 多线程:multiprocessing
常见开源模块(需要安装)
- 网页爬取:scrapy、requests、BeautifulSoup
- Web服务:django、flask
- 数据库:PyMySQL、redis
- Excel读写:xlrd、xlwt
- 大数据:PySpark
- 数据计算:numpy。scipy
- 图表展示:matplotlib
- 机器学习:scikit-learn
- 深度学习:百度PaddlePaddle、谷歌TensorFlow
安装
pip3 install requests或python3.9 -m pip install requests- 使用Anaconda包,预先集成包括了数据科学的几乎所有开源包,解决了很多版本冲突问题
OS模块常用函数

multiprocessing多线程模块
import multiprocessing
def process(d):
return d*d
if __name__ =="__main__":
#参数是使用cpu核数,不指定默认使用cpu全部核数
with multiprocessing.Pool(3) as pool:
results = pool.map(process,[1,2,3,4])
print(results)
json模块
d = {"id":1,"name":"2"}
# indent能让json缩进美观
json.dumps(d,indent=2))
时间模块
time模块
import time
# 每两秒打印一次hello,参数可以传小数,如0.5,定时器
while True:
print(:hello)
time.sleep(2)
import time
#打印当前时间戳
print(time.time())
#打印yyyy-MM-dd HH:mm:ss格式时间,具体Python格式参考 https://strftime.org/
print(time.strftime("%Y-%m-%d %H:%M:%S"))
时间戳变字符串
time.strftime('%Y%m%d', time.localtime(time.time()))
# 输出 20221129
datetime模块
from datetime import datetime
#打印yyyy-MM-dd HH:mm:ss格式时间,具体Python格式参考 https://strftime.org/
print(datetime.now().strftime("%Y-%m-%d %H:%M:%S"))
#打印当前时间年份
print(datetime.now().year)
#将字符串转为datetime格式数据
birthday = datetime.strptime("2022-05-14","%Y-%m-%d")
print(type(birthday))
print(birthday)
#日期格式数据可以直接加减
curr_date = datetime.now()
minus_date = curr_date - birthday
print(minus_date.days)
#一天前时间
yes_date = curr_date + datetime.timedelta(days=-1)
输出10天前的日期。这里直接import datetime,因为timedelta函数在顶层,参数days可以是正数、负数、0。正数表示查询以前的时间,负数表示查询未来的时间
import datetime
curr_date = datetime.datetime.now()
gap = datetime.timedelta(days=10)
pre = curr_date - gap
print(pre.strftime("%Y-%m-%d"))
日期字符串可以直接比较大小
begin_date = "2022-06-01"
end_date = "2022-06-02"
print(begin_date > end_date)
string模块
import string
#小写字符集合
print(string.ascii_lowercase)
#大写字符集合
print(string.ascii_uppercase)
#数字
print(string.digits)
#标点符号
print(string.punctuation)
random模块
import random
# 随机从序列中采样几个字符得到一个列表 random.dample
words = string.ascii_lowercase
# len得到len长度的随机字符列表
password = random.sample(words,len)
print("".join(password))
文件读写
#f.readlines()可以得到文件中所有行
with open("./input.txt","r",encoding="utf-8") as f:
nums = [num.strip() for num in f.readlines()]
print(nums)
#with后可以接多个open
with open('1.txt') as fin,open('2.txt') as out:
读zip压缩文件需要用 rb
with open('1.zip', 'rb') as fin:
pass空语句
pass什么都不干,跟没有代码一样的效果,显得专业
input输入
#input读取键盘输入的字符串,lower将字符变小写
word = input("enter your word:").lower()
print(word)
异常
异常捕获
try:
代码块
except KeyError as e:
print("KeyError异常",e)
except [Exception as e]:
#Exception可捕获所有异常
print("异常代码",e)
#可以自己抛出异常
raise Exception("主动抛出的异常")
finally:
#一般用于资源清理,如文件关闭
print("do something")
Python脚本传参
使用sys.argv传参数
sys.argv类型是list,命令行参数列表,list中第一个是脚本名称或路径,后面是命令行传的参数
uuid使用
uuid4是全随机的方法
import uuid
uid = str(uuid.uuid4())
#去掉-
suid = ''.join(uid.split('-'))
Redis操作
注意:json操作会有转义符问题
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import redis
import json
r = redis.Redis(host='172.0.0.1', port=6379, db=9, password='123456')
result = r.scan(count=100,cursor=0,match=None)
outputlist=["["]
count = 0
for i in range(len(result[1])):
key = result[1][i]
value = r.get(key)
outputlist.append("{")
outputlist.append("\"")
outputlist.append(key)
outputlist.append("\"")
outputlist.append(":")
outputlist.append(value)
outputlist.append("}")
outputlist.append(",")
outputlist.pop()
outputlist.append("]")
file = open("/Users/xdf/tmp/redisdata.json",mode="w+")
# file.write("".join(outputlist))
json.dump("".join(outputlist),file)
file.close()
#读取文件,解析json
file = open("/Users/xdf/tmp/redisdata.json",mode="r+")
# var = file.read()
# if isinstance(var,unicode):
# var = var.encode("utf-8")
# file.close()
# list = json.loads(var)
# for dict in list:
# print dict.keys()[0]
# print dict.get(dict.keys()[0])
var = json.load(file)
file.close()
print type(var)
if isinstance(var,unicode):
var = var.encode("utf-8")
print type(var)
print var
var2 = json.loads(var,encoding="utf-8")
print type(var2)
list = var2
for dict in list:
# print type(dict.get(dict.keys()[0]))
# print dict.get(dict.keys()[0])
print json.dumps(dict.get(dict.keys()[0]))
print type(json.dumps(dict.get(dict.keys()[0])))
dict1 = dict.get(dict.keys()[0])
# print dict1.keys()
print dict1.get("status")
print type(dict1.get("metaData"))
Mysql操作 pymysql

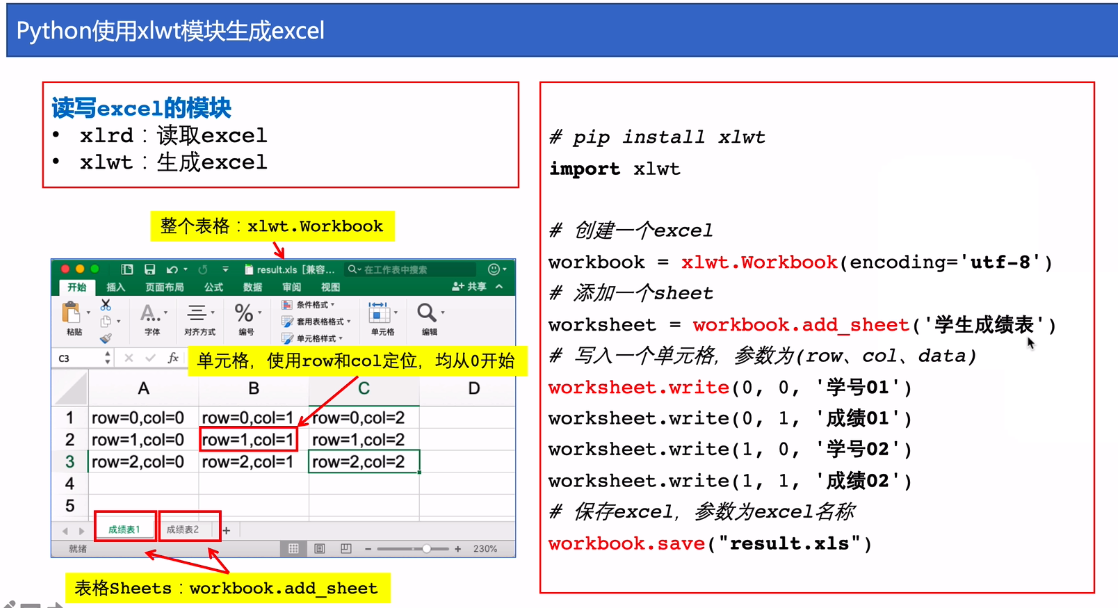
Python操作Excel
多线程并发
python慢的原因
- 边解释边运行
- GIL全局解释器锁,同一时间只能有一个线程运行并且多线程也不能使用多核cpu
ThreadPoolExcutor线程池
- map方法,批量提交,顺序返回
- submit方法,单独提交,返回无序
- as_completed:先执行完的任务先处理
with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor:
future_task_list = []
for file in self.file_list:
future_task = executor.submit(self.upload, file)
future_task_list.append(future_task)
for future in concurrent.futures.as_completed(future_task_list):
# wait for completed
future.result()
Lock锁
线程安全锁:
import threading import Lock
lock = Lock()
with lock:
# do something
进程安全锁:
import multiprocessing import Lock
lock = Lock()
with lock:
# do something
队列Queue
线程间:
import queue
q = quque.Queue()
q.put(item)
item = q.get()
进程间:
from multiprocessing import queue
q = quque.Queue()
q.put(item)
item = q.get()
subprocess使用非python进程执行命令
subprocess.Popen
import subprocess
# 打开个mp3(默认播放器):windows用start,并且shell=True、 mac用open、linux用see
proc = subprocess.Popen(
["start", r'./datas/123.mp3'],
shell=True
)
proc.communicate()
os.popen能执行shell命令(和os.system)
# fuser方式判断是否写完成,没有进程占用则已经写完
resp = os.popen(f"fuser -f {fpath}")
if len(resp.read()) == 0:
print("没有进程占用文件")
Python异步IO库 asyncio 协程操作
要用在异步IO编程中,依赖的库必须支持异步IO特性(支持await)。requests模块就不支持异步IO,发送网络请求需要使用aiohttp
协程:
就是在异步IO中执行的函数
import asyncio
# 要用在异步IO编程中,依赖的库必须支持异步IO特性。requests模块就不支持异步IO,发送网络请求需要使用aiohttp
def async_task_start():
urls = []
# 获取事件循环
loop = asyncio.get_event_loop()
# 创建task列表
tasks = [loop.create_task(get_url(url)) for url in urls]
# 执行爬虫事件列表
loop.run_until_complete(asyncio.wait(tasks))
# 异步爬取的协程(函数)
async def get_url(url):
"""
从url爬取信息,网络io操作
爬虫引用中requests不支持异步,需要使用aiohttp模块
:param url:
:return:
"""
# requests.get(url);
async with aiohttp.ClientSession() as session:
async with session.get(url) as resp:
result = await resp.text()
print(f"crow url:{url}, {len(result)}")
# 信号量
async def get_url_semaphore(url):
"""
""
信号量控制并发度。每次处理10个url
:param url:
:return:
"""
semaphore = asyncio.Semaphore(10)
async with semaphore:
async with aiohttp.ClientSession() as session:
async with session.get(url) as resp:
result = await resp.text()
print(f"crow url:{url}, {len(result)}")
Python异步IO库 Gevent
基于微线程Greenlet的并发框架,能够修改标准库里面大部分的阻塞式系统调用,变成协作式运行
和asyncio对比:
Gevent:
- 优点
- 只需要monkey.patch_all()就能自动修改阻塞为非阻塞,简单强大
- 缺点
- 不知道它具体patch了哪些库修改了哪些模块、类、函数。创造了“隐式的副作用”,如果出现问题很多时候极难调试。
Asyncio:
- 优点:明确使用asyncio、await关键字编程,直观易读
- 缺点:只支持很少的异步库,比如aiohttp















 5803
5803











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









