






!历史命令id 执行对应的指令
!! 执行上一次指令
正则:



grep -i "root" a.txt -c 从a.txt中统计root的字符串的次数
grep -En '\.$' luffy.txt 从a.txt中过滤以.结尾的行
cat -En a.txt 查看a.txt里面的内容以$结果,空行也是以$结尾
grep -E '[^0-5]' a.txt 从a.txt中查找除0到5的内容



sed -n '2,5p' luffycity.txt 打印第2到第5行
sed -n '2,+2p' luffycity.txt 打印第2行到后面加2行内容
sed -in '6,$d' luffycity.txt 将文件第6行到最后一行删除
sed -e 's/I/My/g' -re 's/[0-9]+/88888888/' luffycity.txt -e是可以连续处理,-r支持扩展正则,将I换成My,将一串数字换成88888888
sed -e 's/I/My/g' -re 's/[0-9]+/88888888/' luffycity.txt -i
sed '2a My linux is good' luffycity.txt 文件第2行后面加My linux is good
sed -i '4i My telephone is 0002315116' luffycity.txt 文件第4行前面插入My telephone is 0002315116
sed '3a I like girl\nI like pretty girl' luffycity.txt 文件第3行后加2行内容(\n为换行)
sed 'a -----------------------------' luffycity.txt 文件每一行后面加------------------------------------
ip a | sed -ne '/inet /p' | grep -Eo '[^a-z ]+' | sed '$d' | sed '1d' | sed '2d' 取ip
ifconfig eth0 | sed -ne '2p' | sed 's/^.*inet //'| sed 's/net.*$//' 取ip
ifconfig eth0 | sed -e '2s/^.*inet //' -e '2s/net.*$//p' -n 取ip,(2s表示第2行做替换操作)

awk 选项 '模式{动作}' 文件
awk '{print $1$2$5}' chaoge.txt 取3列
awk '{print $1,$2, $5}' chaoge.txt 取3列
awk '{print $NF}' chaoge.txt 取最后一列

 awk 'NR==2' a.txt 打印第2行
awk 'NR==2' a.txt 打印第2行
awk 'NR==2,NR==5' a.txt 打印第2到第5行
awk 'NR==5{print $2}' chaoge.txt 打印第5行的第2列的内容
awk 'NR==3,NR==6{print $2,$3}' chaoge.txt 打印第3到6行的第2和第3列
awk '{print NR,$0}' chaoge.txt 显示所有内容且输出行号
awk 'NR==3,NR==5{print NR,$0}' chaoge.txt 显示3到5行且输出内容及行号
awk '{print $1,$NF,$(NF-1),$(NF-2)}' chaoge.txt 打印第一列,最后一列,倒数第二第三列
ifconfig eth0 | awk 'NR==2{print $2}' 取ip

awk -F ':' -v OFS='===' '{print $1,$NF}' a.txt 以===代替,表示的空格分隔符输出

FNR 处理多个文件的时候 ,单独输出每个文件的行号,如下图:

awk -v RS=' ' '{print NR,$0}' chaoge.txt 输入读取的时候RS 将 空格作为换行
awk -v ORS='---超哥666---' '{print NR,$0}' chaoge.txt 输出打印的时候ORS将每行末尾的换行符用---超哥666---代替



awk 'BEGIN{print "超哥开始用awk了"}{print $0}' chaoge.txt BEGIN{print "超哥开始用awk了"}是模式,先做什么
结果:

awk 'BEGIN {print "超哥开始用awk了"}{print ARGV[0]$0}' chaoge.txt 数出记录的参数数组里第一个值,图示中的是参数数组里第一个值是awk
awk 'BEGIN {print "超哥开始用awk了"}{print ARGV[1]$0}' chaoge.txt 数出记录的参数数组里第一个值,图示中的是参数数组里第一个值是chaoge.txt

awk 'BEGIN{print "超哥开始用awk了"}{print ARGV[0],ARGV[1],ARGV[2]}' chaoge.txt
输出记录的参数组里面第一个,第二个参数,第三个参数,当前没有第三个参数。

awk 'BEGIN{print "超哥开始用awk了"}{print ARGV[0],ARGV[1],ARGV[2]}' chaoge.txt a.txt

awk -v myname='超哥' 'BEGIN{print "我的名字是: ",myname}' -v可以修改内置变更也可以定义一个自定义变量,当前是自定义一个内置变更,然后在BEGIN模式中用到打印出来
![]()
下图:在动作中用到自定义内置变更myname,则每一行都有 超哥 ,



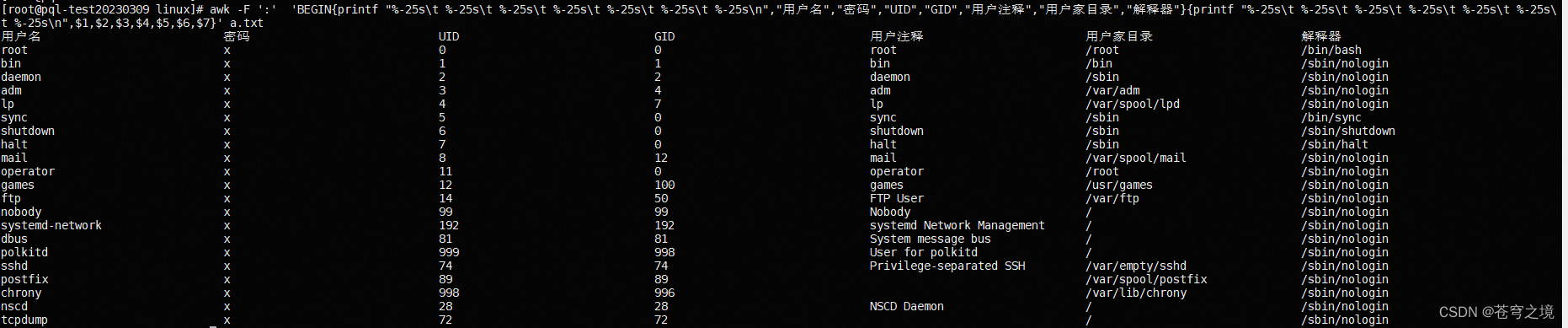
awk -F ':' 'BEGIN{printf "%-25s\t %-25s\t %-25s\t %-25s\t %-25s\t %-25s\t %-25s\n","用户名","密码","UID","GID","用户注释","用户家目录","解释器"}{printf "%-25s\t %-25s\t %-25s\t %-25s\t %-25s\t %-25s\t %-25s\n",$1,$2,$3,$4,$5,$6,$7}' a.txt


 awk 'BEGIN{print "awk执行之前打印的内容。。。"}NR==2{print $1}END{print "文本执行结束打印的内容"}' pyyu.txt
awk 'BEGIN{print "awk执行之前打印的内容。。。"}NR==2{print $1}END{print "文本执行结束打印的内容"}' pyyu.txt
awk 'BEGIN{print "awk执行之前打印的内容。。。"}NR<2{print $1}END{print "文本执行结束打印的内容"}' pyyu.txt

awk 'BEGIN{print "awk执行之前打印的内容。。。"}NF==5{print $1}END{print "文本执行结束打印的内容"}' chaoge.txt
打印有5列的相关行的第一列的内容






awk -F ':' '/^nscd/{print $1}' a.txt 从a文件找到nscd开头的行,然后打印符合条件的行的以:分割的第一列
awk '/\/sbin\/nologin/' a.txt 从a文件找到/sbin/nologin/的行,即是不能登录的用户信息
awk '/^operator/,/^chrony/{print NR,$0}' a.txt 从a文件找到以operator到以chrony开头的行,打印行号和每行全部内容

awk '{print $1}' access.log | sort -n | uniq -c | sort -nr | head -n 10 对access.log文件中的访问ip进行统计并排序去重,从大到小排序,统计前10















 28万+
28万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









